 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning on Non-iid Data via Local and Global Distillation
Jun 26, 2023



Most existing federated learning algorithms are based on the vanilla FedAvg scheme. However, with the increase of data complexity and the number of model parameters, the amount of communication traffic and the number of iteration rounds for training such algorithms increases significantly, especially in non-independently and homogeneously distributed scenarios, where they do not achieve satisfactory performance. In this work, we propose FedND: federated learning with noise distillation. The main idea is to use knowledge distillation to optimize the model training process. In the client, we propose a self-distillation method to train the local model. In the server, we generate noisy samples for each client and use them to distill other clients. Finally, the global model is obtained by the aggregation of local models. Experimental results show that the algorithm achieves the best performance and is more communication-efficient than state-of-the-art methods.
Shared MF: A privacy-preserving recommendation system
Aug 18, 2020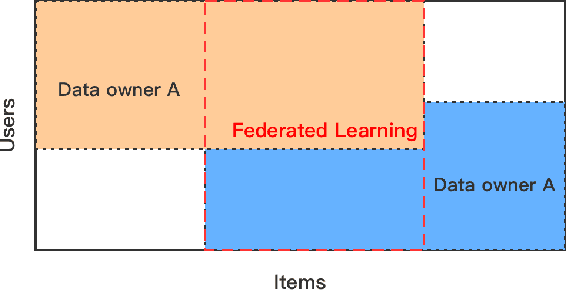

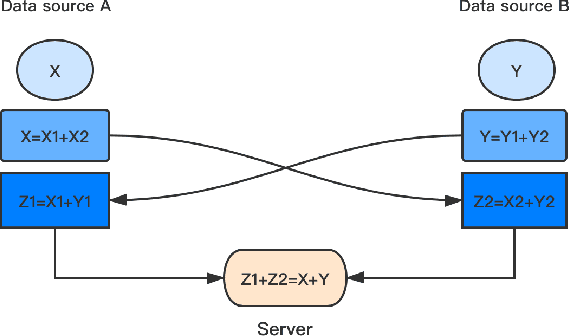

Matrix factorization is one of the most commonly used technologies in recommendation system. With the promotion of recommendation system in e-commerce shopping, online video and other aspects, distributed recommendation system has been widely promoted, and the privacy problem of multi-source data becomes more and more important. Based on Federated learning technology, this paper proposes a shared matrix factorization scheme called SharedMF. Firstly, a distributed recommendation system is built, and then secret sharing technology is used to protect the privacy of local data. Experimental results show that compared with the existing homomorphic encryption methods, our method can have faster execution speed without privacy disclosure, and can better adapt to recommendation scenarios with large amount of data.