 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sequential Recommendation for Long Term User Interest Via Personalization
Jan 07, 2026Recent years have witnessed success of sequential modeling, generative recommender, and large language model for recommendation. Though the scaling law has been validated for sequential models, it showed inefficiency in computational capacity when considering real-world applications like recommendation, due to the non-linear(quadratic) increasing nature of the transformer model. To improve the efficiency of the sequential model, we introduced a novel approach to sequential recommendation that leverages personalization techniques to enhance efficiency and performance. Our method compresses long user interaction histories into learnable tokens, which are then combined with recent interactions to generate recommendations. This approach significantly reduces computational costs while maintaining high recommendation accuracy. Our method could be applied to existing transformer based recommendation models, e.g., HSTU and HLLM. Extensive experiments on multiple sequential models demonstrate its versatility and effectiveness. Source code is available at \href{https://github.com/facebookresearch/PerSRec}{https://github.com/facebookresearch/PerSRec}.
Retrieval Augmentation via User Interest Clustering
Aug 07, 2024
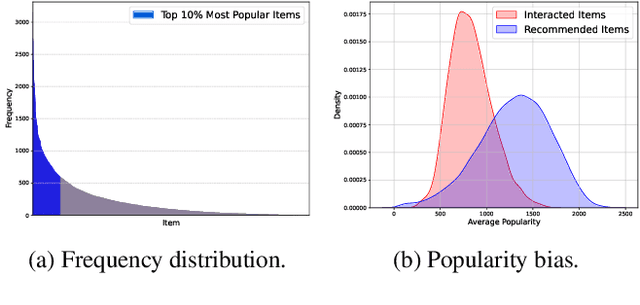
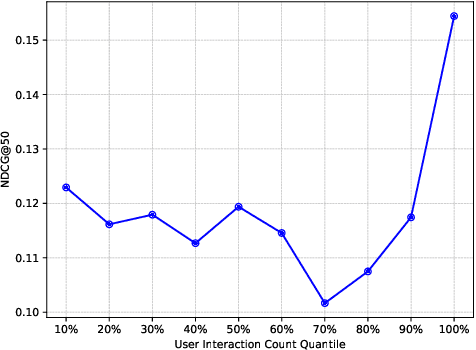

Many existing industrial recommender systems are sensitive to the patterns of user-item engagement. Light users, who interact less frequently, correspond to a data sparsity problem, making it difficult for the system to accurately learn and represent their preferences. On the other hand, heavy users with rich interaction history often demonstrate a variety of niche interests that are hard to be precisely captured under the standard "user-item" similarity measurement. Moreover, implementing these systems in an industrial environment necessitates that they are resource-efficient and scalable to process web-scale data under strict latency constraints. In this paper, we address these challenges by introducing an intermediate "interest" layer between users and items. We propose a novel approach that efficiently constructs user interest and facilitates low computational cost inference by clustering engagement graphs and incorporating user-interest attention. This method enhances the understanding of light users' preferences by linking them with heavy users. By integrating user-interest attention, our approach allows a more personalized similarity metric, adept at capturing the complex dynamics of user-item interactions. The use of interest as an intermediary layer fosters a balance between scalability and expressiveness in the model. Evaluations on two public datasets reveal that our method not only achieves improved recommendation performance but also demonstrates enhanced computational efficiency compared to item-level attention models. Our approach has also been deployed in multiple products at Meta, facilitating short-form video related recommendation.
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Apr 18, 2024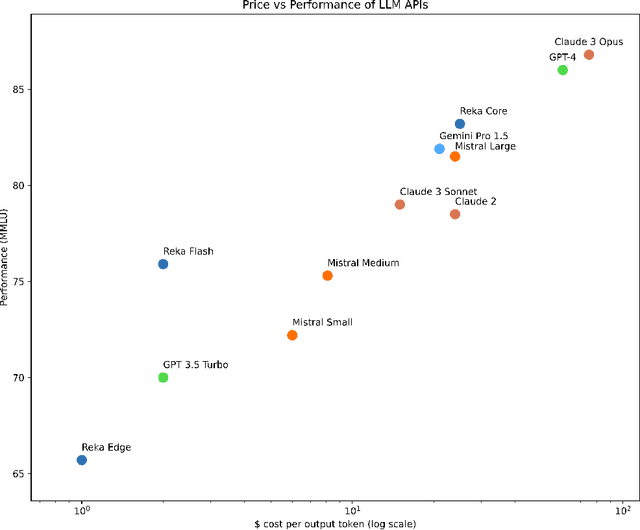


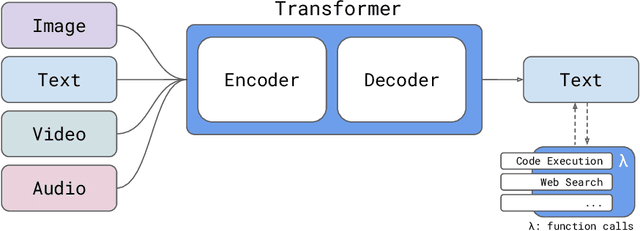
We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results. We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute class. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations. On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus. On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4-0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra. Models are shipped in production at http://chat.reka.ai . A showcase of non cherry picked qualitative examples can also be found at http://showcase.reka.ai .
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Aug 16, 2023



We investigate various prompting strategies for enhancing personalized recommendation performance with large language models (LLMs) through input augmentation. Our proposed approach, termed LLM-Rec, encompasses four distinct prompting strategies: (1) basic prompting, (2) recommendation-driven prompting, (3) engagement-guided prompting, and (4) recommendation-driven + engagement-guided prompting. Our empirical experiments show that incorporating the augmented input text generated by LLM leads to improved recommendation performance. Recommendation-driven and engagement-guided prompting strategies are found to elicit LLM's understanding of global and local item characteristics. This finding highlights the importance of leveraging diverse prompts and input augmentation techniques to enhance the recommendation capabilities with LLMs.
Decoupling the Depth and Scope of Graph Neural Networks
Jan 19, 2022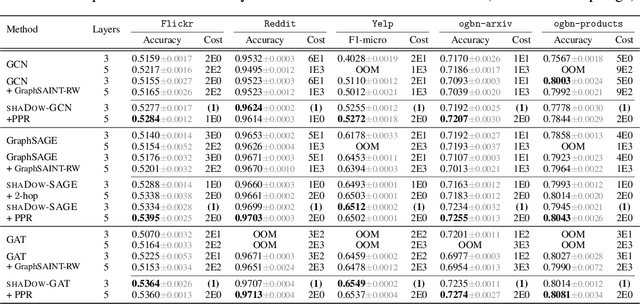
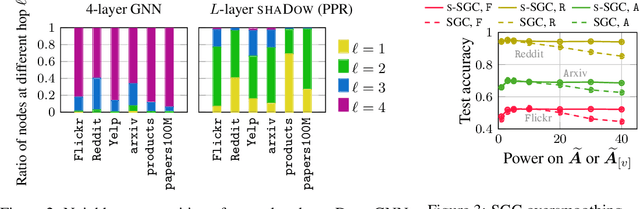
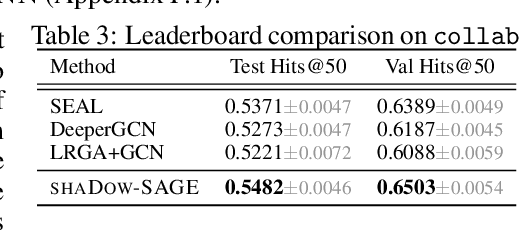
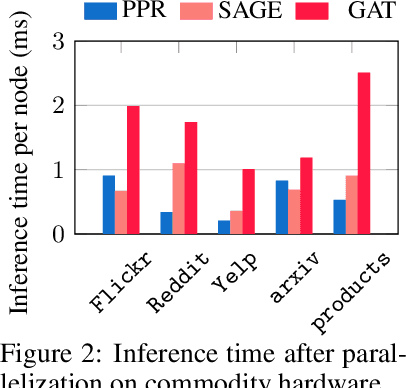
State-of-the-art Graph Neural Networks (GNNs) have limited scalability with respect to the graph and model sizes. On large graphs, increasing the model depth often means exponential expansion of the scope (i.e., receptive field). Beyond just a few layers, two fundamental challenges emerge: 1. degraded expressivity due to oversmoothing, and 2. expensive computation due to neighborhood explosion. We propose a design principle to decouple the depth and scope of GNNs -- to generate representation of a target entity (i.e., a node or an edge), we first extract a localized subgraph as the bounded-size scope, and then apply a GNN of arbitrary depth on top of the subgraph. A properly extracted subgraph consists of a small number of critical neighbors, while excluding irrelevant ones. The GNN, no matter how deep it is, smooths the local neighborhood into informative representation rather than oversmoothing the global graph into "white noise". Theoretically, decoupling improves the GNN expressive power from the perspectives of graph signal processing (GCN), function approximation (GraphSAGE) and topological learning (GIN). Empirically, on seven graphs (with up to 110M nodes) and six backbone GNN architectures, our design achieves significant accuracy improvement with orders of magnitude reduction in computation and hardware cost.
* Accepted to NeurIPS 2021
Deep Graph Neural Networks with Shallow Subgraph Samplers
Dec 02, 2020


While Graph Neural Networks (GNNs) are powerful models for learning representations on graphs, most state-of-the-art models do not have significant accuracy gain beyond two to three layers. Deep GNNs fundamentally need to address: 1). expressivity challenge due to oversmoothing, and 2). computation challenge due to neighborhood explosion. We propose a simple "deep GNN, shallow sampler" design principle to improve both the GNN accuracy and efficiency -- to generate representation of a target node, we use a deep GNN to pass messages only within a shallow, localized subgraph. A properly sampled subgraph may exclude irrelevant or even noisy nodes, and still preserve the critical neighbor features and graph structures. The deep GNN then smooths the informative local signals to enhance feature learning, rather than oversmoothing the global graph signals into just "white noise". We theoretically justify why the combination of deep GNNs with shallow samplers yields the best learning performance. We then propose various sampling algorithms and neural architecture extensions to achieve good empirical results. Experiments on five large graphs show that our models achieve significantly higher accuracy and efficiency, compared with state-of-the-art.
Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review
Apr 10, 2020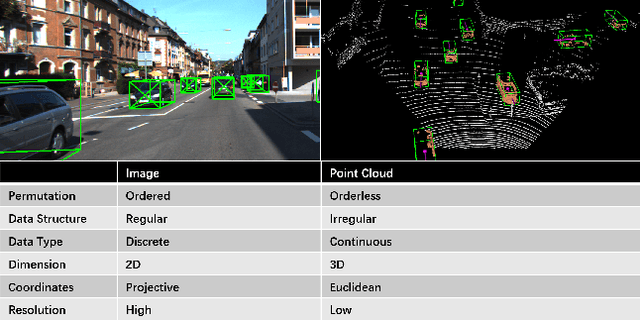
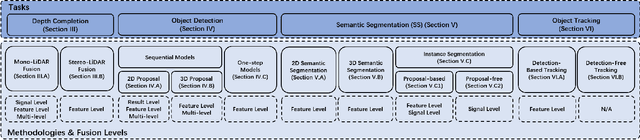
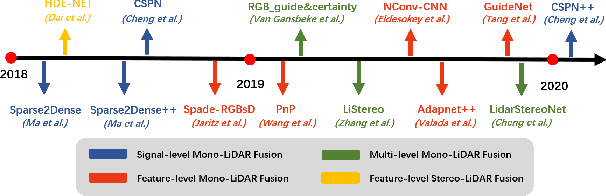
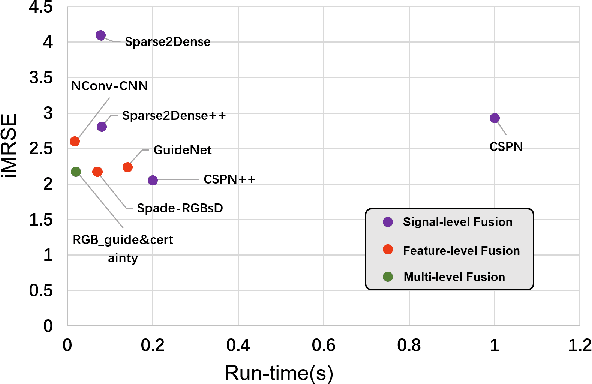
Autonomous vehicles are experiencing rapid development in the past few years. However, achieving full autonomy is not a trivial task, due to the nature of the complex and dynamic driving environment. Therefore, autonomous vehicles are equipped with a suite of different sensors to ensure robust, accurate environmental perception. In particular, camera-LiDAR fusion is becoming an emerging research theme. However, so far there is no critical review that focuses on deep-learning-based camera-LiDAR fusion methods. To bridge this gap and motivate future research, this paper devotes to review recent deep-learning-based data fusion approaches that leverage both image and point cloud. This review gives a brief overview of deep learning on image and point cloud data processing. Followed by in-depth reviews of camera-LiDAR fusion methods in depth completion, object detection, semantic segmentation and tracking, which are organized based on their respective fusion levels. Furthermore, we compare these methods on publicly available datasets. Finally, we identified gaps and over-looked challenges between current academic researches and real-world applications. Based on these observations, we provide our insights and point out promising research directions.