 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Real-Time Fast Unmanned Aerial Vehicle Detection Using Dynamic Vision Sensors
Mar 18, 2024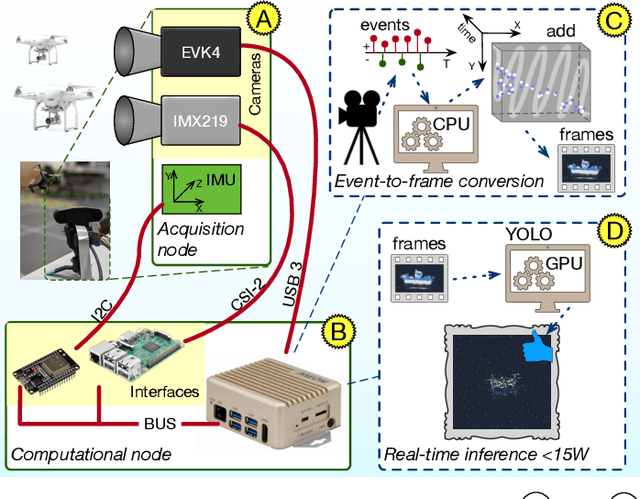



Unmanned Aerial Vehicles (UAVs) are gaining popularity in civil and military applications. However, uncontrolled access to restricted areas threatens privacy and security. Thus, prevention and detection of UAVs are pivotal to guarantee confidentiality and safety. Although active scanning, mainly based on radars, is one of the most accurate technologies, it can be expensive and less versatile than passive inspections, e.g., object recognition. Dynamic vision sensors (DVS) are bio-inspired event-based vision models that leverage timestamped pixel-level brightness changes in fast-moving scenes that adapt well to low-latency object detection. This paper presents F-UAV-D (Fast Unmanned Aerial Vehicle Detector), an embedded system that enables fast-moving drone detection. In particular, we propose a setup to exploit DVS as an alternative to RGB cameras in a real-time and low-power configuration. Our approach leverages the high-dynamic range (HDR) and background suppression of DVS and, when trained with various fast-moving drones, outperforms RGB input in suboptimal ambient conditions such as low illumination and fast-moving scenes. Our results show that F-UAV-D can (i) detect drones by using less than <15 W on average and (ii) perform real-time inference (i.e., <50 ms) by leveraging the CPU and GPU nodes of our edge computer.
Automating Code-Related Tasks Through Transformers: The Impact of Pre-training
Feb 08, 2023



Transformers have gained popularity in the software engineering (SE) literature. These deep learning models are usually pre-trained through a self-supervised objective, meant to provide the model with basic knowledge about a language of interest (e.g., Java). A classic pre-training objective is the masked language model (MLM), in which a percentage of tokens from the input (e.g., a Java method) is masked, with the model in charge of predicting them. Once pre-trained, the model is then fine-tuned to support the specific downstream task of interest (e.g., code summarization). While there is evidence suggesting the boost in performance provided by pre-training, little is known about the impact of the specific pre-training objective(s) used. Indeed, MLM is just one of the possible pre-training objectives and recent work from the natural language processing field suggest that pre-training objectives tailored for the specific downstream task of interest may substantially boost the model's performance. In this study, we focus on the impact of pre-training objectives on the performance of transformers when automating code-related tasks. We start with a systematic literature review aimed at identifying the pre-training objectives used in SE. Then, we pre-train 32 transformers using both (i) generic pre-training objectives usually adopted in SE; and (ii) pre-training objectives tailored to specific code-related tasks subject of our experimentation, namely bug-fixing, code summarization, and code completion. We also compare the pre-trained models with non pre-trained ones. Our results show that: (i) pre-training helps in boosting performance only if the amount of fine-tuning data available is small; (ii) the MLM objective is usually sufficient to maximize the prediction performance of the model, even when comparing it with pre-training objectives specialized for the downstream task at hand.