 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Literature Review on the Use of Deep Learning in Software Engineering Research
Sep 14, 2020



An increasingly popular set of techniques adopted by software engineering (SE) researchers to automate development tasks are those rooted in the concept of Deep Learning (DL). The popularity of such techniques largely stems from their automated feature engineering capabilities, which aid in modeling software artifacts. However, due to the rapid pace at which DL techniques have been adopted, it is difficult to distill the current successes, failures, and opportunities of the current research landscape. In an effort to bring clarity to this cross-cutting area of work, from its modern inception to the present, this paper presents a systematic literature review of research at the intersection of SE & DL. The review canvases work appearing in the most prominent SE and DL conferences and journals and spans 84 papers across 22 unique SE tasks. We center our analysis around the components of learning, a set of principles that govern the application of machine learning techniques (ML) to a given problem domain, discussing several aspects of the surveyed work at a granular level. The end result of our analysis is a research roadmap that both delineates the foundations of DL techniques applied to SE research, and likely areas of fertile exploration for the future.
DeepMutation: A Neural Mutation Tool
Feb 13, 2020
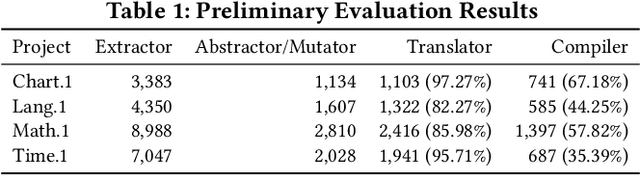

Mutation testing can be used to assess the fault-detection capabilities of a given test suite. To this aim, two characteristics of mutation testing frameworks are of paramount importance: (i) they should generate mutants that are representative of real faults; and (ii) they should provide a complete tool chain able to automatically generate, inject, and test the mutants. To address the first point, we recently proposed an approach using a Recurrent Neural Network Encoder-Decoder architecture to learn mutants from ~787k faults mined from real programs. The empirical evaluation of this approach confirmed its ability to generate mutants representative of real faults. In this paper, we address the second point, presenting DeepMutation, a tool wrapping our deep learning model into a fully automated tool chain able to generate, inject, and test mutants learned from real faults. Video: https://sites.google.com/view/learning-mutation/deepmutation
On Learning Meaningful Code Changes via Neural Machine Translation
Jan 25, 2019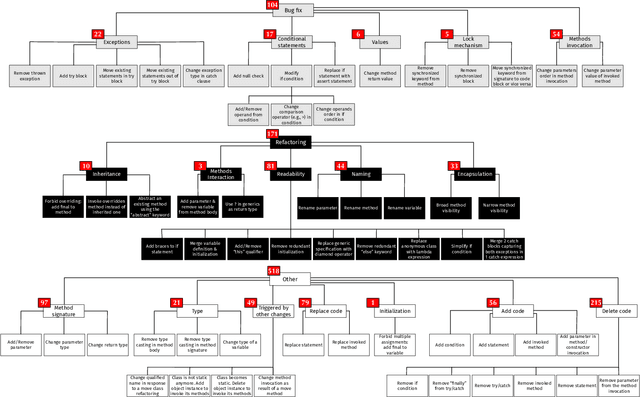
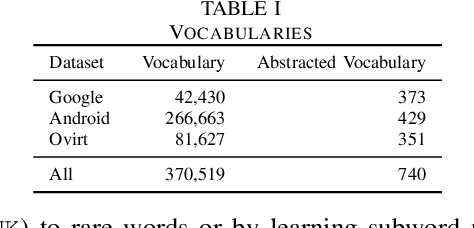
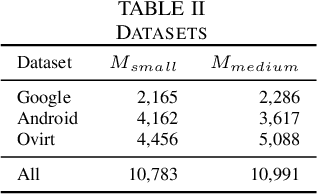
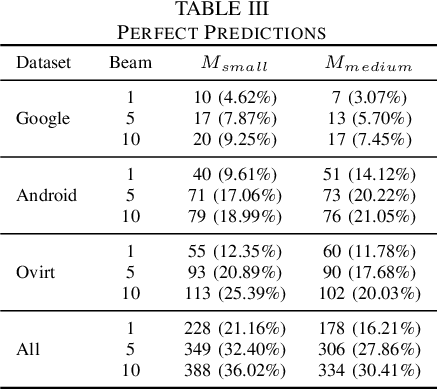
Recent years have seen the rise of Deep Learning (DL) techniques applied to source code. Researchers have exploited DL to automate several development and maintenance tasks, such as writing commit messages, generating comments and detecting vulnerabilities among others. One of the long lasting dreams of applying DL to source code is the possibility to automate non-trivial coding activities. While some steps in this direction have been taken (e.g., learning how to fix bugs), there is still a glaring lack of empirical evidence on the types of code changes that can be learned and automatically applied by DL. Our goal is to make this first important step by quantitatively and qualitatively investigating the ability of a Neural Machine Translation (NMT) model to learn how to automatically apply code changes implemented by developers during pull requests. We train and experiment with the NMT model on a set of 236k pairs of code components before and after the implementation of the changes provided in the pull requests. We show that, when applied in a narrow enough context (i.e., small/medium-sized pairs of methods before/after the pull request changes), NMT can automatically replicate the changes implemented by developers during pull requests in up to 36% of the cases. Moreover, our qualitative analysis shows that the model is capable of learning and replicating a wide variety of meaningful code changes, especially refactorings and bug-fixing activities. Our results pave the way for novel research in the area of DL on code, such as the automatic learning and applications of refactoring.