 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIVE-T: A Methodology for Discriminative and Representative Data Viz Item Selection for Literacy Construct and Assessment
Aug 06, 2025The underspecification of progressive levels of difficulty in measurement constructs design and assessment tests for data visualization literacy may hinder the expressivity of measurements in both test design and test reuse. To mitigate this problem, this paper proposes DRIVE-T (Discriminating and Representative Items for Validating Expressive Tests), a methodology designed to drive the construction and evaluation of assessment items. Given a data vizualization, DRIVE-T supports the identification of task-based items discriminability and representativeness for measuring levels of data visualization literacy. DRIVE-T consists of three steps: (1) tagging task-based items associated with a set of data vizualizations; (2) rating them by independent raters for their difficulty; (3) analysing raters' raw scores through a Many-Facet Rasch Measurement model. In this way, we can observe the emergence of difficulty levels of the measurement construct, derived from the discriminability and representativeness of task-based items for each data vizualization, ordered into Many-Facets construct levels. In this study, we show and apply each step of the methodology to an item bank, which models the difficulty levels of a measurement construct approximating a latent construct for data visualization literacy. This measurement construct is drawn from semiotics, i.e., based on the syntax, semantics and pragmatics knowledge that each data visualization may require to be mastered by people. The DRIVE-T methodology operationalises an inductive approach, observable in a post-design phase of the items preparation, for formative-style and practice-based measurement construct emergence. A pilot study with items selected through the application of DRIVE-T is also presented to test our approach.
$Classi
Jun 10, 2024
Quantum computing, albeit readily available as hardware or emulated on the cloud, is still far from being available in general regarding complex programming paradigms and learning curves. This vision paper introduces $Classi|Q\rangle$, a translation framework idea to bridge Classical and Quantum Computing by translating high-level programming languages, e.g., Python or C++, into a low-level language, e.g., Quantum Assembly. Our idea paper serves as a blueprint for ongoing efforts in quantum software engineering, offering a roadmap for further $Classi|Q\rangle$ development to meet the diverse needs of researchers and practitioners. $Classi|Q\rangle$ is designed to empower researchers and practitioners with no prior quantum experience to harness the potential of hybrid quantum computation. We also discuss future enhancements to $Classi|Q\rangle$, including support for additional quantum languages, improved optimization strategies, and integration with emerging quantum computing platforms.
On the Need of Removing Last Releases of Data When Using or Validating Defect Prediction Models
Mar 31, 2020



To develop and train defect prediction models, researchers rely on datasets in which a defect is attributed to an artifact, e.g., a class of a given release. However, the creation of such datasets is far from being perfect. It can happen that a defect is discovered several releases after its introduction: this phenomenon has been called "dormant defects". This means that, if we observe today the status of a class in its current version, it can be considered as defect-free while this is not the case. We call "snoring" the noise consisting of such classes, affected by dormant defects only. We conjecture that the presence of snoring negatively impacts the classifiers' accuracy and their evaluation. Moreover, earlier releases likely contain more snoring classes than older releases, thus, removing the most recent releases from a dataset could reduce the snoring effect and improve the accuracy of classifiers. In this paper we investigate the impact of the snoring noise on classifiers' accuracy and their evaluation, and the effectiveness of a possible countermeasure consisting in removing the last releases of data. We analyze the accuracy of 15 machine learning defect prediction classifiers on data from more than 4,000 bugs and 600 releases of 19 open source projects from the Apache ecosystem. Our results show that, on average across projects: (i) the presence of snoring decreases the recall of defect prediction classifiers; (ii) evaluations affected by snoring are likely unable to identify the best classifiers, and (iii) removing data from recent releases helps to significantly improve the accuracy of the classifiers. On summary, this paper provides insights on how to create a software defect dataset by mitigating the effect of snoring.
Optimizing Prediction Intervals by Tuning Random Forest via Meta-Validation
Jan 22, 2018

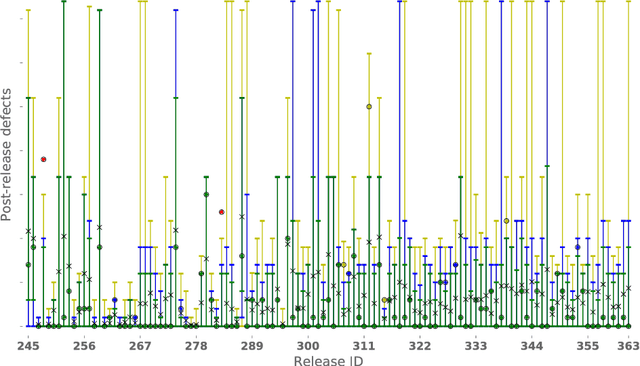

Recent studies have shown that tuning prediction models increases prediction accuracy and that Random Forest can be used to construct prediction intervals. However, to our best knowledge, no study has investigated the need to, and the manner in which one can, tune Random Forest for optimizing prediction intervals { this paper aims to fill this gap. We explore a tuning approach that combines an effectively exhaustive search with a validation technique on a single Random Forest parameter. This paper investigates which, out of eight validation techniques, are beneficial for tuning, i.e., which automatically choose a Random Forest configuration constructing prediction intervals that are reliable and with a smaller width than the default configuration. Additionally, we present and validate three meta-validation techniques to determine which are beneficial, i.e., those which automatically chose a beneficial validation technique. This study uses data from our industrial partner (Keymind Inc.) and the Tukutuku Research Project, related to post-release defect prediction and Web application effort estimation, respectively. Results from our study indicate that: i) the default configuration is frequently unreliable, ii) most of the validation techniques, including previously successfully adopted ones such as 50/50 holdout and bootstrap, are counterproductive in most of the cases, and iii) the 75/25 holdout meta-validation technique is always beneficial; i.e., it avoids the likely counterproductive effects of validation techniques.