 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Science of Causal Interpretability in Deep Learning for Software Engineering
May 21, 2025This dissertation addresses achieving causal interpretability in Deep Learning for Software Engineering (DL4SE). While Neural Code Models (NCMs) show strong performance in automating software tasks, their lack of transparency in causal relationships between inputs and outputs limits full understanding of their capabilities. To build trust in NCMs, researchers and practitioners must explain code predictions. Associational interpretability, which identifies correlations, is often insufficient for tasks requiring intervention and change analysis. To address this, the dissertation introduces DoCode, a novel post hoc interpretability method for NCMs. DoCode uses causal inference to provide programming language-oriented explanations of model predictions. It follows a four-step pipeline: modeling causal problems using Structural Causal Models (SCMs), identifying the causal estimand, estimating effects with metrics like Average Treatment Effect (ATE), and refuting effect estimates. Its framework is extensible, with an example that reduces spurious correlations by grounding explanations in programming language properties. A case study on deep code generation across interpretability scenarios and various deep learning architectures demonstrates DoCode's benefits. Results show NCMs' sensitivity to code syntax changes and their ability to learn certain programming concepts while minimizing confounding bias. The dissertation also examines associational interpretability as a foundation, analyzing software information's causal nature using tools like COMET and TraceXplainer for traceability. It highlights the need to identify code confounders and offers practical guidelines for applying causal interpretability to NCMs, contributing to more trustworthy AI in software engineering.
On Explaining (Large) Language Models For Code Using Global Code-Based Explanations
Mar 21, 2025In recent years, Language Models for Code (LLM4Code) have significantly changed the landscape of software engineering (SE) on downstream tasks, such as code generation, by making software development more efficient. Therefore, a growing interest has emerged in further evaluating these Language Models to homogenize the quality assessment of generated code. As the current evaluation process can significantly overreact on accuracy-based metrics, practitioners often seek methods to interpret LLM4Code outputs beyond canonical benchmarks. While the majority of research reports on code generation effectiveness in terms of expected ground truth, scant attention has been paid to LLMs' explanations. In essence, the decision-making process to generate code is hard to interpret. To bridge this evaluation gap, we introduce code rationales (Code$Q$), a technique with rigorous mathematical underpinning, to identify subsets of tokens that can explain individual code predictions. We conducted a thorough Exploratory Analysis to demonstrate the method's applicability and a User Study to understand the usability of code-based explanations. Our evaluation demonstrates that Code$Q$ is a powerful interpretability method to explain how (less) meaningful input concepts (i.e., natural language particle `at') highly impact output generation. Moreover, participants of this study highlighted Code$Q$'s ability to show a causal relationship between the input and output of the model with readable and informative explanations on code completion and test generation tasks. Additionally, Code$Q$ also helps to uncover model rationale, facilitating comparison with a human rationale to promote a fair level of trust and distrust in the model.
Mapping the Trust Terrain: LLMs in Software Engineering -- Insights and Perspectives
Mar 18, 2025



Applications of Large Language Models (LLMs) are rapidly growing in industry and academia for various software engineering (SE) tasks. As these models become more integral to critical processes, ensuring their reliability and trustworthiness becomes essential. Consequently, the concept of trust in these systems is becoming increasingly critical. Well-calibrated trust is important, as excessive trust can lead to security vulnerabilities, and risks, while insufficient trust can hinder innovation. However, the landscape of trust-related concepts in LLMs in SE is relatively unclear, with concepts such as trust, distrust, and trustworthiness lacking clear conceptualizations in the SE community. To bring clarity to the current research status and identify opportunities for future work, we conducted a comprehensive review of $88$ papers: a systematic literature review of $18$ papers focused on LLMs in SE, complemented by an analysis of 70 papers from broader trust literature. Additionally, we conducted a survey study with 25 domain experts to gain insights into practitioners' understanding of trust and identify gaps between existing literature and developers' perceptions. The result of our analysis serves as a roadmap that covers trust-related concepts in LLMs in SE and highlights areas for future exploration.
Toward Neurosymbolic Program Comprehension
Feb 03, 2025


Recent advancements in Large Language Models (LLMs) have paved the way for Large Code Models (LCMs), enabling automation in complex software engineering tasks, such as code generation, software testing, and program comprehension, among others. Tools like GitHub Copilot and ChatGPT have shown substantial benefits in supporting developers across various practices. However, the ambition to scale these models to trillion-parameter sizes, exemplified by GPT-4, poses significant challenges that limit the usage of Artificial Intelligence (AI)-based systems powered by large Deep Learning (DL) models. These include rising computational demands for training and deployment and issues related to trustworthiness, bias, and interpretability. Such factors can make managing these models impractical for many organizations, while their "black-box'' nature undermines key aspects, including transparency and accountability. In this paper, we question the prevailing assumption that increasing model parameters is always the optimal path forward, provided there is sufficient new data to learn additional patterns. In particular, we advocate for a Neurosymbolic research direction that combines the strengths of existing DL techniques (e.g., LLMs) with traditional symbolic methods--renowned for their reliability, speed, and determinism. To this end, we outline the core features and present preliminary results for our envisioned approach, aimed at establishing the first Neurosymbolic Program Comprehension (NsPC) framework to aid in identifying defective code components.
How Propense Are Large Language Models at Producing Code Smells? A Benchmarking Study
Dec 25, 2024



Large Language Models (LLMs) have shown significant potential in automating software engineering tasks, particularly in code generation. However, current evaluation benchmarks, which primarily focus on accuracy, fall short in assessing the quality of the code generated by these models, specifically their tendency to produce code smells. To address this limitation, we introduce CodeSmellEval, a benchmark designed to evaluate the propensity of LLMs for generating code smells. Our benchmark includes a novel metric: Propensity Smelly Score (PSC), and a curated dataset of method-level code smells: CodeSmellData. To demonstrate the use of CodeSmellEval, we conducted a case study with two state-of-the-art LLMs, CodeLlama and Mistral. The results reveal that both models tend to generate code smells, such as simplifiable-condition and consider-merging-isinstance. These findings highlight the effectiveness of our benchmark in evaluating LLMs, providing valuable insights into their reliability and their propensity to introduce code smells in code generation tasks.
On Interpreting the Effectiveness of Unsupervised Software Traceability with Information Theory
Dec 06, 2024



Traceability is a cornerstone of modern software development, ensuring system reliability and facilitating software maintenance. While unsupervised techniques leveraging Information Retrieval (IR) and Machine Learning (ML) methods have been widely used for predicting trace links, their effectiveness remains underexplored. In particular, these techniques often assume traceability patterns are present within textual data - a premise that may not hold universally. Moreover, standard evaluation metrics such as precision, recall, accuracy, or F1 measure can misrepresent the model performance when underlying data distributions are not properly analyzed. Given that automated traceability techniques tend to struggle to establish links, we need further insight into the information limits related to traceability artifacts. In this paper, we propose an approach, TraceXplainer, for using information theory metrics to evaluate and better understand the performance (limits) of unsupervised traceability techniques. Specifically, we introduce self-information, cross-entropy, and mutual information (MI) as metrics to measure the informativeness and reliability of traceability links. Through a comprehensive replication and analysis of well-studied datasets and techniques, we investigate the effectiveness of unsupervised techniques that predict traceability links using IR/ML. This application of TraceXplainer illustrates an imbalance in typical traceability datasets where the source code has on average 1.48 more information bits (i.e., entropy) than the linked documentation. Additionally, we demonstrate that an average MI of 4.81 bits, loss of 1.75, and noise of 0.28 bits signify that there are information-theoretic limits on the effectiveness of unsupervised traceability techniques. We hope these findings spur additional research on understanding the limits and progress of traceability research.
Towards More Trustworthy and Interpretable LLMs for Code through Syntax-Grounded Explanations
Jul 12, 2024



Trustworthiness and interpretability are inextricably linked concepts for LLMs. The more interpretable an LLM is, the more trustworthy it becomes. However, current techniques for interpreting LLMs when applied to code-related tasks largely focus on accuracy measurements, measures of how models react to change, or individual task performance instead of the fine-grained explanations needed at prediction time for greater interpretability, and hence trust. To improve upon this status quo, this paper introduces ASTrust, an interpretability method for LLMs of code that generates explanations grounded in the relationship between model confidence and syntactic structures of programming languages. ASTrust explains generated code in the context of syntax categories based on Abstract Syntax Trees and aids practitioners in understanding model predictions at both local (individual code snippets) and global (larger datasets of code) levels. By distributing and assigning model confidence scores to well-known syntactic structures that exist within ASTs, our approach moves beyond prior techniques that perform token-level confidence mapping by offering a view of model confidence that directly aligns with programming language concepts with which developers are familiar. To put ASTrust into practice, we developed an automated visualization that illustrates the aggregated model confidence scores superimposed on sequence, heat-map, and graph-based visuals of syntactic structures from ASTs. We examine both the practical benefit that ASTrust can provide through a data science study on 12 popular LLMs on a curated set of GitHub repos and the usefulness of ASTrust through a human study.
Benchmarking Causal Study to Interpret Large Language Models for Source Code
Aug 23, 2023



One of the most common solutions adopted by software researchers to address code generation is by training Large Language Models (LLMs) on massive amounts of source code. Although a number of studies have shown that LLMs have been effectively evaluated on popular accuracy metrics (e.g., BLEU, CodeBleu), previous research has largely overlooked the role of Causal Inference as a fundamental component of the interpretability of LLMs' performance. Existing benchmarks and datasets are meant to highlight the difference between the expected and the generated outcome, but do not take into account confounding variables (e.g., lines of code, prompt size) that equally influence the accuracy metrics. The fact remains that, when dealing with generative software tasks by LLMs, no benchmark is available to tell researchers how to quantify neither the causal effect of SE-based treatments nor the correlation of confounders to the model's performance. In an effort to bring statistical rigor to the evaluation of LLMs, this paper introduces a benchmarking strategy named Galeras comprised of curated testbeds for three SE tasks (i.e., code completion, code summarization, and commit generation) to help aid the interpretation of LLMs' performance. We illustrate the insights of our benchmarking strategy by conducting a case study on the performance of ChatGPT under distinct prompt engineering methods. The results of the case study demonstrate the positive causal influence of prompt semantics on ChatGPT's generative performance by an average treatment effect of $\approx 3\%$. Moreover, it was found that confounders such as prompt size are highly correlated with accuracy metrics ($\approx 0.412\%$). The end result of our case study is to showcase causal inference evaluations, in practice, to reduce confounding bias. By reducing the bias, we offer an interpretable solution for the accuracy metric under analysis.
Toward a Theory of Causation for Interpreting Neural Code Models
Feb 07, 2023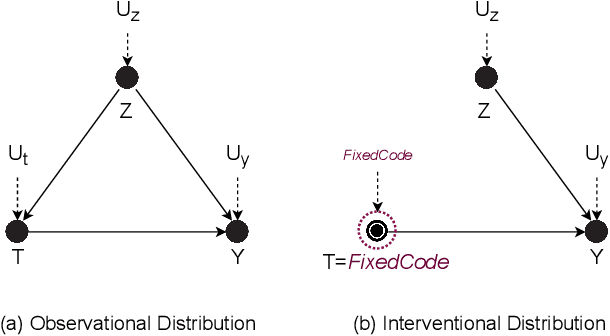
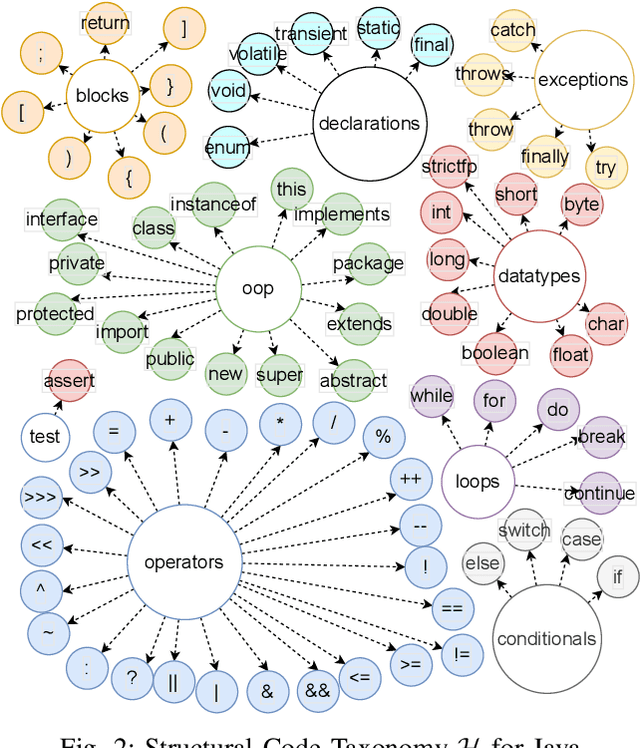
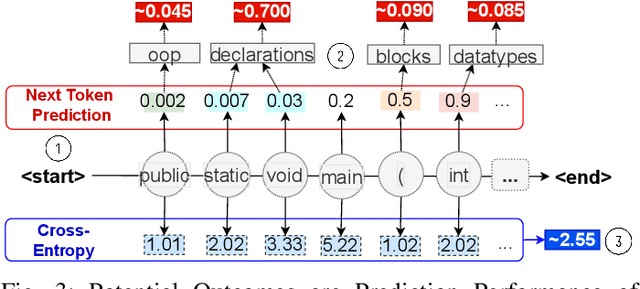
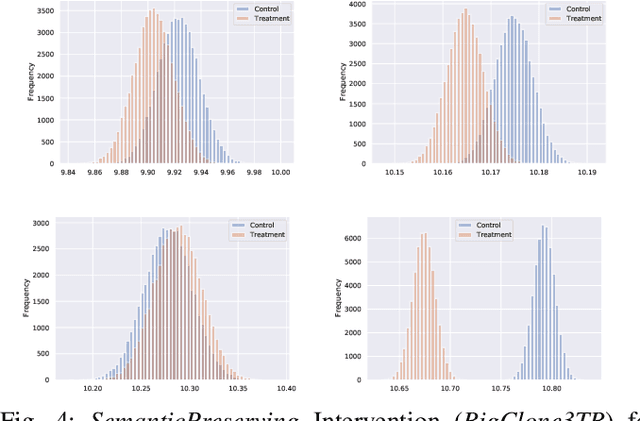
Neural Language Models of Code, or Neural Code Models (NCMs), are rapidly progressing from research prototypes to commercial developer tools. As such, understanding the capabilities and limitations of such models is becoming critical. However, the abilities of these models are typically measured using automated metrics that often only reveal a portion of their real-world performance. While, in general, the performance of NCMs appears promising, currently much is unknown about how such models arrive at decisions. To this end, this paper introduces $do_{code}$, a post-hoc interpretability methodology specific to NCMs that is capable of explaining model predictions. $do_{code}$ is based upon causal inference to enable programming language-oriented explanations. While the theoretical underpinnings of $do_{code}$ are extensible to exploring different model properties, we provide a concrete instantiation that aims to mitigate the impact of spurious correlations by grounding explanations of model behavior in properties of programming languages. To demonstrate the practical benefit of $do_{code}$, we illustrate the insights that our framework can provide by performing a case study on two popular deep learning architectures and nine NCMs. The results of this case study illustrate that our studied NCMs are sensitive to changes in code syntax and statistically learn to predict tokens related to blocks of code (e.g., brackets, parenthesis, semicolon) with less confounding bias as compared to other programming language constructs. These insights demonstrate the potential of $do_{code}$ as a useful model debugging mechanism that may aid in discovering biases and limitations in NCMs.
Improving the Effectiveness of Traceability Link Recovery using Hierarchical Bayesian Networks
May 18, 2020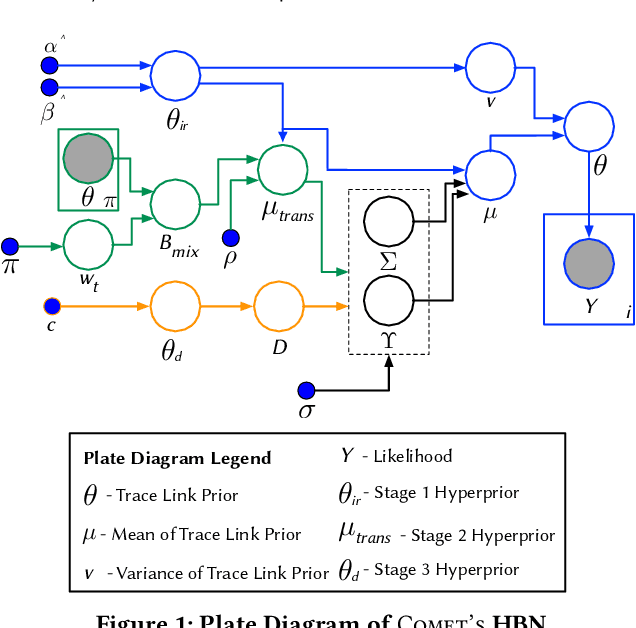
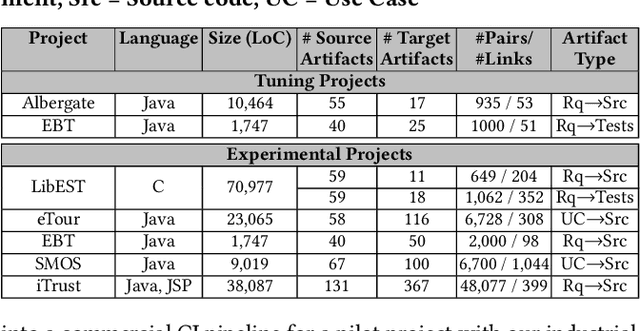
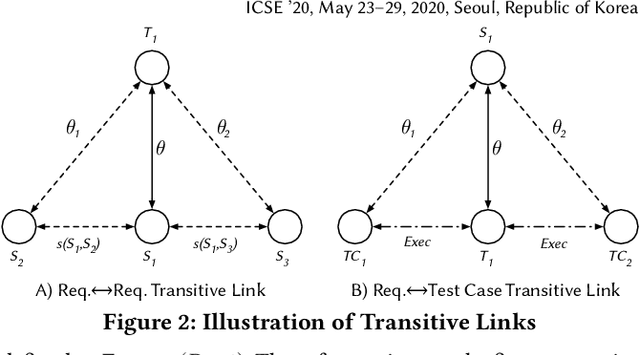
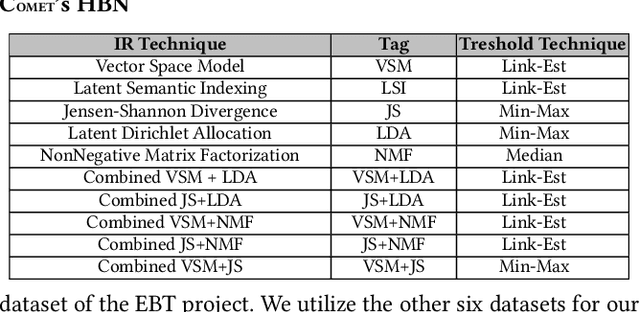
Traceability is a fundamental component of the modern software development process that helps to ensure properly functioning, secure programs. Due to the high cost of manually establishing trace links, researchers have developed automated approaches that draw relationships between pairs of textual software artifacts using similarity measures. However, the effectiveness of such techniques are often limited as they only utilize a single measure of artifact similarity and cannot simultaneously model (implicit and explicit) relationships across groups of diverse development artifacts. In this paper, we illustrate how these limitations can be overcome through the use of a tailored probabilistic model. To this end, we design and implement a HierarchiCal PrObabilistic Model for SoftwarE Traceability (Comet) that is able to infer candidate trace links. Comet is capable of modeling relationships between artifacts by combining the complementary observational prowess of multiple measures of textual similarity. Additionally, our model can holistically incorporate information from a diverse set of sources, including developer feedback and transitive (often implicit) relationships among groups of software artifacts, to improve inference accuracy. We conduct a comprehensive empirical evaluation of Comet that illustrates an improvement over a set of optimally configured baselines of $\approx$14% in the best case and $\approx$5% across all subjects in terms of average precision. The comparative effectiveness of Comet in practice, where optimal configuration is typically not possible, is likely to be higher. Finally, we illustrate Comets potential for practical applicability in a survey with developers from Cisco Systems who used a prototype Comet Jenkins plugin.