 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a Theory of Causation for Interpreting Neural Code Models
Paper and Code
Feb 07, 2023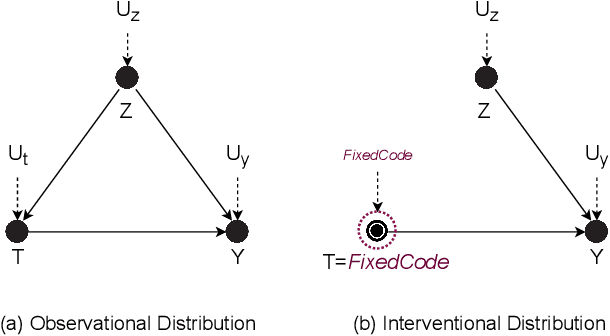
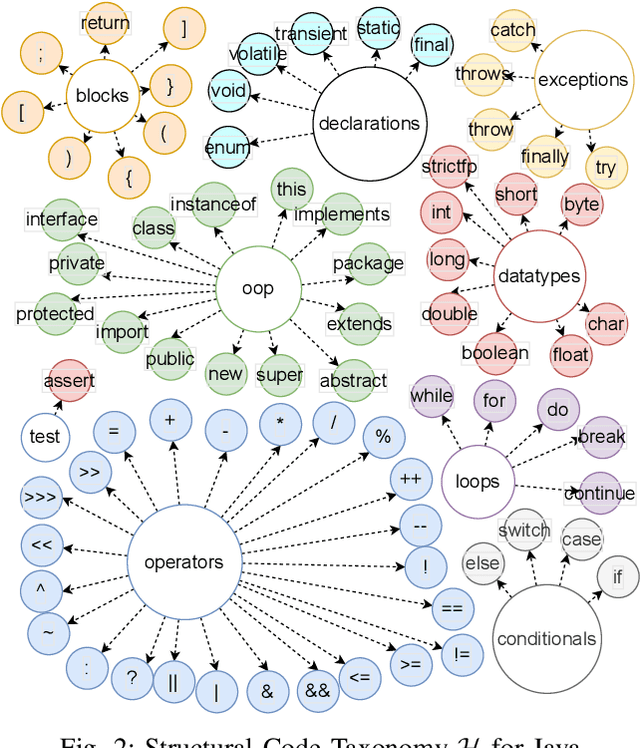
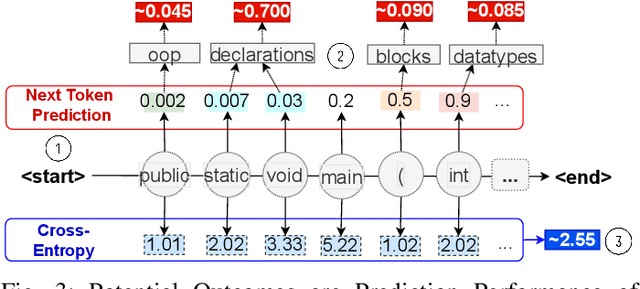
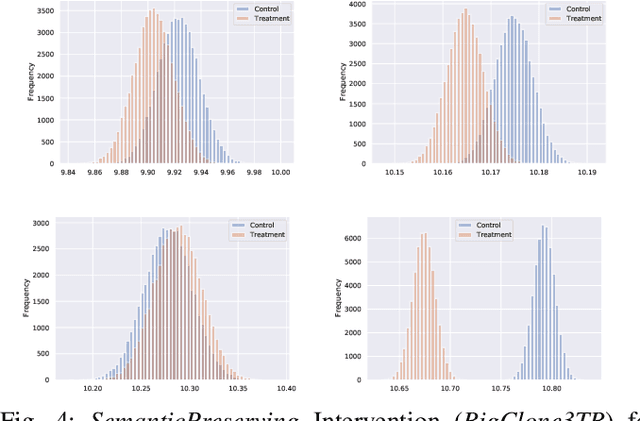
Neural Language Models of Code, or Neural Code Models (NCMs), are rapidly progressing from research prototypes to commercial developer tools. As such, understanding the capabilities and limitations of such models is becoming critical. However, the abilities of these models are typically measured using automated metrics that often only reveal a portion of their real-world performance. While, in general, the performance of NCMs appears promising, currently much is unknown about how such models arrive at decisions. To this end, this paper introduces $do_{code}$, a post-hoc interpretability methodology specific to NCMs that is capable of explaining model predictions. $do_{code}$ is based upon causal inference to enable programming language-oriented explanations. While the theoretical underpinnings of $do_{code}$ are extensible to exploring different model properties, we provide a concrete instantiation that aims to mitigate the impact of spurious correlations by grounding explanations of model behavior in properties of programming languages. To demonstrate the practical benefit of $do_{code}$, we illustrate the insights that our framework can provide by performing a case study on two popular deep learning architectures and nine NCMs. The results of this case study illustrate that our studied NCMs are sensitive to changes in code syntax and statistically learn to predict tokens related to blocks of code (e.g., brackets, parenthesis, semicolon) with less confounding bias as compared to other programming language constructs. These insights demonstrate the potential of $do_{code}$ as a useful model debugging mechanism that may aid in discovering biases and limitations in NCMs.