 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlink: CPU-Free LLM Inference by Delegating the Serving Stack to GPU and SmartNIC
Apr 08, 2026Large Language Model (LLM) inference is rapidly becoming a core datacenter service, yet current serving stacks keep the host CPU on the critical path for orchestration and token-level control. This makes LLM performance sensitive to CPU interference, undermining application colocation and forcing operators to reserve CPU headroom, leaving substantial capacity unutilized. We introduce Blink, an end-to-end serving architecture that removes the host CPU from the steady-state inference path by redistributing responsibilities across a SmartNIC and a GPU. Blink offloads request handling to the SmartNIC, which delivers inputs directly into GPU memory via RDMA, and replaces host-driven scheduling with a persistent GPU kernel that performs batching, scheduling, and KV-cache management without CPU involvement. Evaluated against TensorRT-LLM, vLLM, and SGLang, Blink outperforms all baselines even in isolation, reducing pre-saturation P99 TTFT by up to 8.47$\times$ and P99 TPOT by up to 3.40$\times$, improving decode throughput by up to 2.1$\times$, and reducing energy per token by up to 48.6$\%$. Under CPU interference, Blink maintains stable performance, while existing systems degrade by up to two orders of magnitude.
Priority-Aware Preemptive Scheduling for Mixed-Priority Workloads in MoE Inference
Mar 12, 2025



Large Language Models have revolutionized natural language processing, yet serving them efficiently in data centers remains challenging due to mixed workloads comprising latency-sensitive (LS) and best-effort (BE) jobs. Existing inference systems employ iteration-level first-come-first-served scheduling, causing head-of-line blocking when BE jobs delay LS jobs. We introduce QLLM, a novel inference system designed for Mixture of Experts (MoE) models, featuring a fine-grained, priority-aware preemptive scheduler. QLLM enables expert-level preemption, deferring BE job execution while minimizing LS time-to-first-token (TTFT). Our approach removes iteration-level scheduling constraints, enabling the scheduler to preempt jobs at any layer based on priority. Evaluations on an Nvidia A100 GPU show that QLLM significantly improves performance. It reduces LS TTFT by an average of $65.5\times$ and meets the SLO at up to $7$ requests/sec, whereas the baseline fails to do so under the tested workload. Additionally, it cuts LS turnaround time by up to $12.8\times$ without impacting throughput. QLLM is modular, extensible, and seamlessly integrates with Hugging Face MoE models.
Deriving Coding-Specific Sub-Models from LLMs using Resource-Efficient Pruning
Jan 09, 2025



Large Language Models (LLMs) have demonstrated their exceptional performance in various complex code generation tasks. However, their broader adoption is limited by significant computational demands and high resource requirements, particularly memory and processing power. To mitigate such requirements, model pruning techniques are used to create more compact models with significantly fewer parameters. However, current approaches do not focus on the efficient extraction of programming-language-specific sub-models. In this work, we explore the idea of efficiently deriving coding-specific sub-models through unstructured pruning (i.e., Wanda). We investigate the impact of different domain-specific calibration datasets on pruning outcomes across three distinct domains and extend our analysis to extracting four language-specific sub-models: Python, Java, C++, and JavaScript. We are the first to efficiently extract programming-language-specific sub-models using appropriate calibration datasets while maintaining acceptable accuracy w.r.t. full models. We are also the first to provide analytical evidence that domain-specific tasks activate distinct regions within LLMs, supporting the creation of specialized sub-models through unstructured pruning. We believe that this work has significant potential to enhance LLM accessibility for coding by reducing computational requirements to enable local execution on consumer-grade hardware, and supporting faster inference times critical for real-time development feedback.
Automating the Detection of Code Vulnerabilities by Analyzing GitHub Issues
Jan 09, 2025In today's digital landscape, the importance of timely and accurate vulnerability detection has significantly increased. This paper presents a novel approach that leverages transformer-based models and machine learning techniques to automate the identification of software vulnerabilities by analyzing GitHub issues. We introduce a new dataset specifically designed for classifying GitHub issues relevant to vulnerability detection. We then examine various classification techniques to determine their effectiveness. The results demonstrate the potential of this approach for real-world application in early vulnerability detection, which could substantially reduce the window of exploitation for software vulnerabilities. This research makes a key contribution to the field by providing a scalable and computationally efficient framework for automated detection, enabling the prevention of compromised software usage before official notifications. This work has the potential to enhance the security of open-source software ecosystems.
From Scientific Texts to Verifiable Code: Automating the Process with Transformers
Jan 09, 2025Despite the vast body of research literature proposing algorithms with formal guarantees, the amount of verifiable code in today's systems remains minimal. This discrepancy stems from the inherent difficulty of verifying code, particularly due to the time-consuming nature and strict formalism of proof details that formal verification tools require. However, the emergence of transformers in Large Language Models presents a promising solution to this challenge. In this position paper, we believe that transformers have the potential to read research papers that propose algorithms with formal proofs and translate these proofs into verifiable code. We leverage transformers to first build a formal structure of the proof using the original text from the paper, and then to handle the tedious, low-level aspects of proofs that are often omitted by humans. We argue that this approach can significantly reduce the barrier to formal verification. The above idea of reading papers to write verifiable code opens new avenues for automating the verification of complex systems, enabling a future where formally verified algorithms from academic research can more seamlessly transition into real-world software systems, thereby improving code reliability and security.
FMM-Head: Enhancing Autoencoder-based ECG anomaly detection with prior knowledge
Oct 06, 2023Detecting anomalies in electrocardiogram data is crucial to identifying deviations from normal heartbeat patterns and providing timely intervention to at-risk patients. Various AutoEncoder models (AE) have been proposed to tackle the anomaly detection task with ML. However, these models do not consider the specific patterns of ECG leads and are unexplainable black boxes. In contrast, we replace the decoding part of the AE with a reconstruction head (namely, FMM-Head) based on prior knowledge of the ECG shape. Our model consistently achieves higher anomaly detection capabilities than state-of-the-art models, up to 0.31 increase in area under the ROC curve (AUROC), with as little as half the original model size and explainable extracted features. The processing time of our model is four orders of magnitude lower than solving an optimization problem to obtain the same parameters, thus making it suitable for real-time ECG parameters extraction and anomaly detection.
Fast Server Learning Rate Tuning for Coded Federated Dropout
Jan 26, 2022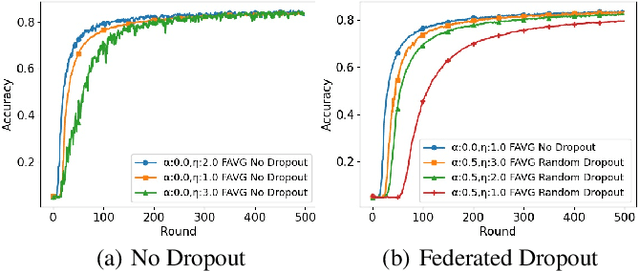
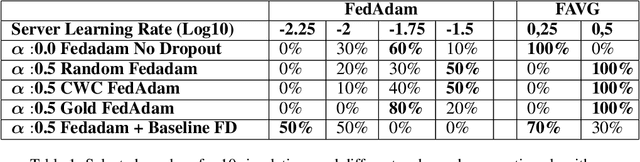

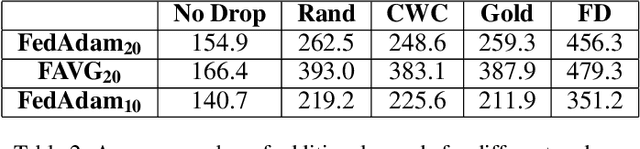
In cross-device Federated Learning (FL), clients with low computational power train a common machine model by exchanging parameters updates instead of potentially private data. Federated Dropout (FD) is a technique that improves the communication efficiency of a FL session by selecting a subset of model variables to be updated in each training round. However, FD produces considerably lower accuracy and higher convergence time compared to standard FL. In this paper, we leverage coding theory to enhance FD by allowing a different sub-model to be used at each client. We also show that by carefully tuning the server learning rate hyper-parameter, we can achieve higher training speed and up to the same final accuracy of the no dropout case. For the EMNIST dataset, our mechanism achieves 99.6 % of the final accuracy of the no dropout case while requiring 2.43x less bandwidth to achieve this accuracy level.