 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Server Learning Rate Tuning for Coded Federated Dropout
Jan 26, 2022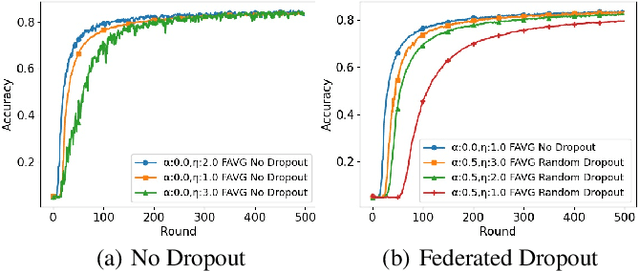
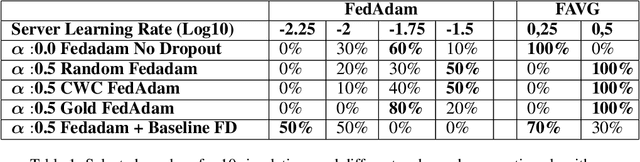

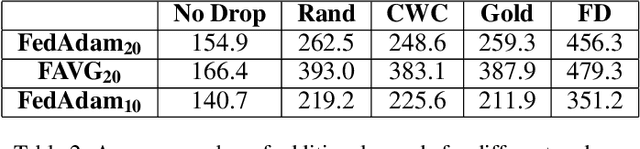
In cross-device Federated Learning (FL), clients with low computational power train a common machine model by exchanging parameters updates instead of potentially private data. Federated Dropout (FD) is a technique that improves the communication efficiency of a FL session by selecting a subset of model variables to be updated in each training round. However, FD produces considerably lower accuracy and higher convergence time compared to standard FL. In this paper, we leverage coding theory to enhance FD by allowing a different sub-model to be used at each client. We also show that by carefully tuning the server learning rate hyper-parameter, we can achieve higher training speed and up to the same final accuracy of the no dropout case. For the EMNIST dataset, our mechanism achieves 99.6 % of the final accuracy of the no dropout case while requiring 2.43x less bandwidth to achieve this accuracy level.