 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity-Aware Communication for Distributed Graph Neural Network Training
Apr 07, 2025Graph Neural Networks (GNNs) are a computationally efficient method to learn embeddings and classifications on graph data. However, GNN training has low computational intensity, making communication costs the bottleneck for scalability. Sparse-matrix dense-matrix multiplication (SpMM) is the core computational operation in full-graph training of GNNs. Previous work parallelizing this operation focused on sparsity-oblivious algorithms, where matrix elements are communicated regardless of the sparsity pattern. This leads to a predictable communication pattern that can be overlapped with computation and enables the use of collective communication operations at the expense of wasting significant bandwidth by communicating unnecessary data. We develop sparsity-aware algorithms that tackle the communication bottlenecks in GNN training with three novel approaches. First, we communicate only the necessary matrix elements. Second, we utilize a graph partitioning model to reorder the matrix and drastically reduce the amount of communicated elements. Finally, we address the high load imbalance in communication with a tailored partitioning model, which minimizes both the total communication volume and the maximum sending volume. We further couple these sparsity-exploiting approaches with a communication-avoiding approach (1.5D parallel SpMM) in which submatrices are replicated to reduce communication. We explore the tradeoffs of these combined optimizations and show up to 14X improvement on 256 GPUs and on some instances reducing communication to almost zero resulting in a communication-free parallel training relative to a popular GNN framework based on communication-oblivious SpMM.
Scaling Graph Neural Networks for Particle Track Reconstruction
Apr 07, 2025Particle track reconstruction is an important problem in high-energy physics (HEP), necessary to study properties of subatomic particles. Traditional track reconstruction algorithms scale poorly with the number of particles within the accelerator. The Exa.TrkX project, to alleviate this computational burden, introduces a pipeline that reduces particle track reconstruction to edge classification on a graph, and uses graph neural networks (GNNs) to produce particle tracks. However, this GNN-based approach is memory-prohibitive and skips graphs that would exceed GPU memory. We introduce improvements to the Exa.TrkX pipeline to train on samples of input particle graphs, and show that these improvements generalize to higher precision and recall. In addition, we adapt performance optimizations, introduced for GNN training, to fit our augmented Exa.TrkX pipeline. These optimizations provide a $2\times$ speedup over our baseline implementation in PyTorch Geometric.
Distributed Matrix-Based Sampling for Graph Neural Network Training
Nov 06, 2023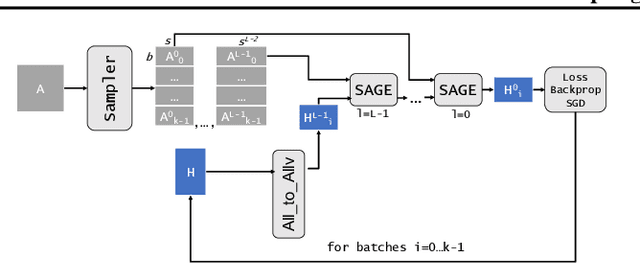
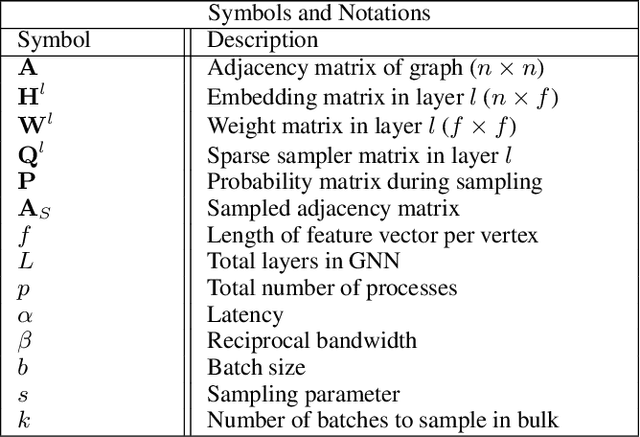
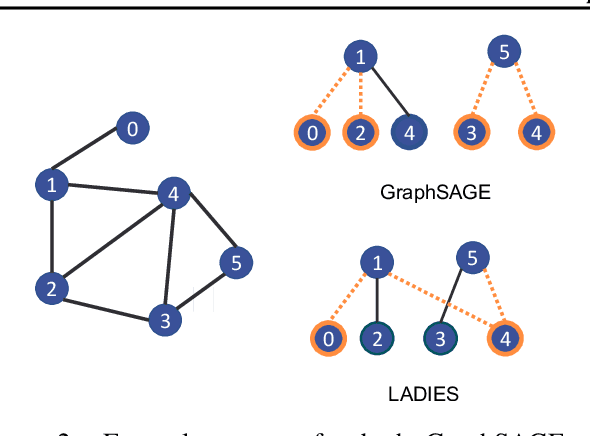
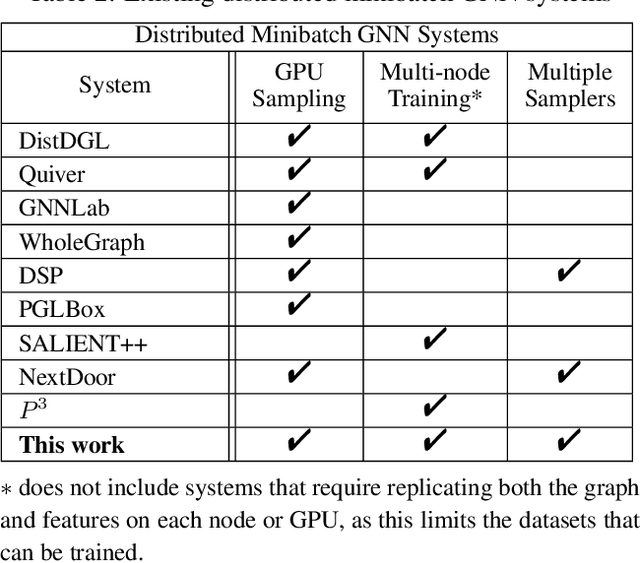
The primary contribution of this paper is new methods for reducing communication in the sampling step for distributed GNN training. Here, we propose a matrix-based bulk sampling approach that expresses sampling as a sparse matrix multiplication (SpGEMM) and samples multiple minibatches at once. When the input graph topology does not fit on a single device, our method distributes the graph and use communication-avoiding SpGEMM algorithms to scale GNN minibatch sampling, enabling GNN training on much larger graphs than those that can fit into a single device memory. When the input graph topology (but not the embeddings) fits in the memory of one GPU, our approach (1) performs sampling without communication, (2) amortizes the overheads of sampling a minibatch, and (3) can represent multiple sampling algorithms by simply using different matrix constructions. In addition to new methods for sampling, we show that judiciously replicating feature data with a simple all-to-all exchange can outperform current methods for the feature extraction step in distributed GNN training. We provide experimental results on the largest Open Graph Benchmark (OGB) datasets on $128$ GPUs, and show that our pipeline is $2.5\times$ faster Quiver (a distributed extension to PyTorch-Geometric) on a $3$-layer GraphSAGE network. On datasets outside of OGB, we show a $8.46\times$ speedup on $128$ GPUs in-per epoch time. Finally, we show scaling when the graph is distributed across GPUs and scaling for both node-wise and layer-wise sampling algorithms
Randomized Algorithms for Scientific Computing (RASC)
Apr 19, 2021
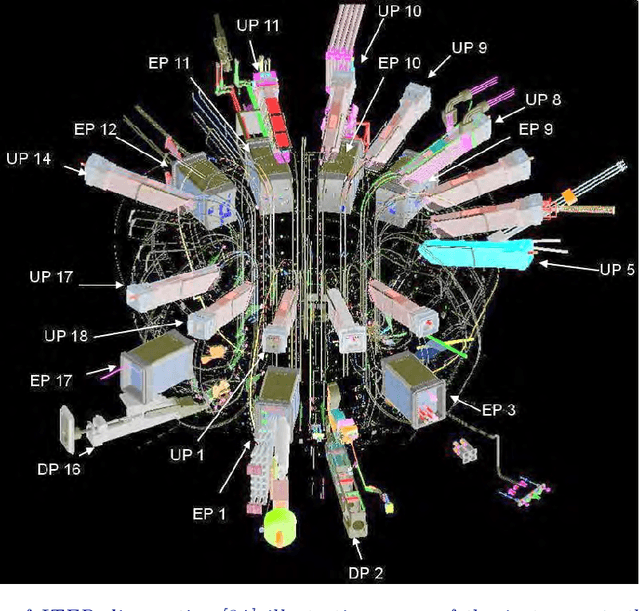

Randomized algorithms have propelled advances in artificial intelligence and represent a foundational research area in advancing AI for Science. Future advancements in DOE Office of Science priority areas such as climate science, astrophysics, fusion, advanced materials, combustion, and quantum computing all require randomized algorithms for surmounting challenges of complexity, robustness, and scalability. This report summarizes the outcomes of that workshop, "Randomized Algorithms for Scientific Computing (RASC)," held virtually across four days in December 2020 and January 2021.
PersGNN: Applying Topological Data Analysis and Geometric Deep Learning to Structure-Based Protein Function Prediction
Oct 30, 2020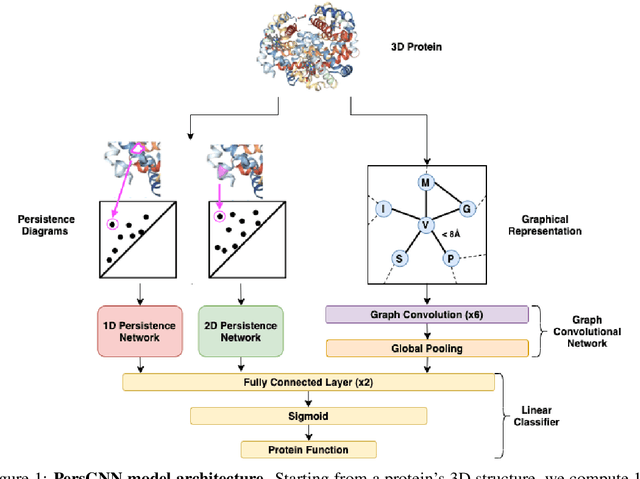
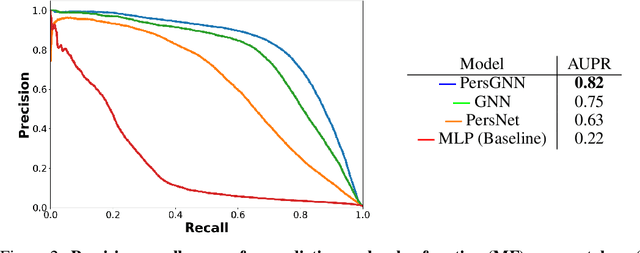
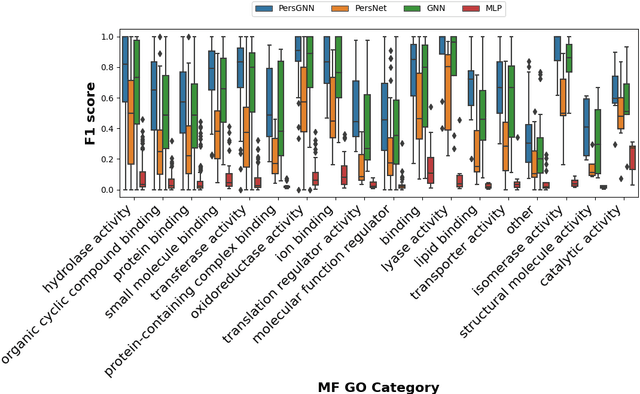
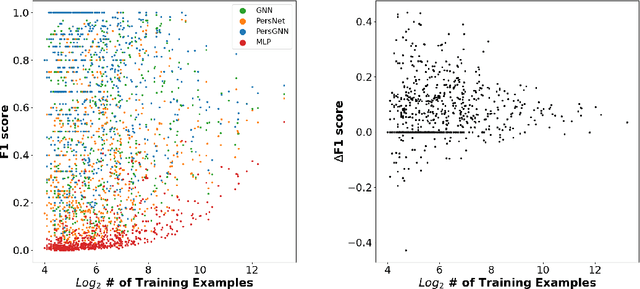
Understanding protein structure-function relationships is a key challenge in computational biology, with applications across the biotechnology and pharmaceutical industries. While it is known that protein structure directly impacts protein function, many functional prediction tasks use only protein sequence. In this work, we isolate protein structure to make functional annotations for proteins in the Protein Data Bank in order to study the expressiveness of different structure-based prediction schemes. We present PersGNN - an end-to-end trainable deep learning model that combines graph representation learning with topological data analysis to capture a complex set of both local and global structural features. While variations of these techniques have been successfully applied to proteins before, we demonstrate that our hybridized approach, PersGNN, outperforms either method on its own as well as a baseline neural network that learns from the same information. PersGNN achieves a 9.3% boost in area under the precision recall curve (AUPR) compared to the best individual model, as well as high F1 scores across different gene ontology categories, indicating the transferability of this approach.
Reducing Communication in Graph Neural Network Training
May 07, 2020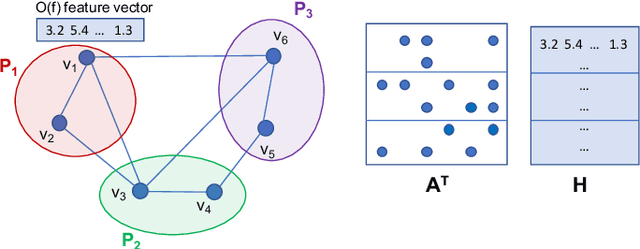



Graph Neural Networks (GNNs) are powerful and flexible neural networks that use the naturally sparse connectivity information of the data. GNNs represent this connectivity as sparse matrices, which have lower arithmetic intensity and thus higher communication costs compared to dense matrices, making GNNs harder to scale to high concurrencies than convolutional or fully-connected neural networks. We present a family of parallel algorithms for training GNNs. These algorithms are based on their counterparts in dense and sparse linear algebra, but they had not been previously applied to GNN training. We show that they can asymptotically reduce communication compared to existing parallel GNN training methods. We implement a promising and practical version that is based on 2D sparse-dense matrix multiplication using torch.distributed. Our implementation parallelizes over GPU-equipped clusters. We train GNNs on up to a hundred GPUs on datasets that include a protein network with over a billion edges.
Integrated Model, Batch and Domain Parallelism in Training Neural Networks
May 16, 2018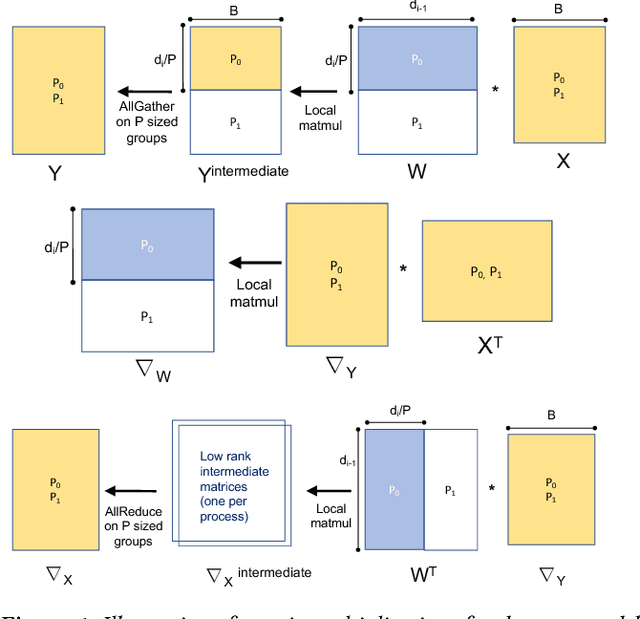
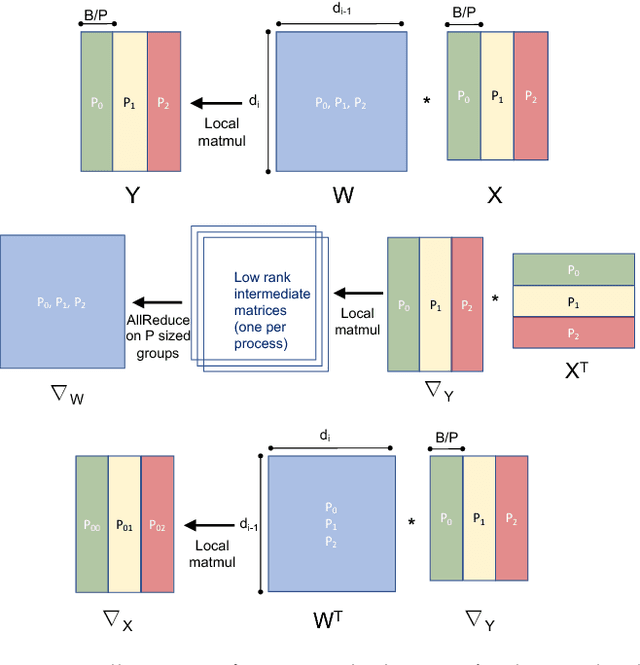

We propose a new integrated method of exploiting model, batch and domain parallelism for the training of deep neural networks (DNNs) on large distributed-memory computers using minibatch stochastic gradient descent (SGD). Our goal is to find an efficient parallelization strategy for a fixed batch size using $P$ processes. Our method is inspired by the communication-avoiding algorithms in numerical linear algebra. We see $P$ processes as logically divided into a $P_r \times P_c$ grid where the $P_r$ dimension is implicitly responsible for model/domain parallelism and the $P_c$ dimension is implicitly responsible for batch parallelism. In practice, the integrated matrix-based parallel algorithm encapsulates these types of parallelism automatically. We analyze the communication complexity and analytically demonstrate that the lowest communication costs are often achieved neither with pure model nor with pure data parallelism. We also show how the domain parallel approach can help in extending the theoretical scaling limit of the typical batch parallel method.
* 11 pages
Communication-Avoiding Optimization Methods for Distributed Massive-Scale Sparse Inverse Covariance Estimation
Apr 08, 2018
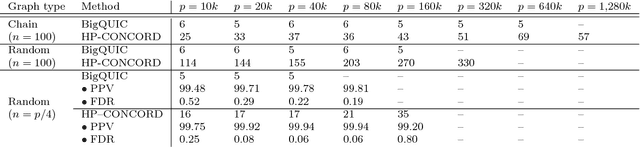

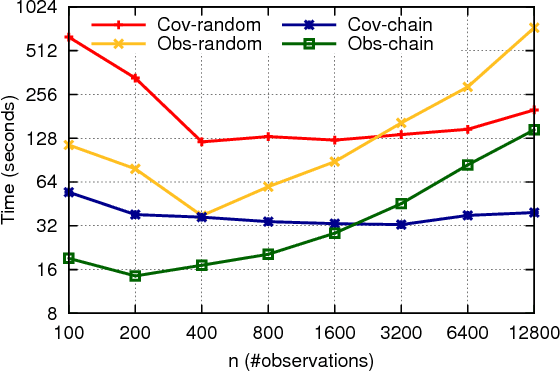
Across a variety of scientific disciplines, sparse inverse covariance estimation is a popular tool for capturing the underlying dependency relationships in multivariate data. Unfortunately, most estimators are not scalable enough to handle the sizes of modern high-dimensional data sets (often on the order of terabytes), and assume Gaussian samples. To address these deficiencies, we introduce HP-CONCORD, a highly scalable optimization method for estimating a sparse inverse covariance matrix based on a regularized pseudolikelihood framework, without assuming Gaussianity. Our parallel proximal gradient method uses a novel communication-avoiding linear algebra algorithm and runs across a multi-node cluster with up to 1k nodes (24k cores), achieving parallel scalability on problems with up to ~819 billion parameters (1.28 million dimensions); even on a single node, HP-CONCORD demonstrates scalability, outperforming a state-of-the-art method. We also use HP-CONCORD to estimate the underlying dependency structure of the brain from fMRI data, and use the result to identify functional regions automatically. The results show good agreement with a clustering from the neuroscience literature.