 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMem: Estimating GPU Memory Usage for Fine-Tuning Pre-Trained LLMs
Apr 16, 2024



Fine-tuning pre-trained large language models (LLMs) with limited hardware presents challenges due to GPU memory constraints. Various distributed fine-tuning methods have been proposed to alleviate memory constraints on GPU. However, determining the most effective method for achieving rapid fine-tuning while preventing GPU out-of-memory issues in a given environment remains unclear. To address this challenge, we introduce LLMem, a solution that estimates the GPU memory consumption when applying distributed fine-tuning methods across multiple GPUs and identifies the optimal method. We conduct GPU memory usage estimation prior to fine-tuning, leveraging the fundamental structure of transformer-based decoder models and the memory usage distribution of each method. Experimental results show that LLMem accurately estimates peak GPU memory usage on a single GPU, with error rates of up to 1.6%. Additionally, it shows an average error rate of 3.0% when applying distributed fine-tuning methods to LLMs with more than a billion parameters on multi-GPU setups.
FIS-ONE: Floor Identification System with One Label for Crowdsourced RF Signals
Jul 12, 2023Floor labels of crowdsourced RF signals are crucial for many smart-city applications, such as multi-floor indoor localization, geofencing, and robot surveillance. To build a prediction model to identify the floor number of a new RF signal upon its measurement, conventional approaches using the crowdsourced RF signals assume that at least few labeled signal samples are available on each floor. In this work, we push the envelope further and demonstrate that it is technically feasible to enable such floor identification with only one floor-labeled signal sample on the bottom floor while having the rest of signal samples unlabeled. We propose FIS-ONE, a novel floor identification system with only one labeled sample. FIS-ONE consists of two steps, namely signal clustering and cluster indexing. We first build a bipartite graph to model the RF signal samples and obtain a latent representation of each node (each signal sample) using our attention-based graph neural network model so that the RF signal samples can be clustered more accurately. Then, we tackle the problem of indexing the clusters with proper floor labels, by leveraging the observation that signals from an access point can be detected on different floors, i.e., signal spillover. Specifically, we formulate a cluster indexing problem as a combinatorial optimization problem and show that it is equivalent to solving a traveling salesman problem, whose (near-)optimal solution can be found efficiently. We have implemented FIS-ONE and validated its effectiveness on the Microsoft dataset and in three large shopping malls. Our results show that FIS-ONE outperforms other baseline algorithms significantly, with up to 23% improvement in adjusted rand index and 25% improvement in normalized mutual information using only one floor-labeled signal sample.
CPrune: Compiler-Informed Model Pruning for Efficient Target-Aware DNN Execution
Jul 04, 2022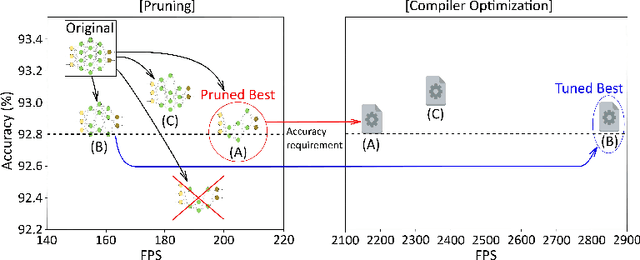
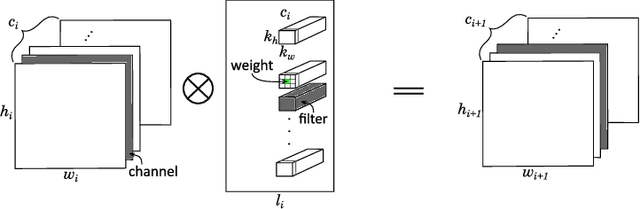
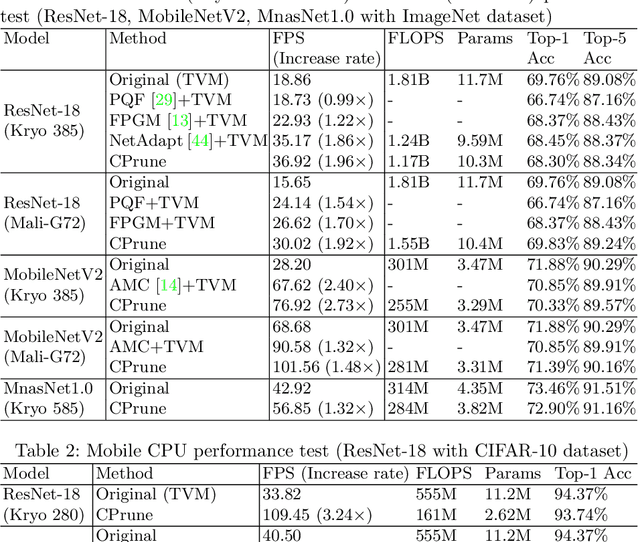
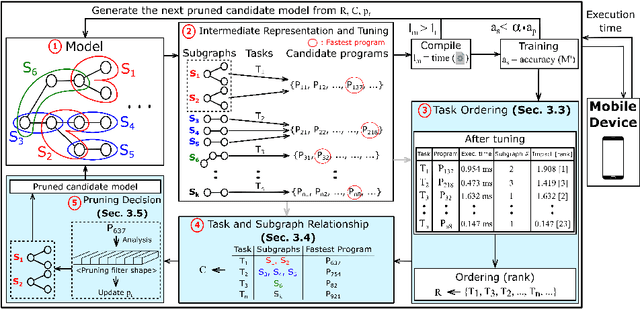
Mobile devices run deep learning models for various purposes, such as image classification and speech recognition. Due to the resource constraints of mobile devices, researchers have focused on either making a lightweight deep neural network (DNN) model using model pruning or generating an efficient code using compiler optimization. Surprisingly, we found that the straightforward integration between model compression and compiler auto-tuning often does not produce the most efficient model for a target device. We propose CPrune, a compiler-informed model pruning for efficient target-aware DNN execution to support an application with a required target accuracy. CPrune makes a lightweight DNN model through informed pruning based on the structural information of subgraphs built during the compiler tuning process. Our experimental results show that CPrune increases the DNN execution speed up to 2.73x compared to the state-of-the-art TVM auto-tune while satisfying the accuracy requirement.
TVConv: Efficient Translation Variant Convolution for Layout-aware Visual Processing
Mar 22, 2022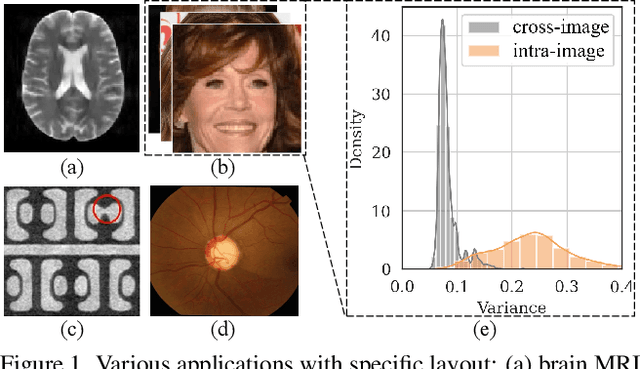
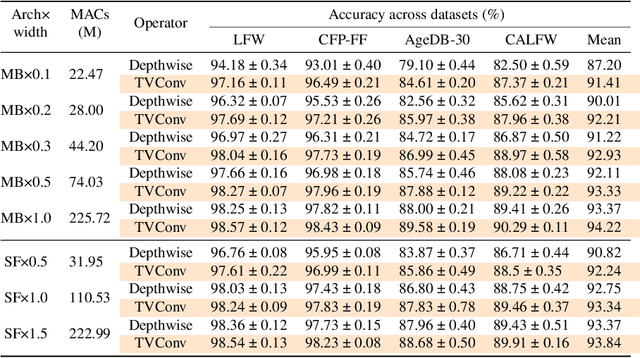
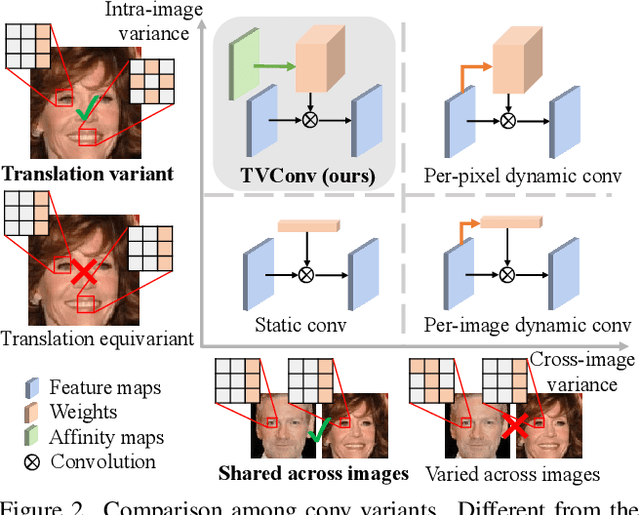
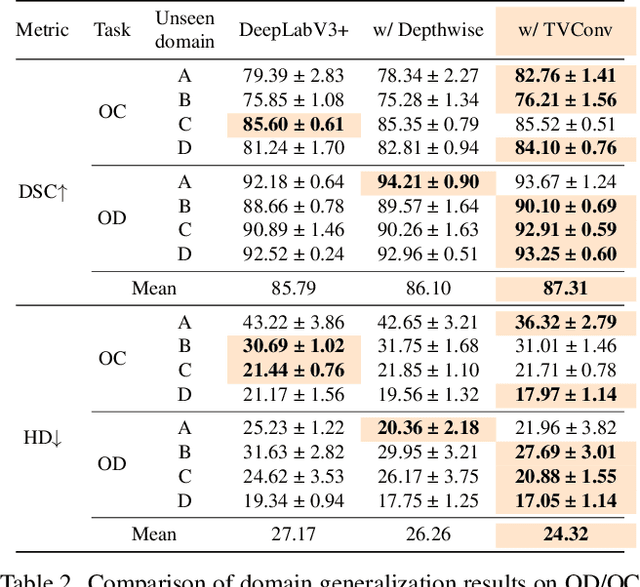
As convolution has empowered many smart applications, dynamic convolution further equips it with the ability to adapt to diverse inputs. However, the static and dynamic convolutions are either layout-agnostic or computation-heavy, making it inappropriate for layout-specific applications, e.g., face recognition and medical image segmentation. We observe that these applications naturally exhibit the characteristics of large intra-image (spatial) variance and small cross-image variance. This observation motivates our efficient translation variant convolution (TVConv) for layout-aware visual processing. Technically, TVConv is composed of affinity maps and a weight-generating block. While affinity maps depict pixel-paired relationships gracefully, the weight-generating block can be explicitly overparameterized for better training while maintaining efficient inference. Although conceptually simple, TVConv significantly improves the efficiency of the convolution and can be readily plugged into various network architectures. Extensive experiments on face recognition show that TVConv reduces the computational cost by up to 3.1x and improves the corresponding throughput by 2.3x while maintaining a high accuracy compared to the depthwise convolution. Moreover, for the same computation cost, we boost the mean accuracy by up to 4.21%. We also conduct experiments on the optic disc/cup segmentation task and obtain better generalization performance, which helps mitigate the critical data scarcity issue. Code is available at https://github.com/JierunChen/TVConv.