 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRaCompass: Robust Reinforcement Learning to Efficiently Search for a LoRa Tag
Nov 14, 2025


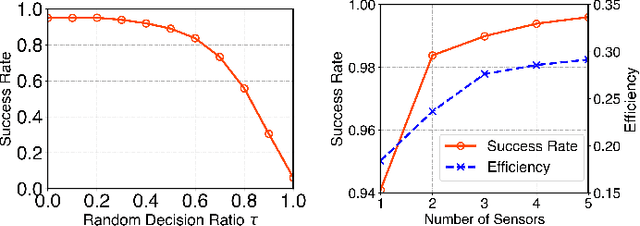
The Long-Range (LoRa) protocol, known for its extensive range and low power, has increasingly been adopted in tags worn by mentally incapacitated persons (MIPs) and others at risk of going missing. We study the sequential decision-making process for a mobile sensor to locate a periodically broadcasting LoRa tag with the fewest moves (hops) in general, unknown environments, guided by the received signal strength indicator (RSSI). While existing methods leverage reinforcement learning for search, they remain vulnerable to domain shift and signal fluctuation, resulting in cascading decision errors that culminate in substantial localization inaccuracies. To bridge this gap, we propose LoRaCompass, a reinforcement learning model designed to achieve robust and efficient search for a LoRa tag. For exploitation under domain shift and signal fluctuation, LoRaCompass learns a robust spatial representation from RSSI to maximize the probability of moving closer to a tag, via a spatially-aware feature extractor and a policy distillation loss function. It further introduces an exploration function inspired by the upper confidence bound (UCB) that guides the sensor toward the tag with increasing confidence. We have validated LoRaCompass in ground-based and drone-assisted scenarios within diverse unseen environments covering an area of over 80km^2. It has demonstrated high success rate (>90%) in locating the tag within 100m proximity (a 40% improvement over existing methods) and high efficiency with a search path length (in hops) that scales linearly with the initial distance.
Elevator, Escalator or Neither? Classifying Pedestrian Conveyor State Using Inertial Navigation System
May 06, 2024



Classifying a pedestrian in one of the three conveyor states of "elevator," "escalator" and "neither" is fundamental to many applications such as indoor localization and people flow analysis. We estimate, for the first time, the pedestrian conveyor state given the inertial navigation system (INS) readings of accelerometer, gyroscope and magnetometer sampled from the phone. Our problem is challenging because the INS signals of the conveyor state are coupled and perturbed by unpredictable arbitrary human actions, confusing the decision process. We propose ELESON, a novel, effective and lightweight INS-based deep learning approach to classify whether a pedestrian is in an elevator, escalator or neither. ELESON utilizes a motion feature extractor to decouple the conveyor state from human action in the feature space, and a magnetic feature extractor to account for the speed difference between elevator and escalator. Given the results of the extractors, it employs an evidential state classifier to estimate the confidence of the pedestrian states. Based on extensive experiments conducted on twenty hours of real pedestrian data, we demonstrate that ELESON outperforms significantly the state-of-the-art approaches (where combined INS signals of both the conveyor state and human actions are processed together), with 15% classification improvement in F1 score, stronger confidence discriminability with 10% increase in AUROC (Area Under the Receiver Operating Characteristics), and low computational and memory requirements on smartphones.
Target-agnostic Source-free Domain Adaptation for Regression Tasks
Dec 01, 2023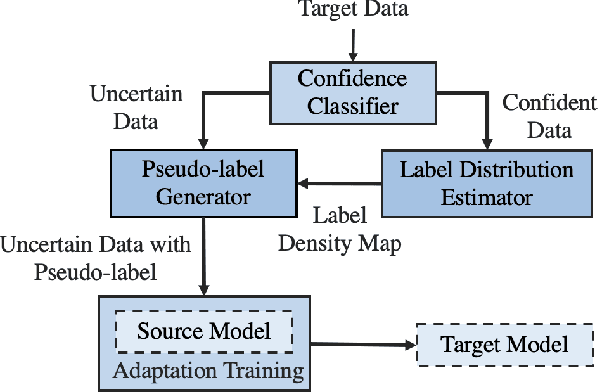
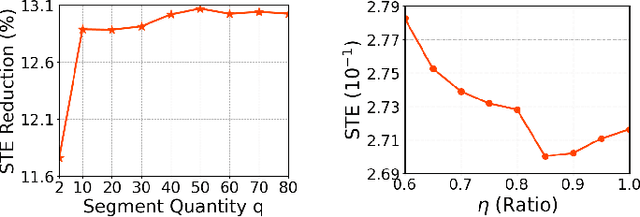
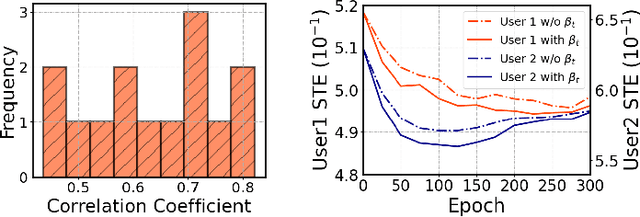

Unsupervised domain adaptation (UDA) seeks to bridge the domain gap between the target and source using unlabeled target data. Source-free UDA removes the requirement for labeled source data at the target to preserve data privacy and storage. However, work on source-free UDA assumes knowledge of domain gap distribution, and hence is limited to either target-aware or classification task. To overcome it, we propose TASFAR, a novel target-agnostic source-free domain adaptation approach for regression tasks. Using prediction confidence, TASFAR estimates a label density map as the target label distribution, which is then used to calibrate the source model on the target domain. We have conducted extensive experiments on four regression tasks with various domain gaps, namely, pedestrian dead reckoning for different users, image-based people counting in different scenes, housing-price prediction at different districts, and taxi-trip duration prediction from different departure points. TASFAR is shown to substantially outperform the state-of-the-art source-free UDA approaches by averagely reducing 22% errors for the four tasks and achieve notably comparable accuracy as source-based UDA without using source data.
TVConv: Efficient Translation Variant Convolution for Layout-aware Visual Processing
Mar 22, 2022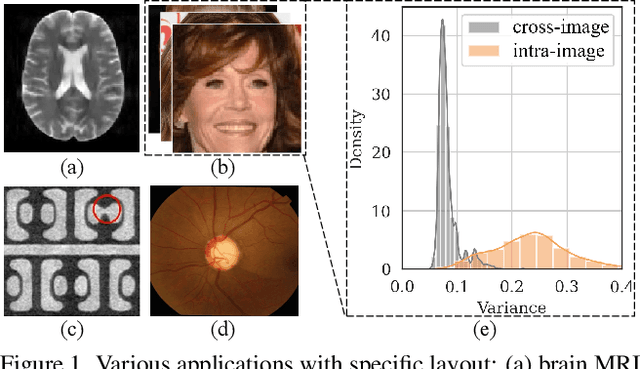
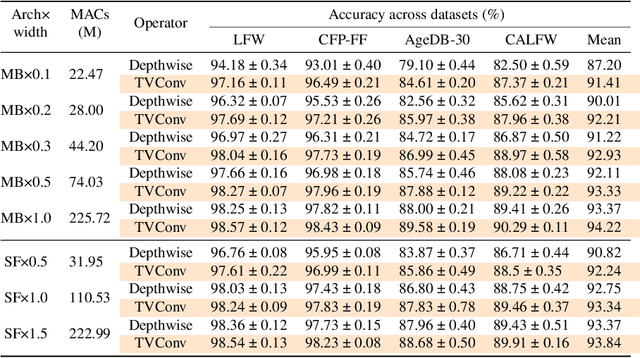
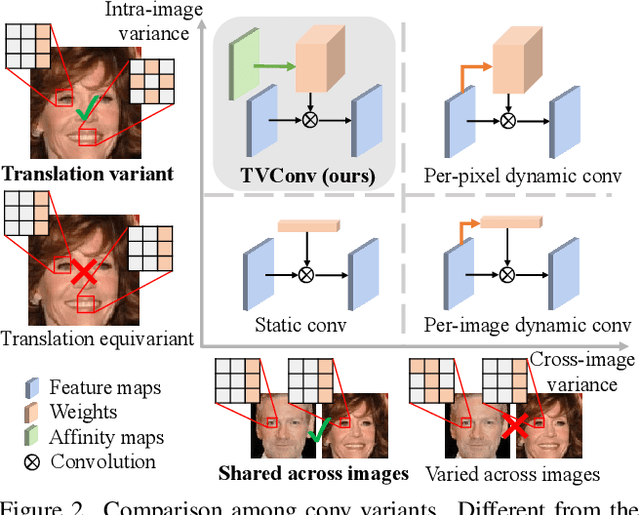
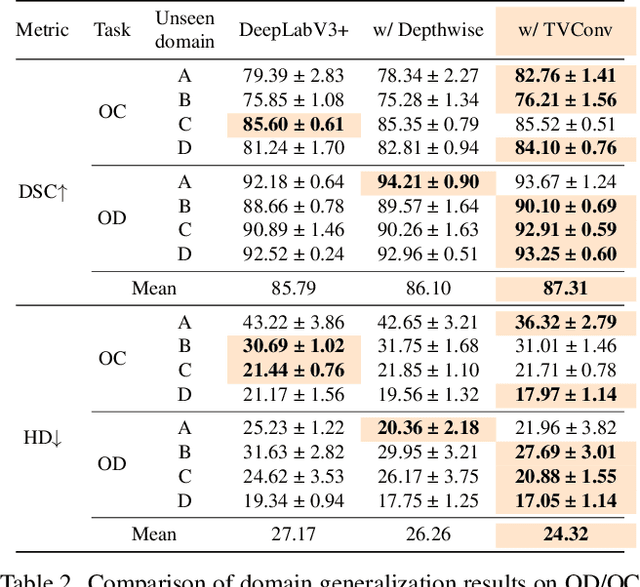
As convolution has empowered many smart applications, dynamic convolution further equips it with the ability to adapt to diverse inputs. However, the static and dynamic convolutions are either layout-agnostic or computation-heavy, making it inappropriate for layout-specific applications, e.g., face recognition and medical image segmentation. We observe that these applications naturally exhibit the characteristics of large intra-image (spatial) variance and small cross-image variance. This observation motivates our efficient translation variant convolution (TVConv) for layout-aware visual processing. Technically, TVConv is composed of affinity maps and a weight-generating block. While affinity maps depict pixel-paired relationships gracefully, the weight-generating block can be explicitly overparameterized for better training while maintaining efficient inference. Although conceptually simple, TVConv significantly improves the efficiency of the convolution and can be readily plugged into various network architectures. Extensive experiments on face recognition show that TVConv reduces the computational cost by up to 3.1x and improves the corresponding throughput by 2.3x while maintaining a high accuracy compared to the depthwise convolution. Moreover, for the same computation cost, we boost the mean accuracy by up to 4.21%. We also conduct experiments on the optic disc/cup segmentation task and obtain better generalization performance, which helps mitigate the critical data scarcity issue. Code is available at https://github.com/JierunChen/TVConv.