 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoencoder-based Denoising Defense against Adversarial Attacks on Object Detection
Dec 18, 2025Deep learning-based object detection models play a critical role in real-world applications such as autonomous driving and security surveillance systems, yet they remain vulnerable to adversarial examples. In this work, we propose an autoencoder-based denoising defense to recover object detection performance degraded by adversarial perturbations. We conduct adversarial attacks using Perlin noise on vehicle-related images from the COCO dataset, apply a single-layer convolutional autoencoder to remove the perturbations, and evaluate detection performance using YOLOv5. Our experiments demonstrate that adversarial attacks reduce bbox mAP from 0.2890 to 0.1640, representing a 43.3% performance degradation. After applying the proposed autoencoder defense, bbox mAP improves to 0.1700 (3.7% recovery) and bbox mAP@50 increases from 0.2780 to 0.3080 (10.8% improvement). These results indicate that autoencoder-based denoising can provide partial defense against adversarial attacks without requiring model retraining.
Visual Preference Inference: An Image Sequence-Based Preference Reasoning in Tabletop Object Manipulation
Mar 18, 2024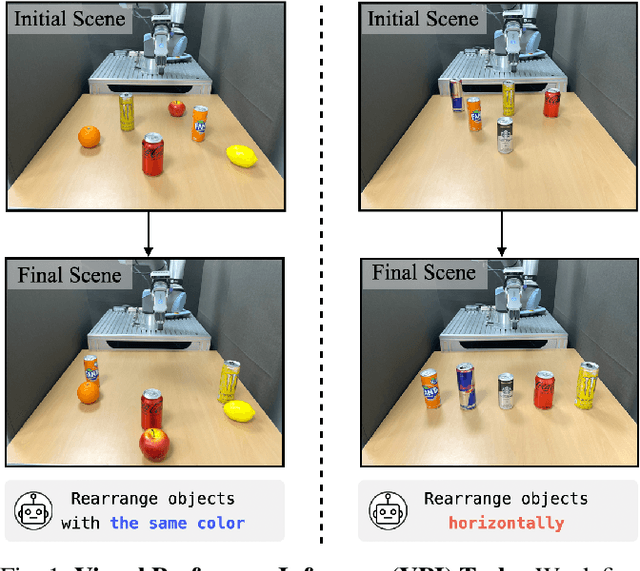

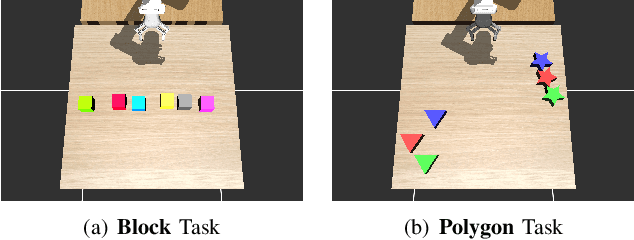

In robotic object manipulation, human preferences can often be influenced by the visual attributes of objects, such as color and shape. These properties play a crucial role in operating a robot to interact with objects and align with human intention. In this paper, we focus on the problem of inferring underlying human preferences from a sequence of raw visual observations in tabletop manipulation environments with a variety of object types, named Visual Preference Inference (VPI). To facilitate visual reasoning in the context of manipulation, we introduce the Chain-of-Visual-Residuals (CoVR) method. CoVR employs a prompting mechanism that describes the difference between the consecutive images (i.e., visual residuals) and incorporates such texts with a sequence of images to infer the user's preference. This approach significantly enhances the ability to understand and adapt to dynamic changes in its visual environment during manipulation tasks. Furthermore, we incorporate such texts along with a sequence of images to infer the user's preferences. Our method outperforms baseline methods in terms of extracting human preferences from visual sequences in both simulation and real-world environments. Code and videos are available at: \href{https://joonhyung-lee.github.io/vpi/}{https://joonhyung-lee.github.io/vpi/}
SPOTS: Stable Placement of Objects with Reasoning in Semi-Autonomous Teleoperation Systems
Sep 25, 2023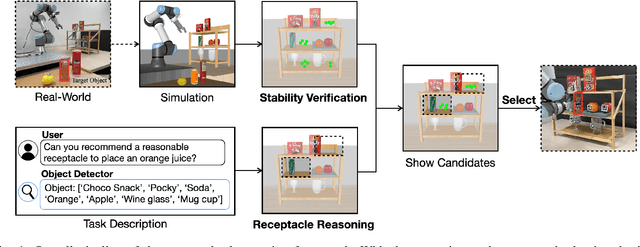
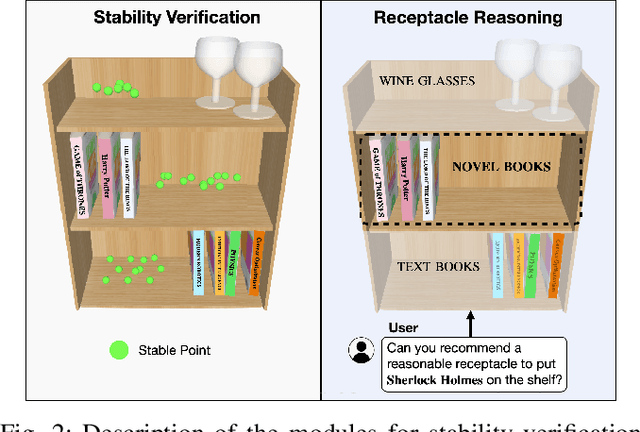
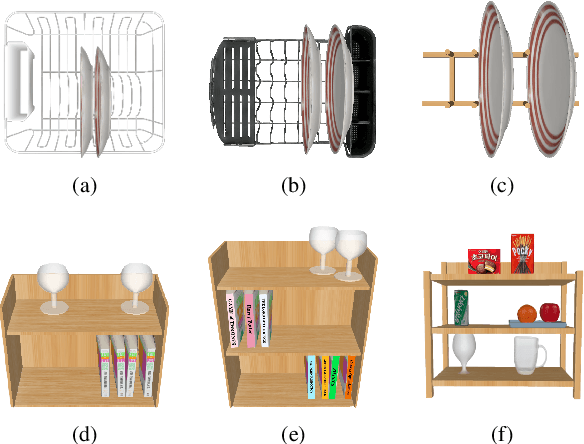
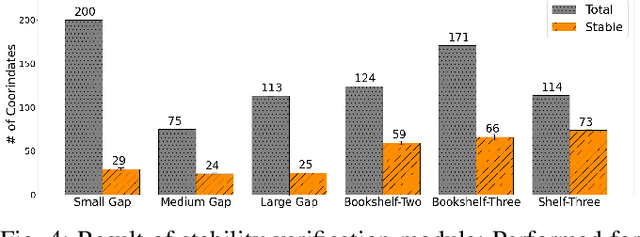
Pick-and-place is one of the fundamental tasks in robotics research. However, the attention has been mostly focused on the ``pick'' task, leaving the ``place'' task relatively unexplored. In this paper, we address the problem of placing objects in the context of a teleoperation framework. Particularly, we focus on two aspects of the place task: stability robustness and contextual reasonableness of object placements. Our proposed method combines simulation-driven physical stability verification via real-to-sim and the semantic reasoning capability of large language models. In other words, given place context information (e.g., user preferences, object to place, and current scene information), our proposed method outputs a probability distribution over the possible placement candidates, considering the robustness and reasonableness of the place task. Our proposed method is extensively evaluated in two simulation and one real world environments and we show that our method can greatly increase the physical plausibility of the placement as well as contextual soundness while considering user preferences.
CLARA: Classifying and Disambiguating User Commands for Reliable Interactive Robotic Agents
Jun 22, 2023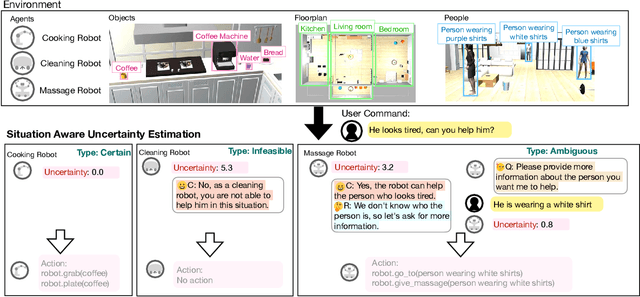
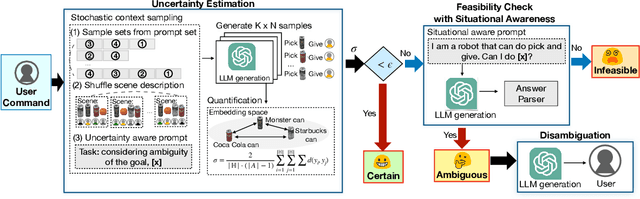
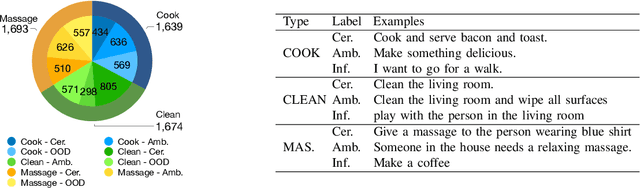
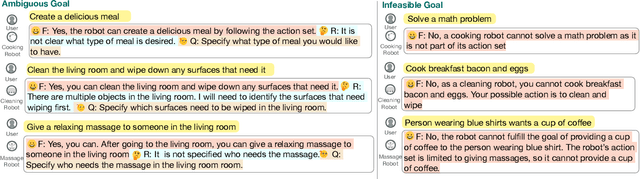
In this paper, we focus on inferring whether the given user command is clear, ambiguous, or infeasible in the context of interactive robotic agents utilizing large language models (LLMs). To tackle this problem, we first present an uncertainty estimation method for LLMs to classify whether the command is certain (i.e., clear) or not (i.e., ambiguous or infeasible). Once the command is classified as uncertain, we further distinguish it between ambiguous or infeasible commands leveraging LLMs with situational aware context in a zero-shot manner. For ambiguous commands, we disambiguate the command by interacting with users via question generation with LLMs. We believe that proper recognition of the given commands could lead to a decrease in malfunction and undesired actions of the robot, enhancing the reliability of interactive robot agents. We present a dataset for robotic situational awareness, consisting pair of high-level commands, scene descriptions, and labels of command type (i.e., clear, ambiguous, or infeasible). We validate the proposed method on the collected dataset, pick-and-place tabletop simulation. Finally, we demonstrate the proposed approach in real-world human-robot interaction experiments, i.e., handover scenarios.
Trajectory-based Reinforcement Learning of Non-prehensile Manipulation Skills for Semi-Autonomous Teleoperation
Sep 27, 2021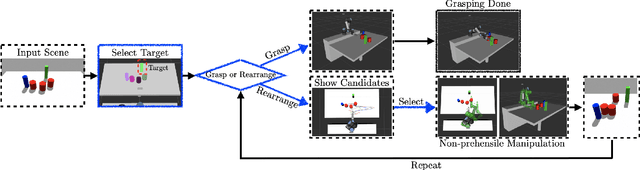

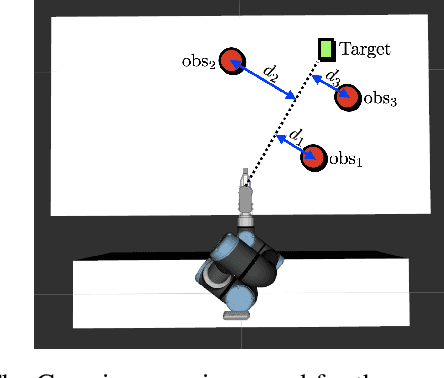

In this paper, we present a semi-autonomous teleoperation framework for a pick-and-place task using an RGB-D sensor. In particular, we assume that the target object is located in a cluttered environment where both prehensile grasping and non-prehensile manipulation are combined for efficient teleoperation. A trajectory-based reinforcement learning is utilized for learning the non-prehensile manipulation to rearrange the objects for enabling direct grasping. From the depth image of the cluttered environment and the location of the goal object, the learned policy can provide multiple options of non-prehensile manipulation to the human operator. We carefully design a reward function for the rearranging task where the policy is trained in a simulational environment. Then, the trained policy is transferred to a real-world and evaluated in a number of real-world experiments with the varying number of objects where we show that the proposed method outperforms manual keyboard control in terms of the time duration for the grasping.