 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearning the Unpromptable: Prompt-free Instance Unlearning in Diffusion Models
Mar 12, 2026Machine unlearning aims to remove specific outputs from trained models, often at the concept level, such as forgetting all occurrences of a particular celebrity or filtering content via text prompts. However, many undesired outputs, such as an individual's face or generations culturally or factually misinterpreted, cannot often be specified by text prompts. We address this underexplored setting of instance unlearning for outputs that are undesired but unpromptable, where the goal is to forget target outputs selectively while preserving the rest. To this end, we introduce an effective surrogate-based unlearning method that leverages image editing, timestep-aware weighting, and gradient surgery to guide trained diffusion models toward forgetting specific outputs. Experiments on conditional (Stable Diffusion 3) and unconditional (DDPM-CelebA) diffusion models demonstrate that our prompt-free method uniquely unlearns unpromptable outputs, such as faces and culturally inaccurate depictions, with preserved integrity, unlike prompt-based and prompt-free baselines. Our proposed method would serve as a practical hotfix for diffusion model providers to ensure privacy protection and ethical compliance.
Continual Multiple Instance Learning with Enhanced Localization for Histopathological Whole Slide Image Analysis
Jul 03, 2025
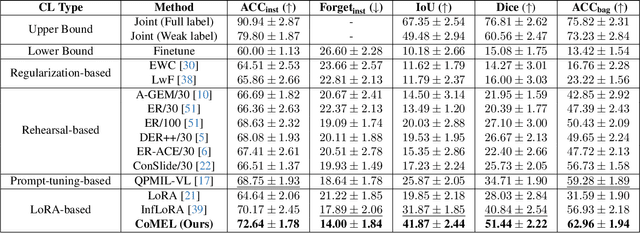
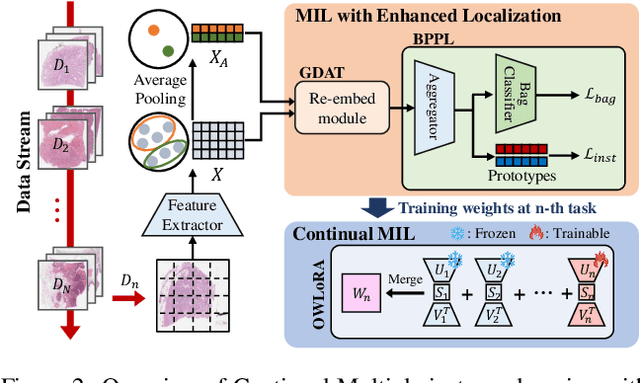
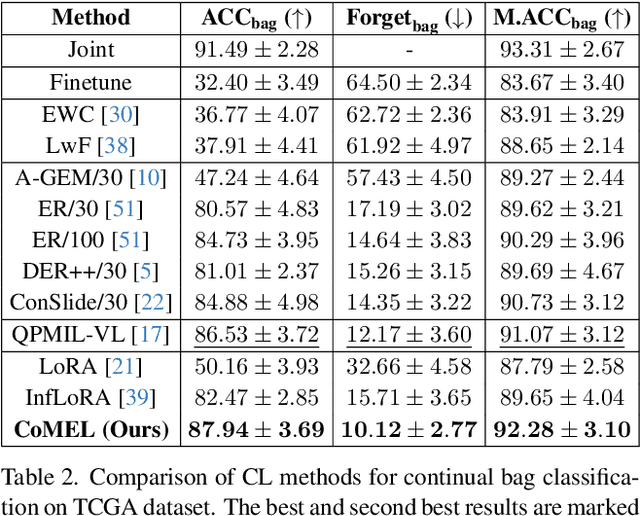
Multiple instance learning (MIL) significantly reduced annotation costs via bag-level weak labels for large-scale images, such as histopathological whole slide images (WSIs). However, its adaptability to continual tasks with minimal forgetting has been rarely explored, especially on instance classification for localization. Weakly incremental learning for semantic segmentation has been studied for continual localization, but it focused on natural images, leveraging global relationships among hundreds of small patches (e.g., $16 \times 16$) using pre-trained models. This approach seems infeasible for MIL localization due to enormous amounts ($\sim 10^5$) of large patches (e.g., $256 \times 256$) and no available global relationships such as cancer cells. To address these challenges, we propose Continual Multiple Instance Learning with Enhanced Localization (CoMEL), an MIL framework for both localization and adaptability with minimal forgetting. CoMEL consists of (1) Grouped Double Attention Transformer (GDAT) for efficient instance encoding, (2) Bag Prototypes-based Pseudo-Labeling (BPPL) for reliable instance pseudo-labeling, and (3) Orthogonal Weighted Low-Rank Adaptation (OWLoRA) to mitigate forgetting in both bag and instance classification. Extensive experiments on three public WSI datasets demonstrate superior performance of CoMEL, outperforming the prior arts by up to $11.00\%$ in bag-level accuracy and up to $23.4\%$ in localization accuracy under the continual MIL setup.
On Geometrical Properties of Text Token Embeddings for Strong Semantic Binding in Text-to-Image Generation
Mar 29, 2025Text-to-Image (T2I) models often suffer from text-image misalignment in complex scenes involving multiple objects and attributes. Semantic binding aims to mitigate this issue by accurately associating the generated attributes and objects with their corresponding noun phrases (NPs). Existing methods rely on text or latent optimizations, yet the factors influencing semantic binding remain underexplored. Here we investigate the geometrical properties of text token embeddings and their cross-attention (CA) maps. We empirically and theoretically analyze that the geometrical properties of token embeddings, specifically both angular distances and norms, play a crucial role in CA map differentiation. Then, we propose \textbf{TeeMo}, a training-free text embedding-aware T2I framework with strong semantic binding. TeeMo consists of Causality-Aware Projection-Out (CAPO) for distinct inter-NP CA maps and Adaptive Token Mixing (ATM) with our loss to enhance inter-NP separation while maintaining intra-NP cohesion in CA maps. Extensive experiments confirm TeeMo consistently outperforms prior arts across diverse baselines and datasets.
Localized Concept Erasure for Text-to-Image Diffusion Models Using Training-Free Gated Low-Rank Adaptation
Mar 16, 2025
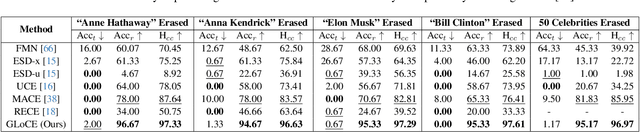

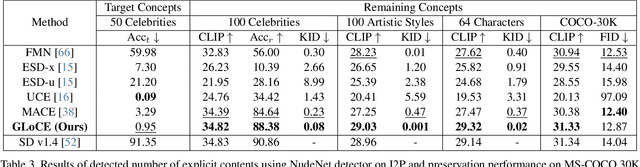
Fine-tuning based concept erasing has demonstrated promising results in preventing generation of harmful contents from text-to-image diffusion models by removing target concepts while preserving remaining concepts. To maintain the generation capability of diffusion models after concept erasure, it is necessary to remove only the image region containing the target concept when it locally appears in an image, leaving other regions intact. However, prior arts often compromise fidelity of the other image regions in order to erase the localized target concept appearing in a specific area, thereby reducing the overall performance of image generation. To address these limitations, we first introduce a framework called localized concept erasure, which allows for the deletion of only the specific area containing the target concept in the image while preserving the other regions. As a solution for the localized concept erasure, we propose a training-free approach, dubbed Gated Low-rank adaptation for Concept Erasure (GLoCE), that injects a lightweight module into the diffusion model. GLoCE consists of low-rank matrices and a simple gate, determined only by several generation steps for concepts without training. By directly applying GLoCE to image embeddings and designing the gate to activate only for target concepts, GLoCE can selectively remove only the region of the target concepts, even when target and remaining concepts coexist within an image. Extensive experiments demonstrated GLoCE not only improves the image fidelity to text prompts after erasing the localized target concepts, but also outperforms prior arts in efficacy, specificity, and robustness by large margin and can be extended to mass concept erasure.
Doubly Perturbed Task-Free Continual Learning
Dec 20, 2023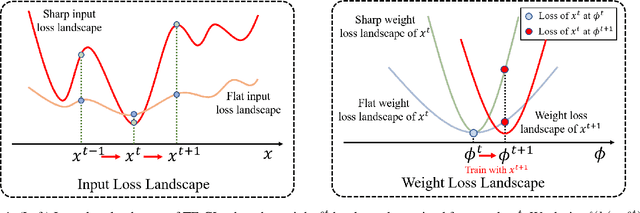

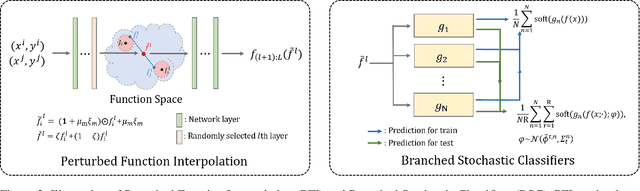

Task-free online continual learning (TF-CL) is a challenging problem where the model incrementally learns tasks without explicit task information. Although training with entire data from the past, present as well as future is considered as the gold standard, naive approaches in TF-CL with the current samples may be conflicted with learning with samples in the future, leading to catastrophic forgetting and poor plasticity. Thus, a proactive consideration of an unseen future sample in TF-CL becomes imperative. Motivated by this intuition, we propose a novel TF-CL framework considering future samples and show that injecting adversarial perturbations on both input data and decision-making is effective. Then, we propose a novel method named Doubly Perturbed Continual Learning (DPCL) to efficiently implement these input and decision-making perturbations. Specifically, for input perturbation, we propose an approximate perturbation method that injects noise into the input data as well as the feature vector and then interpolates the two perturbed samples. For decision-making process perturbation, we devise multiple stochastic classifiers. We also investigate a memory management scheme and learning rate scheduling reflecting our proposed double perturbations. We demonstrate that our proposed method outperforms the state-of-the-art baseline methods by large margins on various TF-CL benchmarks.
Online Continual Learning on Hierarchical Label Expansion
Aug 28, 2023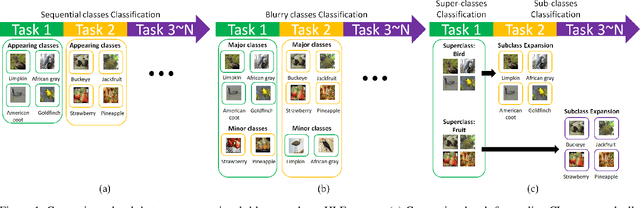
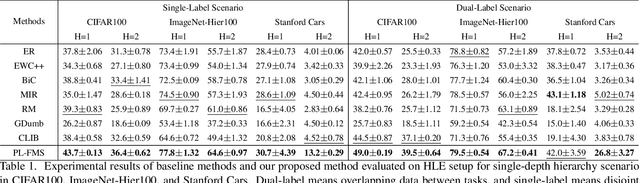

Continual learning (CL) enables models to adapt to new tasks and environments without forgetting previously learned knowledge. While current CL setups have ignored the relationship between labels in the past task and the new task with or without small task overlaps, real-world scenarios often involve hierarchical relationships between old and new tasks, posing another challenge for traditional CL approaches. To address this challenge, we propose a novel multi-level hierarchical class incremental task configuration with an online learning constraint, called hierarchical label expansion (HLE). Our configuration allows a network to first learn coarse-grained classes, with data labels continually expanding to more fine-grained classes in various hierarchy depths. To tackle this new setup, we propose a rehearsal-based method that utilizes hierarchy-aware pseudo-labeling to incorporate hierarchical class information. Additionally, we propose a simple yet effective memory management and sampling strategy that selectively adopts samples of newly encountered classes. Our experiments demonstrate that our proposed method can effectively use hierarchy on our HLE setup to improve classification accuracy across all levels of hierarchies, regardless of depth and class imbalance ratio, outperforming prior state-of-the-art works by significant margins while also outperforming them on the conventional disjoint, blurry and i-Blurry CL setups.
Speeding up scaled gradient projection methods using deep neural networks for inverse problems in image processing
Feb 07, 2019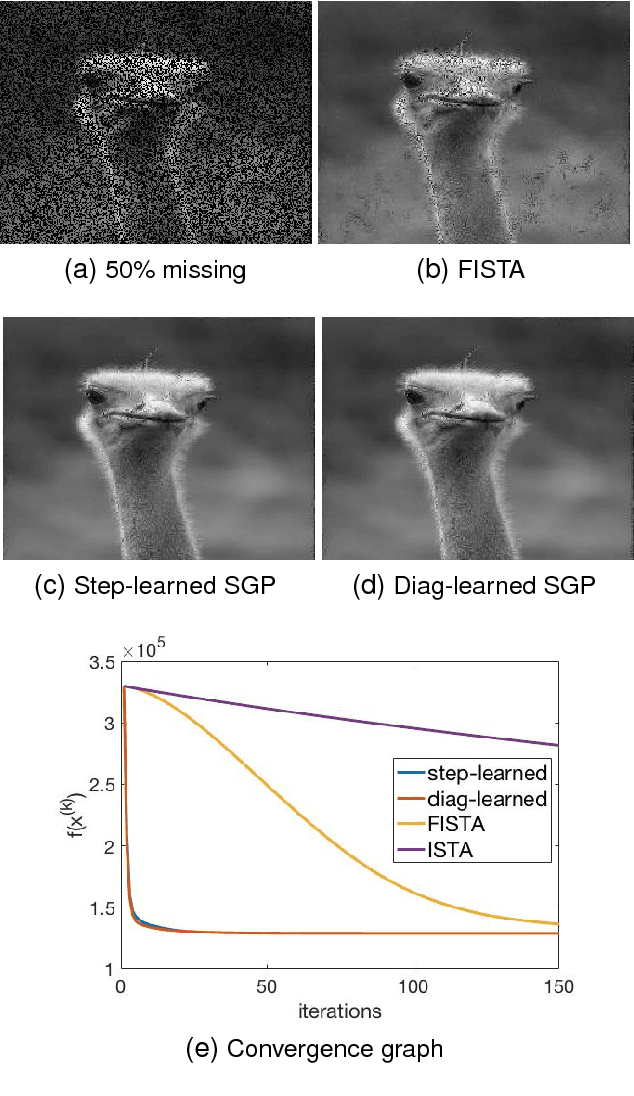
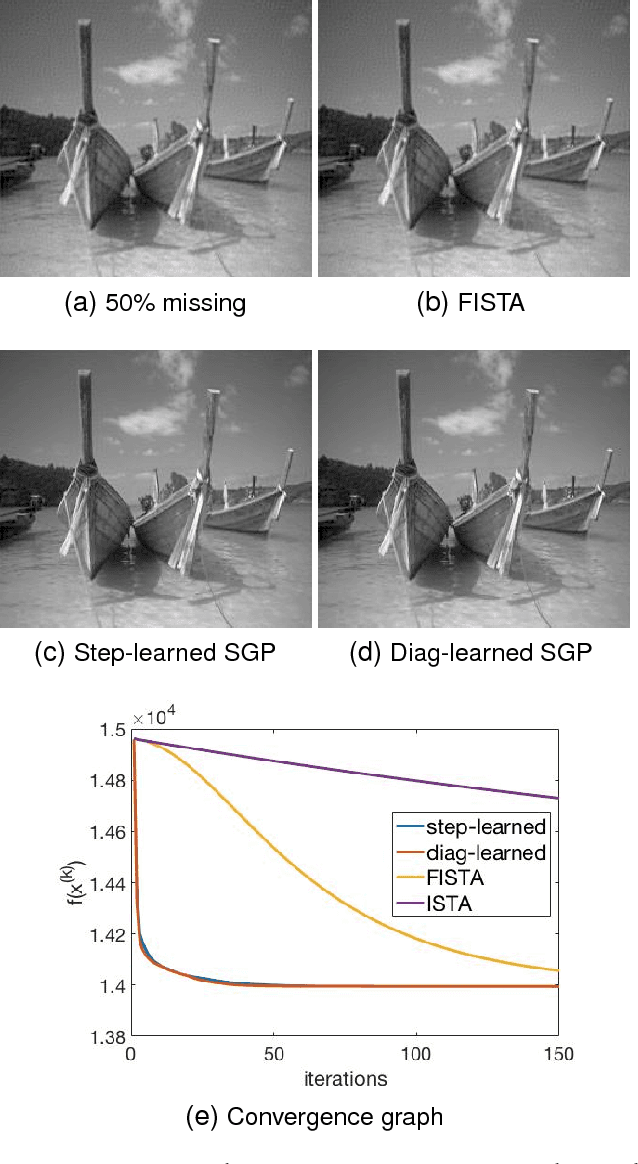
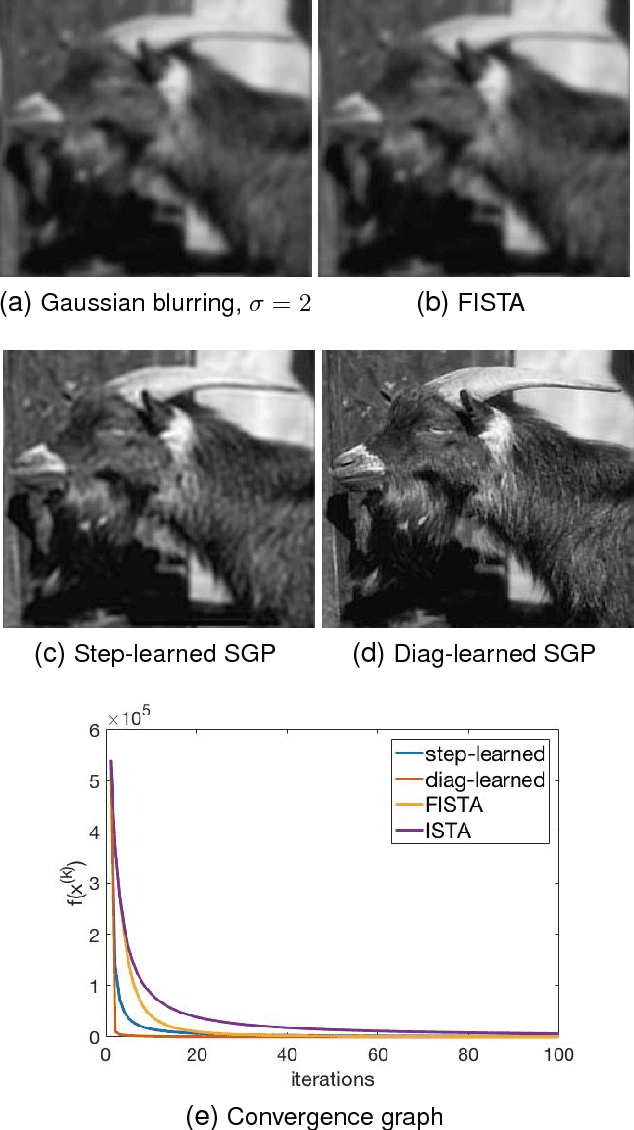
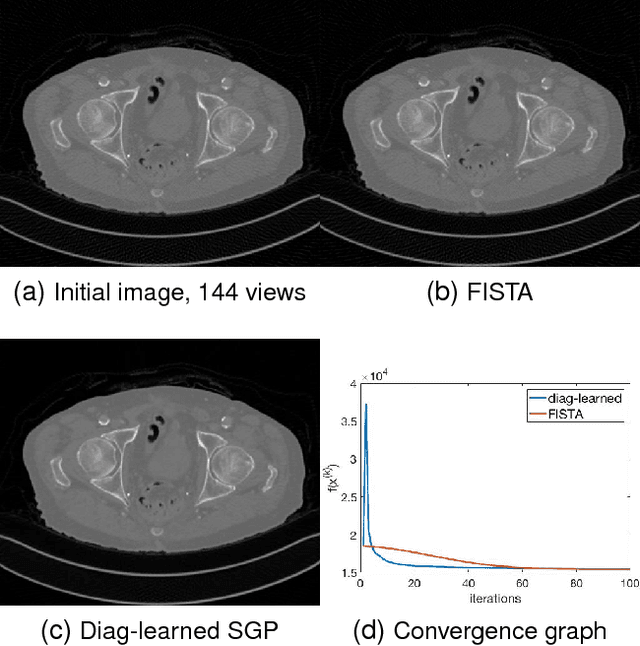
Conventional optimization based methods have utilized forward models with image priors to solve inverse problems in image processing. Recently, deep neural networks (DNN) have been investigated to significantly improve the image quality of the solution for inverse problems. Most DNN based inverse problems have focused on using data-driven image priors with massive amount of data. However, these methods often do not inherit nice properties of conventional approaches using theoretically well-grounded optimization algorithms such as monotone, global convergence. Here we investigate another possibility of using DNN for inverse problems in image processing. We propose methods to use DNNs to seamlessly speed up convergence rates of conventional optimization based methods. Our DNN-incorporated scaled gradient projection methods, without breaking theoretical properties, significantly improved convergence speed over state-of-the-art conventional optimization methods such as ISTA or FISTA in practice for inverse problems such as image inpainting, compressive image recovery with partial Fourier samples, image deblurring, and medical image reconstruction with sparse-view projections.