 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkrr: Skip and Re-use Text Encoder Layers for Memory Efficient Text-to-Image Generation
Paper and Code
Feb 12, 2025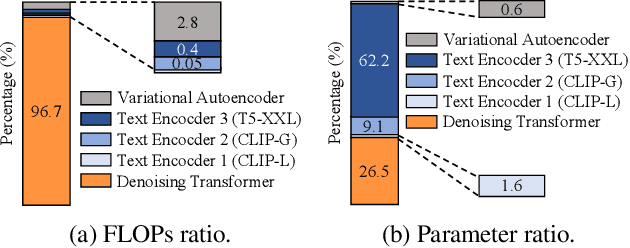
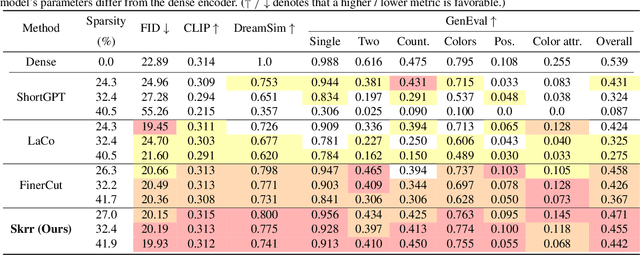
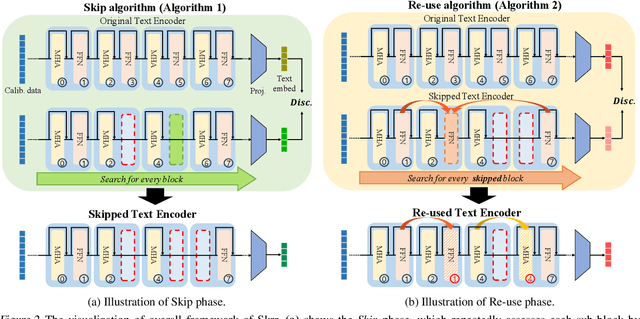
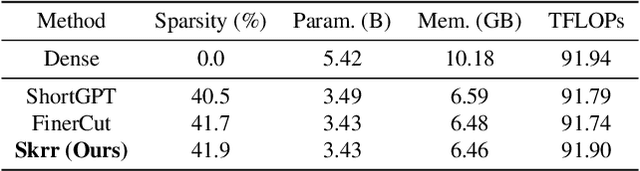
Large-scale text encoders in text-to-image (T2I) diffusion models have demonstrated exceptional performance in generating high-quality images from textual prompts. Unlike denoising modules that rely on multiple iterative steps, text encoders require only a single forward pass to produce text embeddings. However, despite their minimal contribution to total inference time and floating-point operations (FLOPs), text encoders demand significantly higher memory usage, up to eight times more than denoising modules. To address this inefficiency, we propose Skip and Re-use layers (Skrr), a simple yet effective pruning strategy specifically designed for text encoders in T2I diffusion models. Skrr exploits the inherent redundancy in transformer blocks by selectively skipping or reusing certain layers in a manner tailored for T2I tasks, thereby reducing memory consumption without compromising performance. Extensive experiments demonstrate that Skrr maintains image quality comparable to the original model even under high sparsity levels, outperforming existing blockwise pruning methods. Furthermore, Skrr achieves state-of-the-art memory efficiency while preserving performance across multiple evaluation metrics, including the FID, CLIP, DreamSim, and GenEval scores.