 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoForce: Robust Online Egocentric Motion Reconstruction via Diffusion Forcing
May 13, 2026With recent advances in embodied agents and AR devices, egocentric observations are readily available as input for real-world interactive online applications. However, egocentric viewpoints can only sporadically observe hands, in addition to the estimated head trajectory. We propose EgoForce, an online framework for reconstructing long-term full-body motion from noisy egocentric input. While existing generative frameworks can robustly handle noisy and sparse measurements, they assume a fixed-length observation window is available and are thus not suitable for real-time applications. Faster inference often relies on autoregressive prediction, sacrificing robustness. In contrast, we adopt a diffusion-based method with a temporally asymmetric noise schedule inspired by Diffusion Forcing. Specifically, our approach models temporally evolving uncertainty and incrementally denoises states as new streaming observations arrive. Combined with a noise-robust imputation strategy, EgoForce progressively generates stable and coherent full-body motion under strict causal constraints. Experiments demonstrate that our online framework outperforms existing online and offline methods, enabling long-horizon, full-body motion reconstruction in challenging egocentric scenarios.
ScaleMoGen: Autoregressive Next-Scale Prediction for Human Motion Generation
May 12, 2026We present ScaleMoGen, a scale-wise autoregressive framework for text-driven human motion generation. Unlike conventional autoregressive approaches that rely on standard next-token prediction, ScaleMoGen frames motion generation as a coarse-to-fine process. We quantize 3D motions into compositional discrete tokens across multiple skeletal-emporal scales of increasing granularity, learning to generate motion by autoregressively predicting next-scale token maps. To maintain structural integrity, our motion tokenizers and quantizers are explicitly designed so that discrete tokens at every scale strictly preserve the skeletal hierarchy. Additionally, we employ bitwise quantization and prediction, which efficiently scale up the tokenizer vocabulary to preserve motion details and stabilize optimization. Extensive experiments demonstrate that ScaleMoGen achieves state-of-the-art performance, establishing an FID of 0.030 (vs. 0.045 for MoMask) on HumanML3D and a CLIP Score of 0.693 (vs. 0.685 for MoMask++) on the SnapMoGen dataset. Furthermore, we demonstrate that our skeletal-temporal multi-scale representation naturally facilitates training-free, text-guided motion editing.
ReMP: Reusable Motion Prior for Multi-domain 3D Human Pose Estimation and Motion Inbetweening
Nov 13, 2024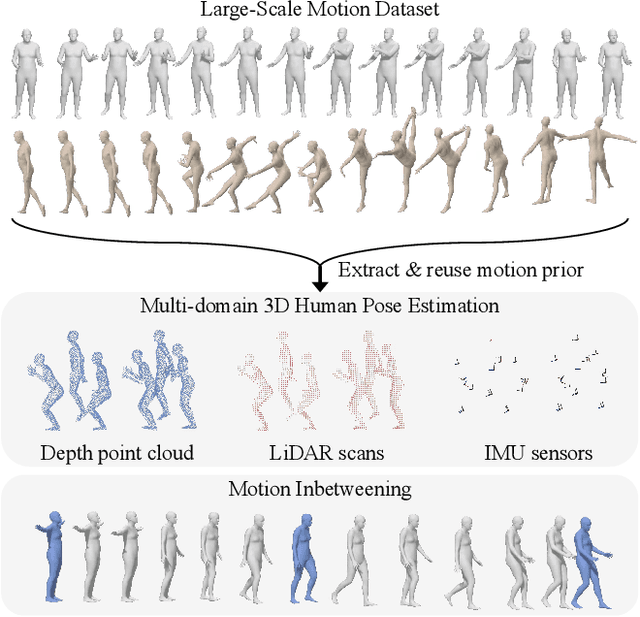
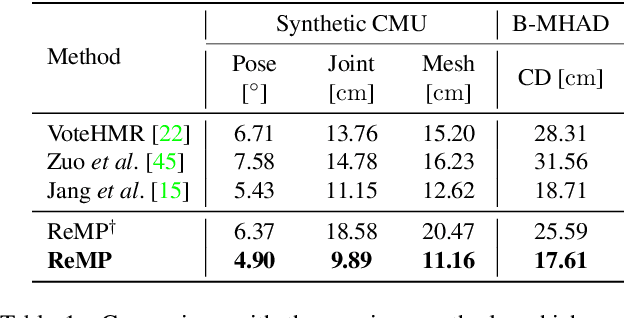
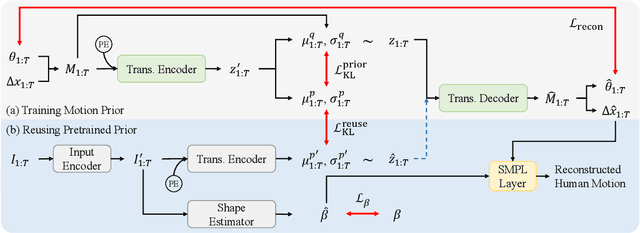
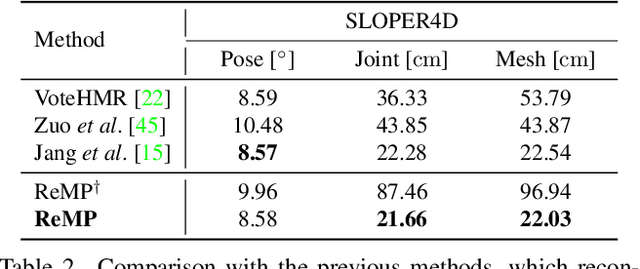
We present Reusable Motion prior (ReMP), an effective motion prior that can accurately track the temporal evolution of motion in various downstream tasks. Inspired by the success of foundation models, we argue that a robust spatio-temporal motion prior can encapsulate underlying 3D dynamics applicable to various sensor modalities. We learn the rich motion prior from a sequence of complete parametric models of posed human body shape. Our prior can easily estimate poses in missing frames or noisy measurements despite significant occlusion by employing a temporal attention mechanism. More interestingly, our prior can guide the system with incomplete and challenging input measurements to quickly extract critical information to estimate the sequence of poses, significantly improving the training efficiency for mesh sequence recovery. ReMP consistently outperforms the baseline method on diverse and practical 3D motion data, including depth point clouds, LiDAR scans, and IMU sensor data. Project page is available in https://hojunjang17.github.io/ReMP.
LDL: Line Distance Functions for Panoramic Localization
Aug 27, 2023



We introduce LDL, a fast and robust algorithm that localizes a panorama to a 3D map using line segments. LDL focuses on the sparse structural information of lines in the scene, which is robust to illumination changes and can potentially enable efficient computation. While previous line-based localization approaches tend to sacrifice accuracy or computation time, our method effectively observes the holistic distribution of lines within panoramic images and 3D maps. Specifically, LDL matches the distribution of lines with 2D and 3D line distance functions, which are further decomposed along principal directions of lines to increase the expressiveness. The distance functions provide coarse pose estimates by comparing the distributional information, where the poses are further optimized using conventional local feature matching. As our pipeline solely leverages line geometry and local features, it does not require costly additional training of line-specific features or correspondence matching. Nevertheless, our method demonstrates robust performance on challenging scenarios including object layout changes, illumination shifts, and large-scale scenes, while exhibiting fast pose search terminating within a matter of milliseconds. We thus expect our method to serve as a practical solution for line-based localization, and complement the well-established point-based paradigm. The code for LDL is available through the following link: https://github.com/82magnolia/panoramic-localization.
CPO: Change Robust Panorama to Point Cloud Localization
Jul 12, 2022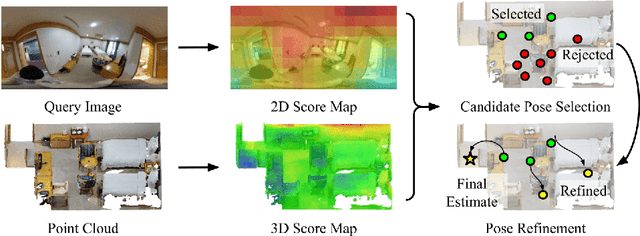
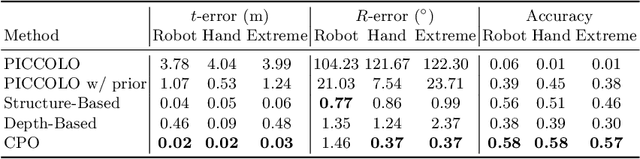

We present CPO, a fast and robust algorithm that localizes a 2D panorama with respect to a 3D point cloud of a scene possibly containing changes. To robustly handle scene changes, our approach deviates from conventional feature point matching, and focuses on the spatial context provided from panorama images. Specifically, we propose efficient color histogram generation and subsequent robust localization using score maps. By utilizing the unique equivariance of spherical projections, we propose very fast color histogram generation for a large number of camera poses without explicitly rendering images for all candidate poses. We accumulate the regional consistency of the panorama and point cloud as 2D/3D score maps, and use them to weigh the input color values to further increase robustness. The weighted color distribution quickly finds good initial poses and achieves stable convergence for gradient-based optimization. CPO is lightweight and achieves effective localization in all tested scenarios, showing stable performance despite scene changes, repetitive structures, or featureless regions, which are typical challenges for visual localization with perspective cameras.
Neural Marionette: Unsupervised Learning of Motion Skeleton and Latent Dynamics from Volumetric Video
Feb 17, 2022We present Neural Marionette, an unsupervised approach that discovers the skeletal structure from a dynamic sequence and learns to generate diverse motions that are consistent with the observed motion dynamics. Given a video stream of point cloud observation of an articulated body under arbitrary motion, our approach discovers the unknown low-dimensional skeletal relationship that can effectively represent the movement. Then the discovered structure is utilized to encode the motion priors of dynamic sequences in a latent structure, which can be decoded to the relative joint rotations to represent the full skeletal motion. Our approach works without any prior knowledge of the underlying motion or skeletal structure, and we demonstrate that the discovered structure is even comparable to the hand-labeled ground truth skeleton in representing a 4D sequence of motion. The skeletal structure embeds the general semantics of possible motion space that can generate motions for diverse scenarios. We verify that the learned motion prior is generalizable to the multi-modal sequence generation, interpolation of two poses, and motion retargeting to a different skeletal structure.
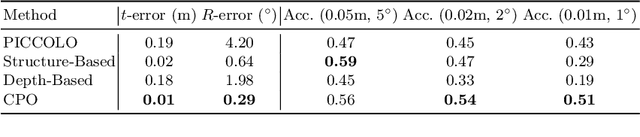
PICCOLO: Point Cloud-Centric Omnidirectional Localization
Aug 14, 2021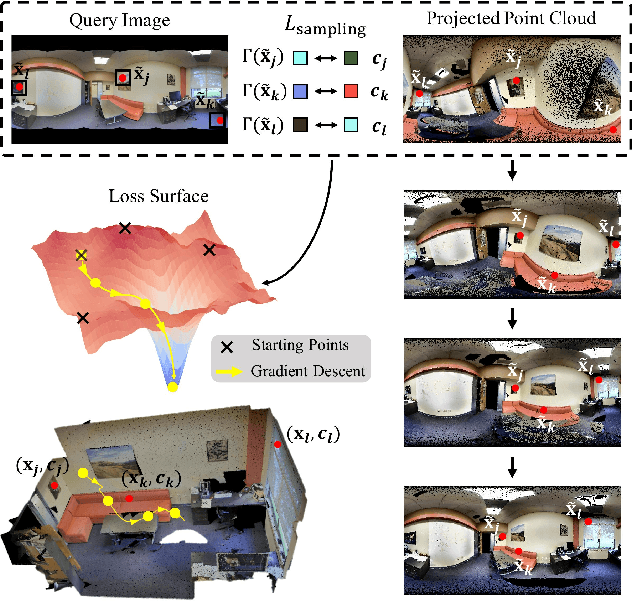
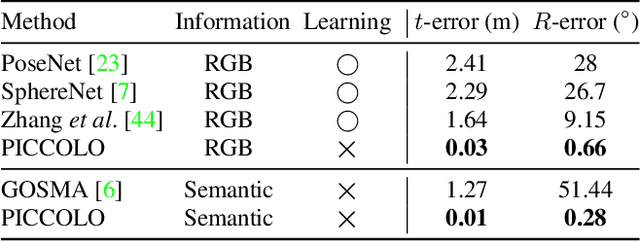


We present PICCOLO, a simple and efficient algorithm for omnidirectional localization. Given a colored point cloud and a 360 panorama image of a scene, our objective is to recover the camera pose at which the panorama image is taken. Our pipeline works in an off-the-shelf manner with a single image given as a query and does not require any training of neural networks or collecting ground-truth poses of images. Instead, we match each point cloud color to the holistic view of the panorama image with gradient-descent optimization to find the camera pose. Our loss function, called sampling loss, is point cloud-centric, evaluated at the projected location of every point in the point cloud. In contrast, conventional photometric loss is image-centric, comparing colors at each pixel location. With a simple change in the compared entities, sampling loss effectively overcomes the severe visual distortion of omnidirectional images, and enjoys the global context of the 360 view to handle challenging scenarios for visual localization. PICCOLO outperforms existing omnidirectional localization algorithms in both accuracy and stability when evaluated in various environments.