 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTetWeave: Isosurface Extraction using On-The-Fly Delaunay Tetrahedral Grids for Gradient-Based Mesh Optimization
May 08, 2025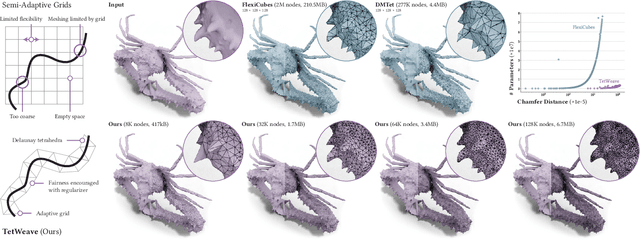
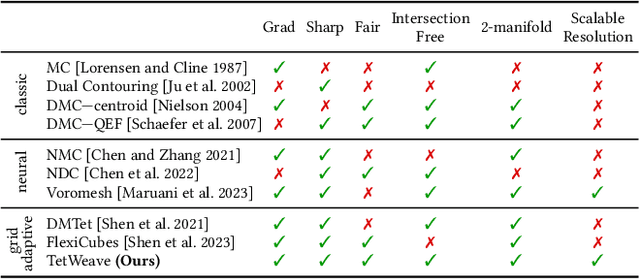


We introduce TetWeave, a novel isosurface representation for gradient-based mesh optimization that jointly optimizes the placement of a tetrahedral grid used for Marching Tetrahedra and a novel directional signed distance at each point. TetWeave constructs tetrahedral grids on-the-fly via Delaunay triangulation, enabling increased flexibility compared to predefined grids. The extracted meshes are guaranteed to be watertight, two-manifold and intersection-free. The flexibility of TetWeave enables a resampling strategy that places new points where reconstruction error is high and allows to encourage mesh fairness without compromising on reconstruction error. This leads to high-quality, adaptive meshes that require minimal memory usage and few parameters to optimize. Consequently, TetWeave exhibits near-linear memory scaling relative to the vertex count of the output mesh - a substantial improvement over predefined grids. We demonstrate the applicability of TetWeave to a broad range of challenging tasks in computer graphics and vision, such as multi-view 3D reconstruction, mesh compression and geometric texture generation.
Fast and Uncertainty-Aware SVBRDF Recovery from Multi-View Capture using Frequency Domain Analysis
Jun 25, 2024



Relightable object acquisition is a key challenge in simplifying digital asset creation. Complete reconstruction of an object typically requires capturing hundreds to thousands of photographs under controlled illumination, with specialized equipment. The recent progress in differentiable rendering improved the quality and accessibility of inverse rendering optimization. Nevertheless, under uncontrolled illumination and unstructured viewpoints, there is no guarantee that the observations contain enough information to reconstruct the appearance properties of the captured object. We thus propose to consider the acquisition process from a signal-processing perspective. Given an object's geometry and a lighting environment, we estimate the properties of the materials on the object's surface in seconds. We do so by leveraging frequency domain analysis, considering the recovery of material properties as a deconvolution, enabling fast error estimation. We then quantify the uncertainty of the estimation, based on the available data, highlighting the areas for which priors or additional samples would be required for improved acquisition quality. We compare our approach to previous work and quantitatively evaluate our results, showing similar quality as previous work in a fraction of the time, and providing key information about the certainty of the results.
Deep vanishing point detection: Geometric priors make dataset variations vanish
Mar 16, 2022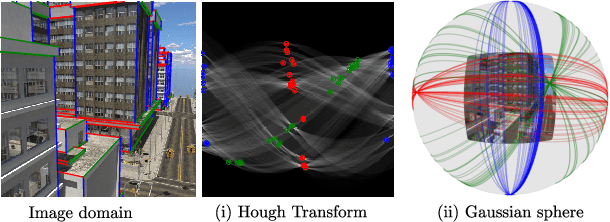
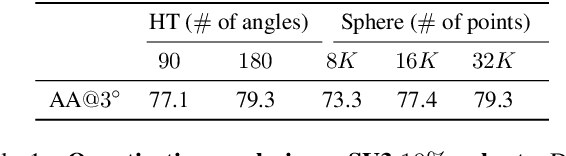
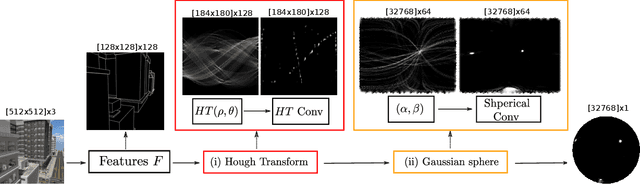
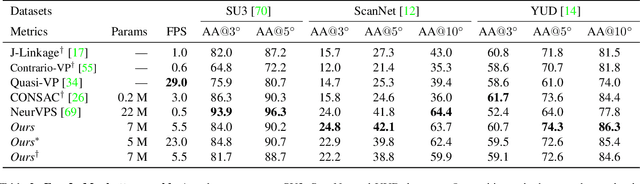
Deep learning has improved vanishing point detection in images. Yet, deep networks require expensive annotated datasets trained on costly hardware and do not generalize to even slightly different domains, and minor problem variants. Here, we address these issues by injecting deep vanishing point detection networks with prior knowledge. This prior knowledge no longer needs to be learned from data, saving valuable annotation efforts and compute, unlocking realistic few-sample scenarios, and reducing the impact of domain changes. Moreover, the interpretability of the priors allows to adapt deep networks to minor problem variations such as switching between Manhattan and non-Manhattan worlds. We seamlessly incorporate two geometric priors: (i) Hough Transform -- mapping image pixels to straight lines, and (ii) Gaussian sphere -- mapping lines to great circles whose intersections denote vanishing points. Experimentally, we ablate our choices and show comparable accuracy to existing models in the large-data setting. We validate our model's improved data efficiency, robustness to domain changes, adaptability to non-Manhattan settings.
DeltaConv: Anisotropic Point Cloud Learning with Exterior Calculus
Nov 23, 2021
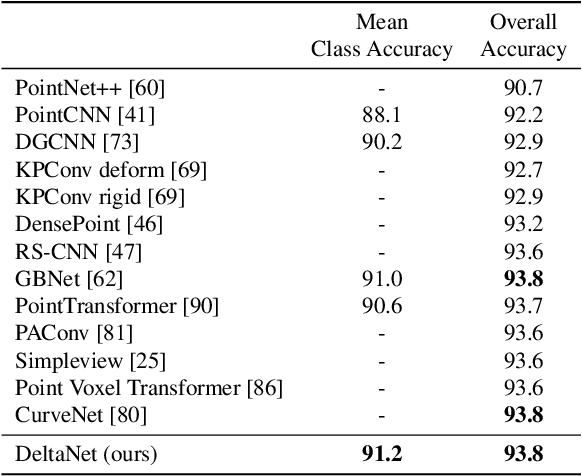

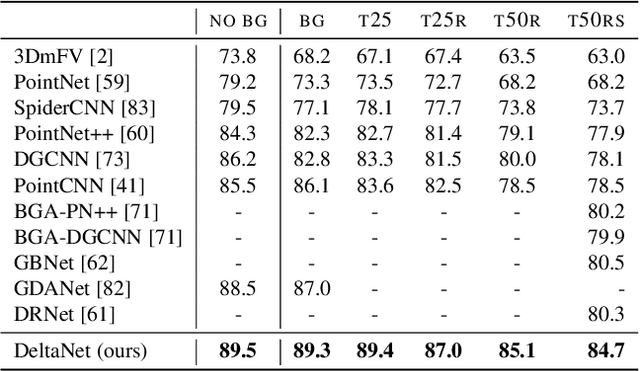
Learning from 3D point-cloud data has rapidly gained momentum, motivated by the success of deep learning on images and the increased availability of 3D data. In this paper, we aim to construct anisotropic convolutions that work directly on the surface derived from a point cloud. This is challenging because of the lack of a global coordinate system for tangential directions on surfaces. We introduce a new convolution operator called DeltaConv, which combines geometric operators from exterior calculus to enable the construction of anisotropic filters on point clouds. Because these operators are defined on scalar- and vector-fields, we separate the network into a scalar- and a vector-stream, which are connected by the operators. The vector stream enables the network to explicitly represent, evaluate, and process directional information. Our convolutions are robust and simple to implement and show improved accuracy compared to state-of-the-art approaches on several benchmarks, while also speeding up training and inference.
CNNs on Surfaces using Rotation-Equivariant Features
Jun 02, 2020
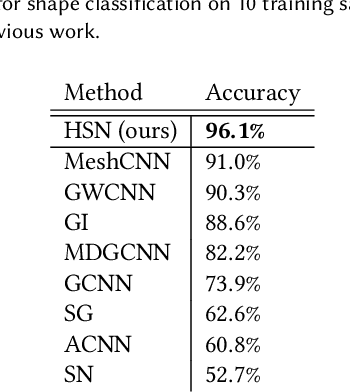

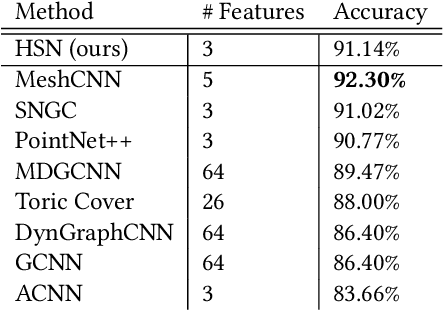
This paper is concerned with a fundamental problem in geometric deep learning that arises in the construction of convolutional neural networks on surfaces. Due to curvature, the transport of filter kernels on surfaces results in a rotational ambiguity, which prevents a uniform alignment of these kernels on the surface. We propose a network architecture for surfaces that consists of vector-valued, rotation-equivariant features. The equivariance property makes it possible to locally align features, which were computed in arbitrary coordinate systems, when aggregating features in a convolution layer. The resulting network is agnostic to the choices of coordinate systems for the tangent spaces on the surface. We implement our approach for triangle meshes. Based on circular harmonic functions, we introduce convolution filters for meshes that are rotation-equivariant at the discrete level. We evaluate the resulting networks on shape correspondence and shape classifications tasks and compare their performance to other approaches.