 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLucid Data Dreaming for Multiple Object Tracking
Paper and Code
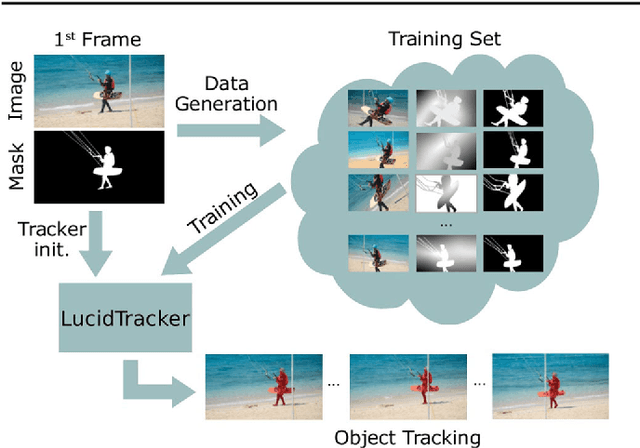



Convolutional networks reach top quality in pixel-level object tracking but require a large amount of training data (1k~10k) to deliver such results. We propose a new training strategy which achieves state-of-the-art results across three evaluation datasets while using 20x~100x less annotated data than competing methods. Our approach is suitable for both single and multiple object tracking. Instead of using large training sets hoping to generalize across domains, we generate in-domain training data using the provided annotation on the first frame of each video to synthesize ("lucid dream") plausible future video frames. In-domain per-video training data allows us to train high quality appearance- and motion-based models, as well as tune the post-processing stage. This approach allows to reach competitive results even when training from only a single annotated frame, without ImageNet pre-training. Our results indicate that using a larger training set is not automatically better, and that for the tracking task a smaller training set that is closer to the target domain is more effective. This changes the mindset regarding how many training samples and general "objectness" knowledge are required for the object tracking task.