 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearchAD: Large-Scale Rare Image Retrieval Dataset for Autonomous Driving
Apr 09, 2026Retrieving rare and safety-critical driving scenarios from large-scale datasets is essential for building robust autonomous driving (AD) systems. As dataset sizes continue to grow, the key challenge shifts from collecting more data to efficiently identifying the most relevant samples. We introduce SearchAD, a large-scale rare image retrieval dataset for AD containing over 423k frames drawn from 11 established datasets. SearchAD provides high-quality manual annotations of more than 513k bounding boxes covering 90 rare categories. It specifically targets the needle-in-a-haystack problem of locating extremely rare classes, with some appearing fewer than 50 times across the entire dataset. Unlike existing benchmarks, which focused on instance-level retrieval, SearchAD emphasizes semantic image retrieval with a well-defined data split, enabling text-to-image and image-to-image retrieval, few-shot learning, and fine-tuning of multi-modal retrieval models. Comprehensive evaluations show that text-based methods outperform image-based ones due to stronger inherent semantic grounding. While models directly aligning spatial visual features with language achieve the best zero-shot results, and our fine-tuning baseline significantly improves performance, absolute retrieval capabilities remain unsatisfactory. With a held-out test set on a public benchmark server, SearchAD establishes the first large-scale dataset for retrieval-driven data curation and long-tail perception research in AD: https://iis-esslingen.github.io/searchad/
Sparsity Invariant CNNs
Aug 30, 2017
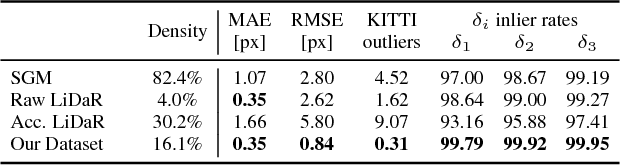

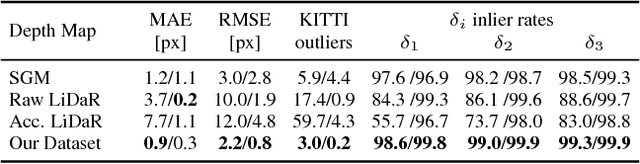
In this paper, we consider convolutional neural networks operating on sparse inputs with an application to depth upsampling from sparse laser scan data. First, we show that traditional convolutional networks perform poorly when applied to sparse data even when the location of missing data is provided to the network. To overcome this problem, we propose a simple yet effective sparse convolution layer which explicitly considers the location of missing data during the convolution operation. We demonstrate the benefits of the proposed network architecture in synthetic and real experiments with respect to various baseline approaches. Compared to dense baselines, the proposed sparse convolution network generalizes well to novel datasets and is invariant to the level of sparsity in the data. For our evaluation, we derive a novel dataset from the KITTI benchmark, comprising 93k depth annotated RGB images. Our dataset allows for training and evaluating depth upsampling and depth prediction techniques in challenging real-world settings and will be made available upon publication.
DeMoN: Depth and Motion Network for Learning Monocular Stereo
Apr 11, 2017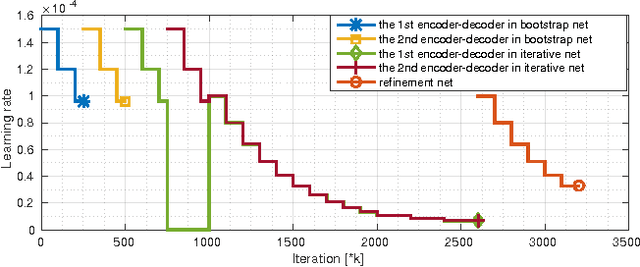


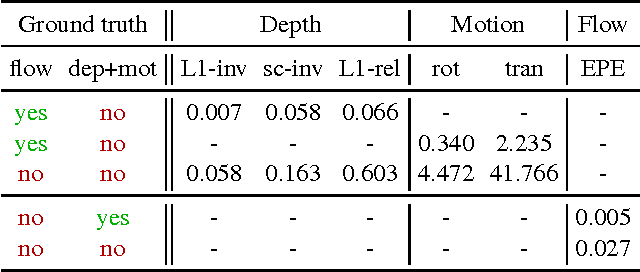
In this paper we formulate structure from motion as a learning problem. We train a convolutional network end-to-end to compute depth and camera motion from successive, unconstrained image pairs. The architecture is composed of multiple stacked encoder-decoder networks, the core part being an iterative network that is able to improve its own predictions. The network estimates not only depth and motion, but additionally surface normals, optical flow between the images and confidence of the matching. A crucial component of the approach is a training loss based on spatial relative differences. Compared to traditional two-frame structure from motion methods, results are more accurate and more robust. In contrast to the popular depth-from-single-image networks, DeMoN learns the concept of matching and, thus, better generalizes to structures not seen during training.
Joint Graph Decomposition and Node Labeling: Problem, Algorithms, Applications
Feb 21, 2017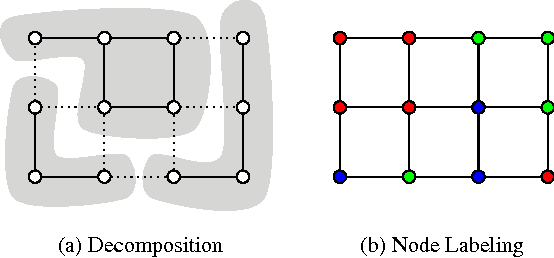
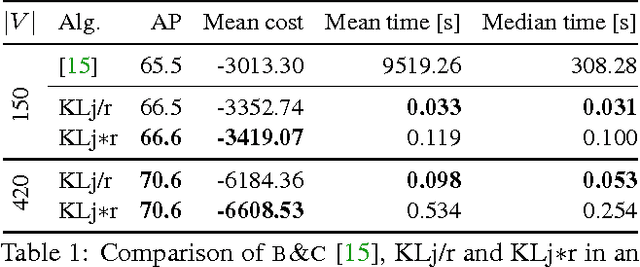
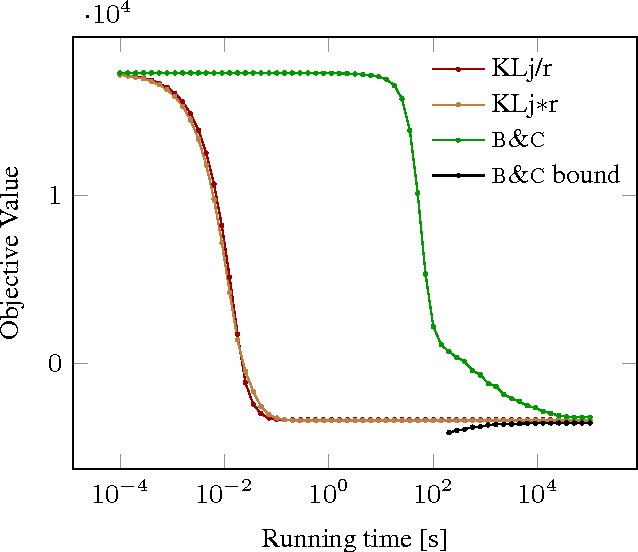
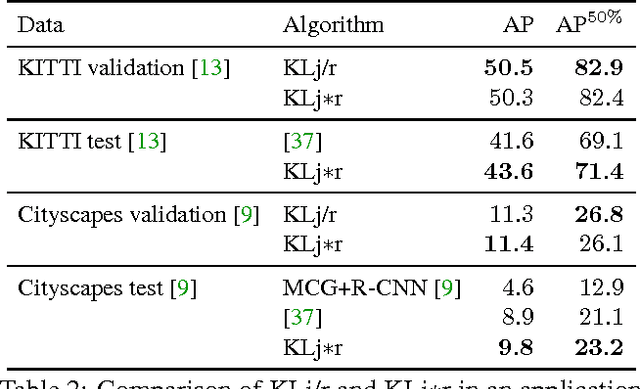
We state a combinatorial optimization problem whose feasible solutions define both a decomposition and a node labeling of a given graph. This problem offers a common mathematical abstraction of seemingly unrelated computer vision tasks, including instance-separating semantic segmentation, articulated human body pose estimation and multiple object tracking. Conceptually, the problem we state generalizes the unconstrained integer quadratic program and the minimum cost lifted multicut problem, both of which are NP-hard. In order to find feasible solutions efficiently, we define two local search algorithms that converge monotonously to a local optimum, offering a feasible solution at any time. To demonstrate their effectiveness in tackling computer vision tasks, we apply these algorithms to instances of the problem that we construct from published data, using published algorithms. We report state-of-the-art application-specific accuracy for the three above-mentioned applications.
Pixel-level Encoding and Depth Layering for Instance-level Semantic Labeling
Jul 14, 2016
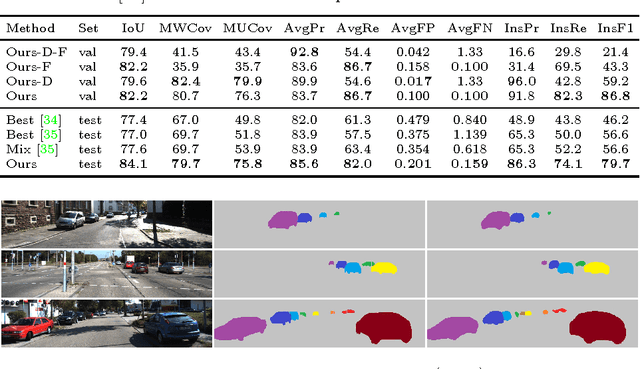
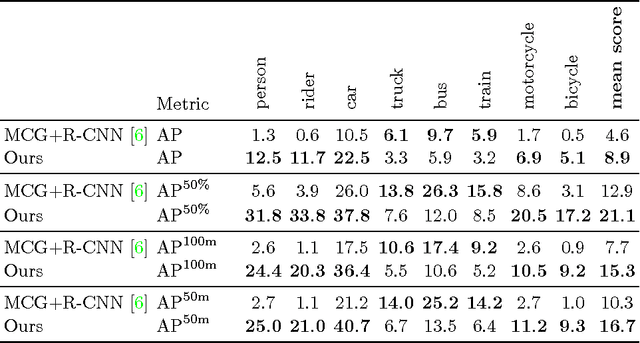

Recent approaches for instance-aware semantic labeling have augmented convolutional neural networks (CNNs) with complex multi-task architectures or computationally expensive graphical models. We present a method that leverages a fully convolutional network (FCN) to predict semantic labels, depth and an instance-based encoding using each pixel's direction towards its corresponding instance center. Subsequently, we apply low-level computer vision techniques to generate state-of-the-art instance segmentation on the street scene datasets KITTI and Cityscapes. Our approach outperforms existing works by a large margin and can additionally predict absolute distances of individual instances from a monocular image as well as a pixel-level semantic labeling.