 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualAD: Disentangling the Dynamic and Static World for End-to-End Driving
Jun 10, 2024State-of-the-art approaches for autonomous driving integrate multiple sub-tasks of the overall driving task into a single pipeline that can be trained in an end-to-end fashion by passing latent representations between the different modules. In contrast to previous approaches that rely on a unified grid to represent the belief state of the scene, we propose dedicated representations to disentangle dynamic agents and static scene elements. This allows us to explicitly compensate for the effect of both ego and object motion between consecutive time steps and to flexibly propagate the belief state through time. Furthermore, dynamic objects can not only attend to the input camera images, but also directly benefit from the inferred static scene structure via a novel dynamic-static cross-attention. Extensive experiments on the challenging nuScenes benchmark demonstrate the benefits of the proposed dual-stream design, especially for modelling highly dynamic agents in the scene, and highlight the improved temporal consistency of our approach. Our method titled DualAD not only outperforms independently trained single-task networks, but also improves over previous state-of-the-art end-to-end models by a large margin on all tasks along the functional chain of driving.
ADA-Track: End-to-End Multi-Camera 3D Multi-Object Tracking with Alternating Detection and Association
May 14, 2024Many query-based approaches for 3D Multi-Object Tracking (MOT) adopt the tracking-by-attention paradigm, utilizing track queries for identity-consistent detection and object queries for identity-agnostic track spawning. Tracking-by-attention, however, entangles detection and tracking queries in one embedding for both the detection and tracking task, which is sub-optimal. Other approaches resemble the tracking-by-detection paradigm, detecting objects using decoupled track and detection queries followed by a subsequent association. These methods, however, do not leverage synergies between the detection and association task. Combining the strengths of both paradigms, we introduce ADA-Track, a novel end-to-end framework for 3D MOT from multi-view cameras. We introduce a learnable data association module based on edge-augmented cross-attention, leveraging appearance and geometric features. Furthermore, we integrate this association module into the decoder layer of a DETR-based 3D detector, enabling simultaneous DETR-like query-to-image cross-attention for detection and query-to-query cross-attention for data association. By stacking these decoder layers, queries are refined for the detection and association task alternately, effectively harnessing the task dependencies. We evaluate our method on the nuScenes dataset and demonstrate the advantage of our approach compared to the two previous paradigms. Code is available at https://github.com/dsx0511/ADA-Track.
Learning Risk-Aware Quadrupedal Locomotion using Distributional Reinforcement Learning
Sep 25, 2023



Deployment in hazardous environments requires robots to understand the risks associated with their actions and movements to prevent accidents. Despite its importance, these risks are not explicitly modeled by currently deployed locomotion controllers for legged robots. In this work, we propose a risk sensitive locomotion training method employing distributional reinforcement learning to consider safety explicitly. Instead of relying on a value expectation, we estimate the complete value distribution to account for uncertainty in the robot's interaction with the environment. The value distribution is consumed by a risk metric to extract risk sensitive value estimates. These are integrated into Proximal Policy Optimization (PPO) to derive our method, Distributional Proximal Policy Optimization (DPPO). The risk preference, ranging from risk-averse to risk-seeking, can be controlled by a single parameter, which enables to adjust the robot's behavior dynamically. Importantly, our approach removes the need for additional reward function tuning to achieve risk sensitivity. We show emergent risk sensitive locomotion behavior in simulation and on the quadrupedal robot ANYmal.
Monte-Carlo tree search with uncertainty propagation via optimal transport
Sep 19, 2023This paper introduces a novel backup strategy for Monte-Carlo Tree Search (MCTS) designed for highly stochastic and partially observable Markov decision processes. We adopt a probabilistic approach, modeling both value and action-value nodes as Gaussian distributions. We introduce a novel backup operator that computes value nodes as the Wasserstein barycenter of their action-value children nodes; thus, propagating the uncertainty of the estimate across the tree to the root node. We study our novel backup operator when using a novel combination of $L^1$-Wasserstein barycenter with $\alpha$-divergence, by drawing a notable connection to the generalized mean backup operator. We complement our probabilistic backup operator with two sampling strategies, based on optimistic selection and Thompson sampling, obtaining our Wasserstein MCTS algorithm. We provide theoretical guarantees of asymptotic convergence to the optimal policy, and an empirical evaluation on several stochastic and partially observable environments, where our approach outperforms well-known related baselines.
3DMOTFormer: Graph Transformer for Online 3D Multi-Object Tracking
Aug 12, 2023Tracking 3D objects accurately and consistently is crucial for autonomous vehicles, enabling more reliable downstream tasks such as trajectory prediction and motion planning. Based on the substantial progress in object detection in recent years, the tracking-by-detection paradigm has become a popular choice due to its simplicity and efficiency. State-of-the-art 3D multi-object tracking (MOT) approaches typically rely on non-learned model-based algorithms such as Kalman Filter but require many manually tuned parameters. On the other hand, learning-based approaches face the problem of adapting the training to the online setting, leading to inevitable distribution mismatch between training and inference as well as suboptimal performance. In this work, we propose 3DMOTFormer, a learned geometry-based 3D MOT framework building upon the transformer architecture. We use an Edge-Augmented Graph Transformer to reason on the track-detection bipartite graph frame-by-frame and conduct data association via edge classification. To reduce the distribution mismatch between training and inference, we propose a novel online training strategy with an autoregressive and recurrent forward pass as well as sequential batch optimization. Using CenterPoint detections, our approach achieves 71.2% and 68.2% AMOTA on the nuScenes validation and test split, respectively. In addition, a trained 3DMOTFormer model generalizes well across different object detectors. Code is available at: https://github.com/dsx0511/3DMOTFormer.
S.T.A.R.-Track: Latent Motion Models for End-to-End 3D Object Tracking with Adaptive Spatio-Temporal Appearance Representations
Jun 30, 2023


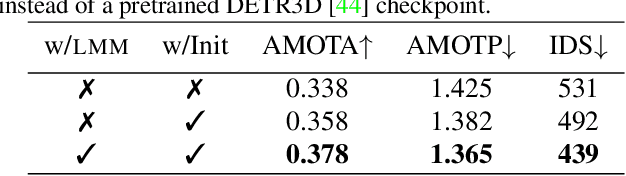
Following the tracking-by-attention paradigm, this paper introduces an object-centric, transformer-based framework for tracking in 3D. Traditional model-based tracking approaches incorporate the geometric effect of object- and ego motion between frames with a geometric motion model. Inspired by this, we propose S.T.A.R.-Track, which uses a novel latent motion model (LMM) to additionally adjust object queries to account for changes in viewing direction and lighting conditions directly in the latent space, while still modeling the geometric motion explicitly. Combined with a novel learnable track embedding that aids in modeling the existence probability of tracks, this results in a generic tracking framework that can be integrated with any query-based detector. Extensive experiments on the nuScenes benchmark demonstrate the benefits of our approach, showing state-of-the-art performance for DETR3D-based trackers while drastically reducing the number of identity switches of tracks at the same time.
Structural Knowledge Distillation for Object Detection
Nov 23, 2022Knowledge Distillation (KD) is a well-known training paradigm in deep neural networks where knowledge acquired by a large teacher model is transferred to a small student. KD has proven to be an effective technique to significantly improve the student's performance for various tasks including object detection. As such, KD techniques mostly rely on guidance at the intermediate feature level, which is typically implemented by minimizing an lp-norm distance between teacher and student activations during training. In this paper, we propose a replacement for the pixel-wise independent lp-norm based on the structural similarity (SSIM). By taking into account additional contrast and structural cues, feature importance, correlation and spatial dependence in the feature space are considered in the loss formulation. Extensive experiments on MSCOCO demonstrate the effectiveness of our method across different training schemes and architectures. Our method adds only little computational overhead, is straightforward to implement and at the same time it significantly outperforms the standard lp-norms. Moreover, more complex state-of-the-art KD methods using attention-based sampling mechanisms are outperformed, including a +3.5 AP gain using a Faster R-CNN R-50 compared to a vanilla model.
Learning Stixel-based Instance Segmentation
Jul 07, 2021Stixels have been successfully applied to a wide range of vision tasks in autonomous driving, recently including instance segmentation. However, due to their sparse occurrence in the image, until now Stixels seldomly served as input for Deep Learning algorithms, restricting their utility for such approaches. In this work we present StixelPointNet, a novel method to perform fast instance segmentation directly on Stixels. By regarding the Stixel representation as unstructured data similar to point clouds, architectures like PointNet are able to learn features from Stixels. We use a bounding box detector to propose candidate instances, for which the relevant Stixels are extracted from the input image. On these Stixels, a PointNet models learns binary segmentations, which we then unify throughout the whole image in a final selection step. StixelPointNet achieves state-of-the-art performance on Stixel-level, is considerably faster than pixel-based segmentation methods, and shows that with our approach the Stixel domain can be introduced to many new 3D Deep Learning tasks.
Slanted Stixels: A way to represent steep streets
Oct 02, 2019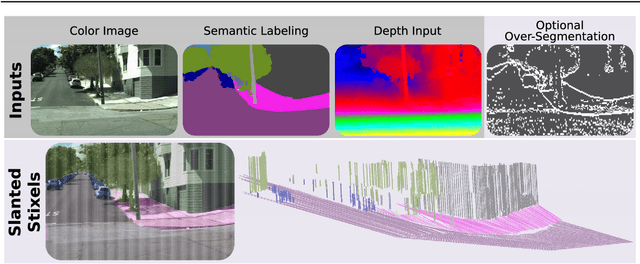
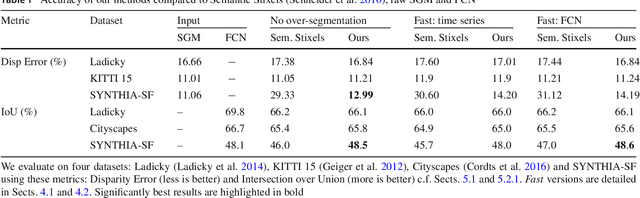

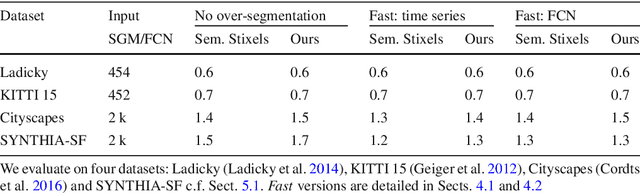
This work presents and evaluates a novel compact scene representation based on Stixels that infers geometric and semantic information. Our approach overcomes the previous rather restrictive geometric assumptions for Stixels by introducing a novel depth model to account for non-flat roads and slanted objects. Both semantic and depth cues are used jointly to infer the scene representation in a sound global energy minimization formulation. Furthermore, a novel approximation scheme is introduced in order to significantly reduce the computational complexity of the Stixel algorithm, and then achieve real-time computation capabilities. The idea is to first perform an over-segmentation of the image, discarding the unlikely Stixel cuts, and apply the algorithm only on the remaining Stixel cuts. This work presents a novel over-segmentation strategy based on a Fully Convolutional Network (FCN), which outperforms an approach based on using local extrema of the disparity map. We evaluate the proposed methods in terms of semantic and geometric accuracy as well as run-time on four publicly available benchmark datasets. Our approach maintains accuracy on flat road scene datasets while improving substantially on a novel non-flat road dataset.
* Journal preprint (published in IJCV 2019: https://link.springer.com/article/10.1007/s11263-019-01226-9). arXiv admin note: text overlap with arXiv:1707.05397
Sparsity Invariant CNNs
Aug 30, 2017
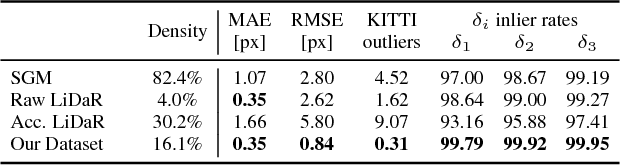

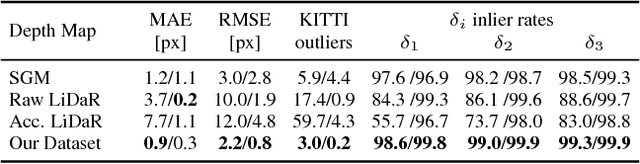
In this paper, we consider convolutional neural networks operating on sparse inputs with an application to depth upsampling from sparse laser scan data. First, we show that traditional convolutional networks perform poorly when applied to sparse data even when the location of missing data is provided to the network. To overcome this problem, we propose a simple yet effective sparse convolution layer which explicitly considers the location of missing data during the convolution operation. We demonstrate the benefits of the proposed network architecture in synthetic and real experiments with respect to various baseline approaches. Compared to dense baselines, the proposed sparse convolution network generalizes well to novel datasets and is invariant to the level of sparsity in the data. For our evaluation, we derive a novel dataset from the KITTI benchmark, comprising 93k depth annotated RGB images. Our dataset allows for training and evaluating depth upsampling and depth prediction techniques in challenging real-world settings and will be made available upon publication.