 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cascaded Detection Tasks with Weakly-Supervised Domain Adaptation
Jul 09, 2021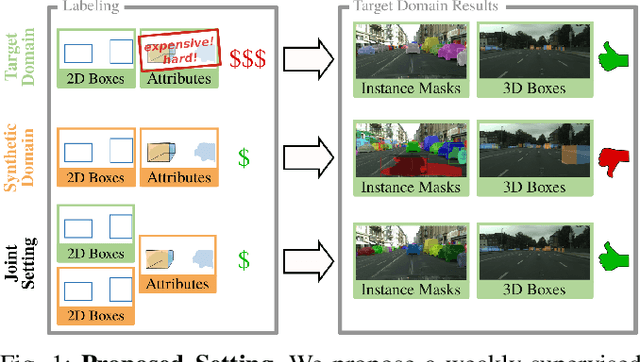
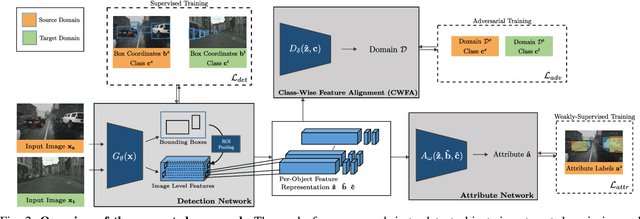


In order to handle the challenges of autonomous driving, deep learning has proven to be crucial in tackling increasingly complex tasks, such as 3D detection or instance segmentation. State-of-the-art approaches for image-based detection tasks tackle this complexity by operating in a cascaded fashion: they first extract a 2D bounding box based on which additional attributes, e.g. instance masks, are inferred. While these methods perform well, a key challenge remains the lack of accurate and cheap annotations for the growing variety of tasks. Synthetic data presents a promising solution but, despite the effort in domain adaptation research, the gap between synthetic and real data remains an open problem. In this work, we propose a weakly supervised domain adaptation setting which exploits the structure of cascaded detection tasks. In particular, we learn to infer the attributes solely from the source domain while leveraging 2D bounding boxes as weak labels in both domains to explain the domain shift. We further encourage domain-invariant features through class-wise feature alignment using ground-truth class information, which is not available in the unsupervised setting. As our experiments demonstrate, the approach is competitive with fully supervised settings while outperforming unsupervised adaptation approaches by a large margin.
Boosting LiDAR-based Semantic Labeling by Cross-Modal Training Data Generation
Apr 26, 2018



Mobile robots and autonomous vehicles rely on multi-modal sensor setups to perceive and understand their surroundings. Aside from cameras, LiDAR sensors represent a central component of state-of-the-art perception systems. In addition to accurate spatial perception, a comprehensive semantic understanding of the environment is essential for efficient and safe operation. In this paper we present a novel deep neural network architecture called LiLaNet for point-wise, multi-class semantic labeling of semi-dense LiDAR data. The network utilizes virtual image projections of the 3D point clouds for efficient inference. Further, we propose an automated process for large-scale cross-modal training data generation called Autolabeling, in order to boost semantic labeling performance while keeping the manual annotation effort low. The effectiveness of the proposed network architecture as well as the automated data generation process is demonstrated on a manually annotated ground truth dataset. LiLaNet is shown to significantly outperform current state-of-the-art CNN architectures for LiDAR data. Applying our automatically generated large-scale training data yields a boost of up to 14 percentage points compared to networks trained on manually annotated data only.
Sparsity Invariant CNNs
Aug 30, 2017
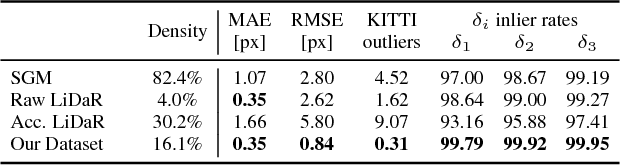

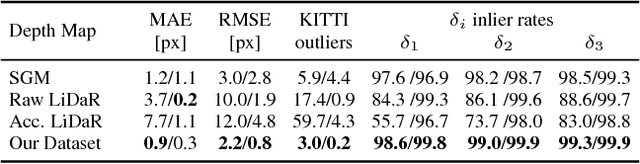
In this paper, we consider convolutional neural networks operating on sparse inputs with an application to depth upsampling from sparse laser scan data. First, we show that traditional convolutional networks perform poorly when applied to sparse data even when the location of missing data is provided to the network. To overcome this problem, we propose a simple yet effective sparse convolution layer which explicitly considers the location of missing data during the convolution operation. We demonstrate the benefits of the proposed network architecture in synthetic and real experiments with respect to various baseline approaches. Compared to dense baselines, the proposed sparse convolution network generalizes well to novel datasets and is invariant to the level of sparsity in the data. For our evaluation, we derive a novel dataset from the KITTI benchmark, comprising 93k depth annotated RGB images. Our dataset allows for training and evaluating depth upsampling and depth prediction techniques in challenging real-world settings and will be made available upon publication.
RegNet: Multimodal Sensor Registration Using Deep Neural Networks
Jul 11, 2017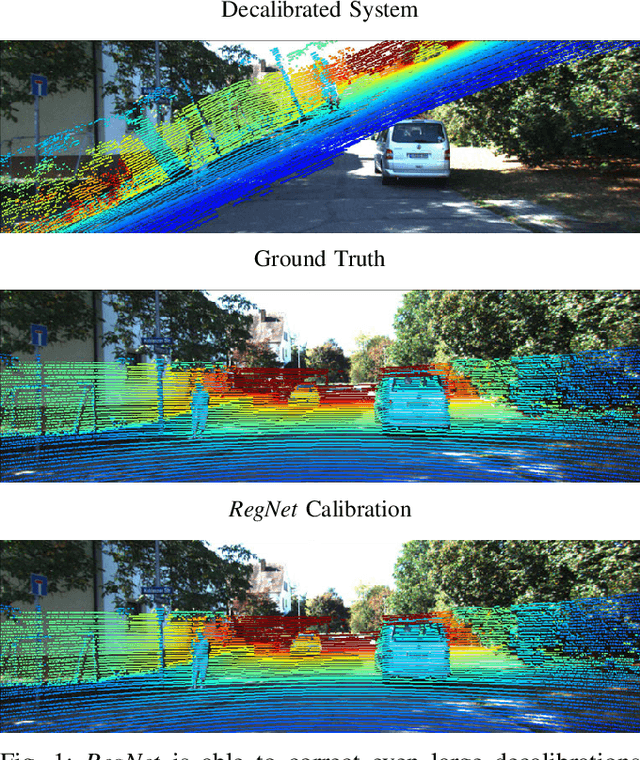
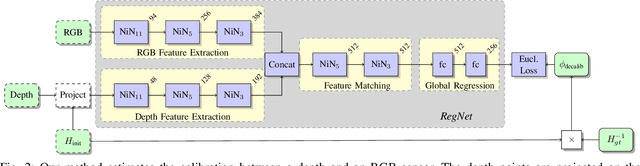

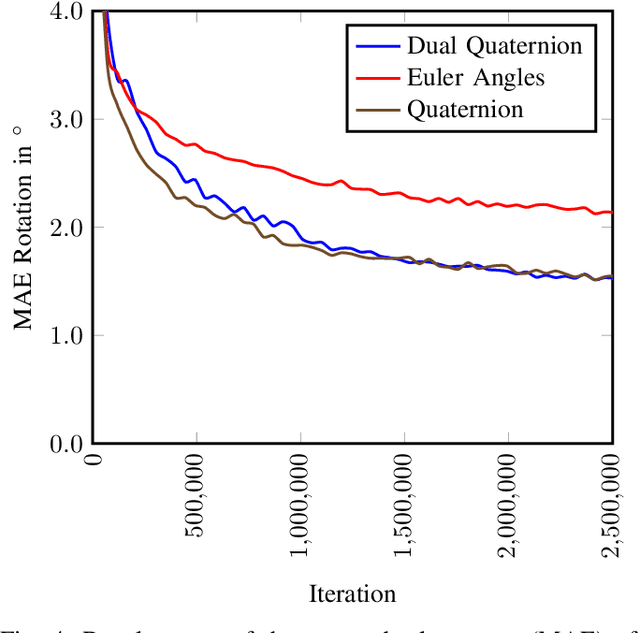
In this paper, we present RegNet, the first deep convolutional neural network (CNN) to infer a 6 degrees of freedom (DOF) extrinsic calibration between multimodal sensors, exemplified using a scanning LiDAR and a monocular camera. Compared to existing approaches, RegNet casts all three conventional calibration steps (feature extraction, feature matching and global regression) into a single real-time capable CNN. Our method does not require any human interaction and bridges the gap between classical offline and target-less online calibration approaches as it provides both a stable initial estimation as well as a continuous online correction of the extrinsic parameters. During training we randomly decalibrate our system in order to train RegNet to infer the correspondence between projected depth measurements and RGB image and finally regress the extrinsic calibration. Additionally, with an iterative execution of multiple CNNs, that are trained on different magnitudes of decalibration, our approach compares favorably to state-of-the-art methods in terms of a mean calibration error of 0.28 degrees for the rotational and 6 cm for the translation components even for large decalibrations up to 1.5 m and 20 degrees.
Semantically Guided Depth Upsampling
Aug 02, 2016
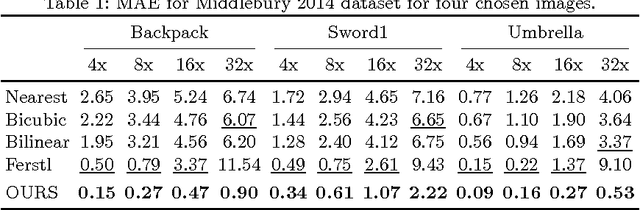

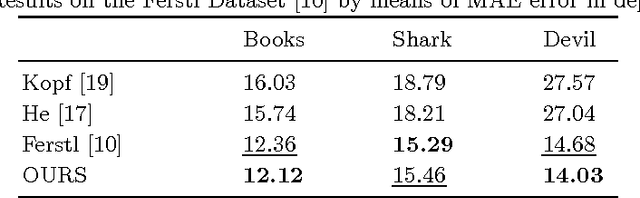
We present a novel method for accurate and efficient up- sampling of sparse depth data, guided by high-resolution imagery. Our approach goes beyond the use of intensity cues only and additionally exploits object boundary cues through structured edge detection and semantic scene labeling for guidance. Both cues are combined within a geodesic distance measure that allows for boundary-preserving depth in- terpolation while utilizing local context. We model the observed scene structure by locally planar elements and formulate the upsampling task as a global energy minimization problem. Our method determines glob- ally consistent solutions and preserves fine details and sharp depth bound- aries. In our experiments on several public datasets at different levels of application, we demonstrate superior performance of our approach over the state-of-the-art, even for very sparse measurements.