 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Cross-Sensor Portability of Neural Network Architectures for LiDAR-based Semantic Labeling
Jul 03, 2019


State-of-the-art approaches for the semantic labeling of LiDAR point clouds heavily rely on the use of deep Convolutional Neural Networks (CNNs). However, transferring network architectures across different LiDAR sensor types represents a significant challenge, especially due to sensor specific design choices with regard to network architecture as well as data representation. In this paper we propose a new CNN architecture for the point-wise semantic labeling of LiDAR data which achieves state-of-the-art results while increasing portability across sensor types. This represents a significant advantage given the fast-paced development of LiDAR hardware technology. We perform a thorough quantitative cross-sensor analysis of semantic labeling performance in comparison to a state-of-the-art reference method. Our evaluation shows that the proposed architecture is indeed highly portable, yielding an improvement of 10 percentage points in the Intersection-over-Union (IoU) score when compared to the reference approach. Further, the results indicate that the proposed network architecture can provide an efficient way for the automated generation of large-scale training data for novel LiDAR sensor types without the need for extensive manual annotation or multi-modal label transfer.
Improved Semantic Stixels via Multimodal Sensor Fusion
Sep 27, 2018
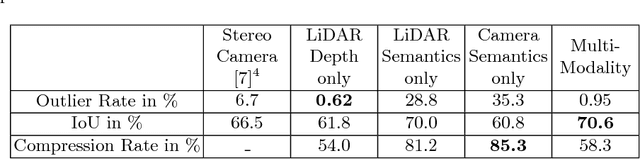
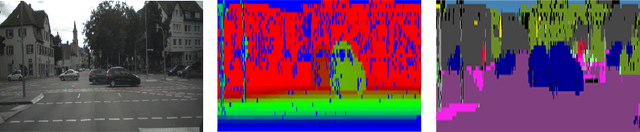
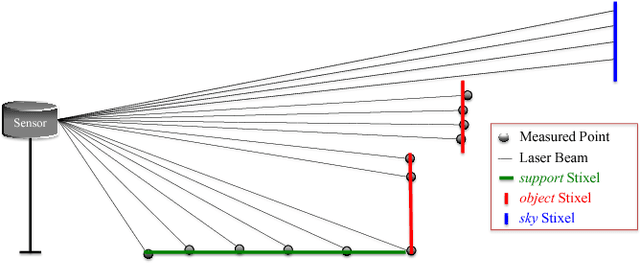
This paper presents a compact and accurate representation of 3D scenes that are observed by a LiDAR sensor and a monocular camera. The proposed method is based on the well-established Stixel model originally developed for stereo vision applications. We extend this Stixel concept to incorporate data from multiple sensor modalities. The resulting mid-level fusion scheme takes full advantage of the geometric accuracy of LiDAR measurements as well as the high resolution and semantic detail of RGB images. The obtained environment model provides a geometrically and semantically consistent representation of the 3D scene at a significantly reduced amount of data while minimizing information loss at the same time. Since the different sensor modalities are considered as input to a joint optimization problem, the solution is obtained with only minor computational overhead. We demonstrate the effectiveness of the proposed multimodal Stixel algorithm on a manually annotated ground truth dataset. Our results indicate that the proposed mid-level fusion of LiDAR and camera data improves both the geometric and semantic accuracy of the Stixel model significantly while reducing the computational overhead as well as the amount of generated data in comparison to using a single modality on its own.
Boosting LiDAR-based Semantic Labeling by Cross-Modal Training Data Generation
Apr 26, 2018



Mobile robots and autonomous vehicles rely on multi-modal sensor setups to perceive and understand their surroundings. Aside from cameras, LiDAR sensors represent a central component of state-of-the-art perception systems. In addition to accurate spatial perception, a comprehensive semantic understanding of the environment is essential for efficient and safe operation. In this paper we present a novel deep neural network architecture called LiLaNet for point-wise, multi-class semantic labeling of semi-dense LiDAR data. The network utilizes virtual image projections of the 3D point clouds for efficient inference. Further, we propose an automated process for large-scale cross-modal training data generation called Autolabeling, in order to boost semantic labeling performance while keeping the manual annotation effort low. The effectiveness of the proposed network architecture as well as the automated data generation process is demonstrated on a manually annotated ground truth dataset. LiLaNet is shown to significantly outperform current state-of-the-art CNN architectures for LiDAR data. Applying our automatically generated large-scale training data yields a boost of up to 14 percentage points compared to networks trained on manually annotated data only.
Detecting Unexpected Obstacles for Self-Driving Cars: Fusing Deep Learning and Geometric Modeling
Dec 20, 2016
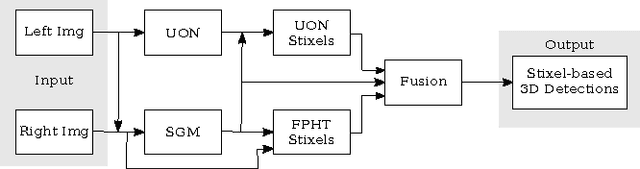

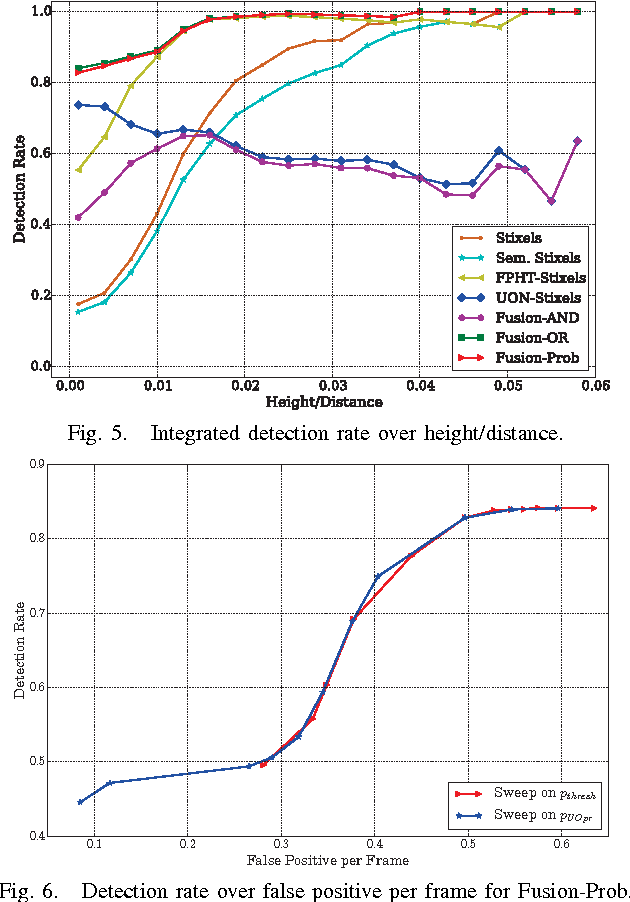
The detection of small road hazards, such as lost cargo, is a vital capability for self-driving cars. We tackle this challenging and rarely addressed problem with a vision system that leverages appearance, contextual as well as geometric cues. To utilize the appearance and contextual cues, we propose a new deep learning-based obstacle detection framework. Here a variant of a fully convolutional network is used to predict a pixel-wise semantic labeling of (i) free-space, (ii) on-road unexpected obstacles, and (iii) background. The geometric cues are exploited using a state-of-the-art detection approach that predicts obstacles from stereo input images via model-based statistical hypothesis tests. We present a principled Bayesian framework to fuse the semantic and stereo-based detection results. The mid-level Stixel representation is used to describe obstacles in a flexible, compact and robust manner. We evaluate our new obstacle detection system on the Lost and Found dataset, which includes very challenging scenes with obstacles of only 5 cm height. Overall, we report a major improvement over the state-of-the-art, with relative performance gains of up to 50%. In particular, we achieve a detection rate of over 90% for distances of up to 50 m. Our system operates at 22 Hz on our self-driving platform.
Lost and Found: Detecting Small Road Hazards for Self-Driving Vehicles
Sep 15, 2016
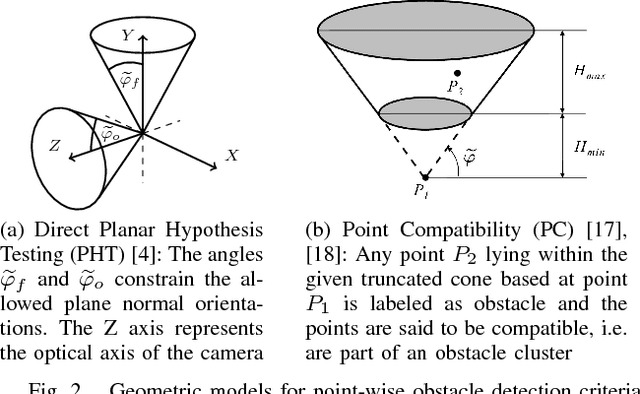


Detecting small obstacles on the road ahead is a critical part of the driving task which has to be mastered by fully autonomous cars. In this paper, we present a method based on stereo vision to reliably detect such obstacles from a moving vehicle. The proposed algorithm performs statistical hypothesis tests in disparity space directly on stereo image data, assessing freespace and obstacle hypotheses on independent local patches. This detection approach does not depend on a global road model and handles both static and moving obstacles. For evaluation, we employ a novel lost-cargo image sequence dataset comprising more than two thousand frames with pixelwise annotations of obstacle and free-space and provide a thorough comparison to several stereo-based baseline methods. The dataset will be made available to the community to foster further research on this important topic. The proposed approach outperforms all considered baselines in our evaluations on both pixel and object level and runs at frame rates of up to 20 Hz on 2 mega-pixel stereo imagery. Small obstacles down to the height of 5 cm can successfully be detected at 20 m distance at low false positive rates.
Semantically Guided Depth Upsampling
Aug 02, 2016
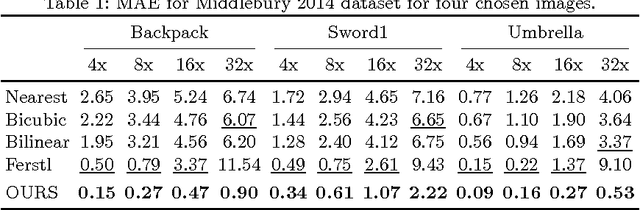

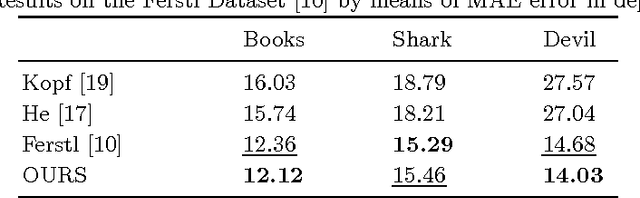
We present a novel method for accurate and efficient up- sampling of sparse depth data, guided by high-resolution imagery. Our approach goes beyond the use of intensity cues only and additionally exploits object boundary cues through structured edge detection and semantic scene labeling for guidance. Both cues are combined within a geodesic distance measure that allows for boundary-preserving depth in- terpolation while utilizing local context. We model the observed scene structure by locally planar elements and formulate the upsampling task as a global energy minimization problem. Our method determines glob- ally consistent solutions and preserves fine details and sharp depth bound- aries. In our experiments on several public datasets at different levels of application, we demonstrate superior performance of our approach over the state-of-the-art, even for very sparse measurements.