 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Unexpected Obstacles for Self-Driving Cars: Fusing Deep Learning and Geometric Modeling
Paper and Code
Dec 20, 2016
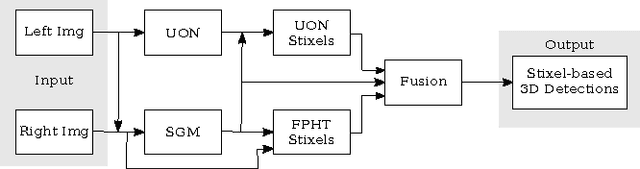

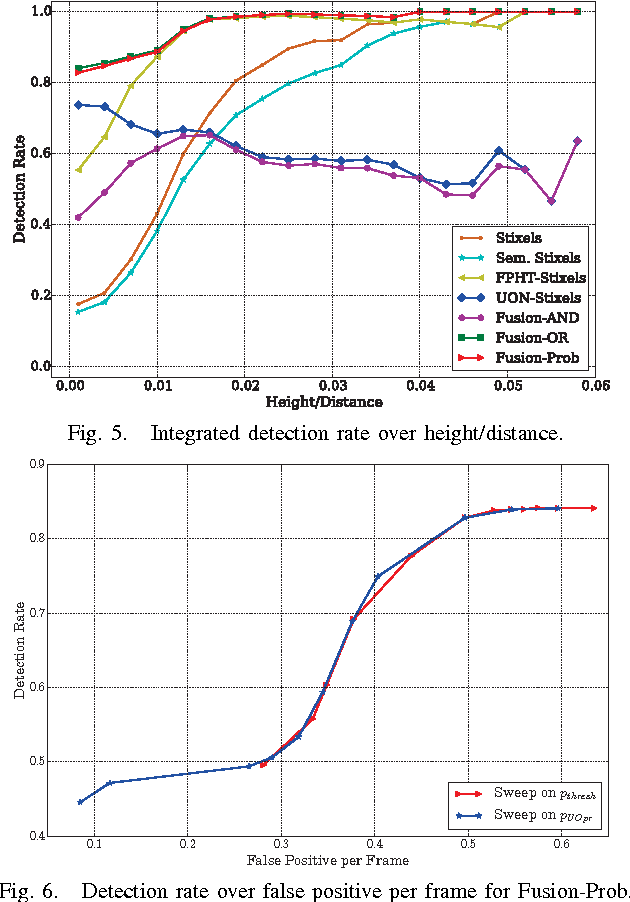
The detection of small road hazards, such as lost cargo, is a vital capability for self-driving cars. We tackle this challenging and rarely addressed problem with a vision system that leverages appearance, contextual as well as geometric cues. To utilize the appearance and contextual cues, we propose a new deep learning-based obstacle detection framework. Here a variant of a fully convolutional network is used to predict a pixel-wise semantic labeling of (i) free-space, (ii) on-road unexpected obstacles, and (iii) background. The geometric cues are exploited using a state-of-the-art detection approach that predicts obstacles from stereo input images via model-based statistical hypothesis tests. We present a principled Bayesian framework to fuse the semantic and stereo-based detection results. The mid-level Stixel representation is used to describe obstacles in a flexible, compact and robust manner. We evaluate our new obstacle detection system on the Lost and Found dataset, which includes very challenging scenes with obstacles of only 5 cm height. Overall, we report a major improvement over the state-of-the-art, with relative performance gains of up to 50%. In particular, we achieve a detection rate of over 90% for distances of up to 50 m. Our system operates at 22 Hz on our self-driving platform.