 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Unexpected Obstacles for Self-Driving Cars: Fusing Deep Learning and Geometric Modeling
Dec 20, 2016
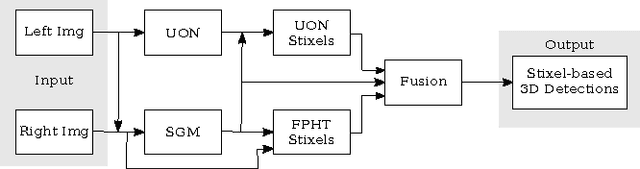

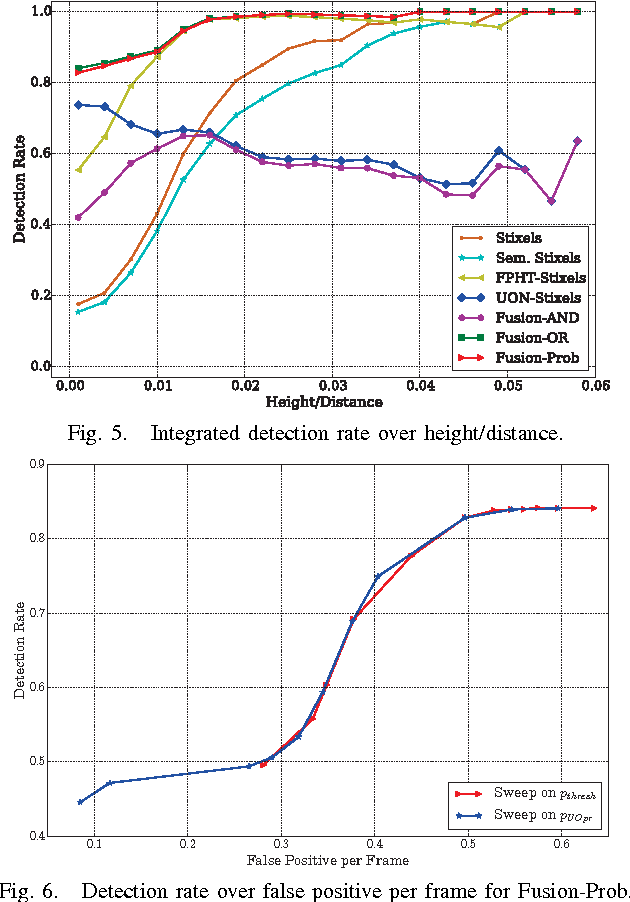
The detection of small road hazards, such as lost cargo, is a vital capability for self-driving cars. We tackle this challenging and rarely addressed problem with a vision system that leverages appearance, contextual as well as geometric cues. To utilize the appearance and contextual cues, we propose a new deep learning-based obstacle detection framework. Here a variant of a fully convolutional network is used to predict a pixel-wise semantic labeling of (i) free-space, (ii) on-road unexpected obstacles, and (iii) background. The geometric cues are exploited using a state-of-the-art detection approach that predicts obstacles from stereo input images via model-based statistical hypothesis tests. We present a principled Bayesian framework to fuse the semantic and stereo-based detection results. The mid-level Stixel representation is used to describe obstacles in a flexible, compact and robust manner. We evaluate our new obstacle detection system on the Lost and Found dataset, which includes very challenging scenes with obstacles of only 5 cm height. Overall, we report a major improvement over the state-of-the-art, with relative performance gains of up to 50%. In particular, we achieve a detection rate of over 90% for distances of up to 50 m. Our system operates at 22 Hz on our self-driving platform.
Lost and Found: Detecting Small Road Hazards for Self-Driving Vehicles
Sep 15, 2016
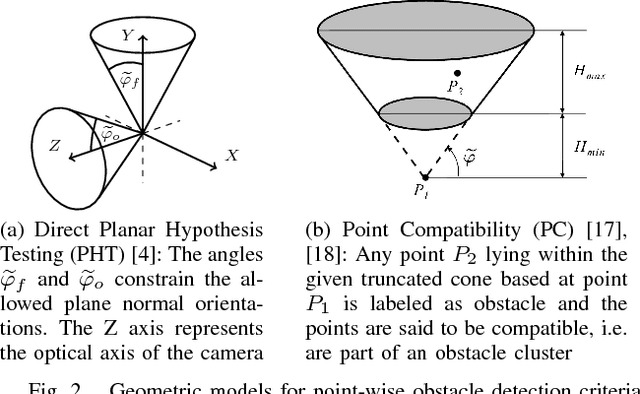


Detecting small obstacles on the road ahead is a critical part of the driving task which has to be mastered by fully autonomous cars. In this paper, we present a method based on stereo vision to reliably detect such obstacles from a moving vehicle. The proposed algorithm performs statistical hypothesis tests in disparity space directly on stereo image data, assessing freespace and obstacle hypotheses on independent local patches. This detection approach does not depend on a global road model and handles both static and moving obstacles. For evaluation, we employ a novel lost-cargo image sequence dataset comprising more than two thousand frames with pixelwise annotations of obstacle and free-space and provide a thorough comparison to several stereo-based baseline methods. The dataset will be made available to the community to foster further research on this important topic. The proposed approach outperforms all considered baselines in our evaluations on both pixel and object level and runs at frame rates of up to 20 Hz on 2 mega-pixel stereo imagery. Small obstacles down to the height of 5 cm can successfully be detected at 20 m distance at low false positive rates.
The Cityscapes Dataset for Semantic Urban Scene Understanding
Apr 07, 2016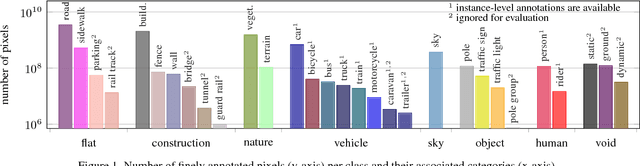

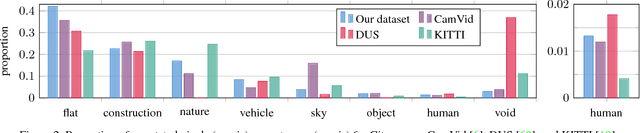
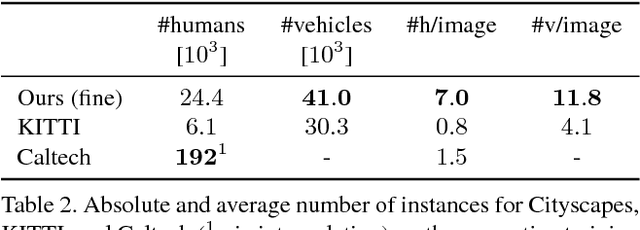
Visual understanding of complex urban street scenes is an enabling factor for a wide range of applications. Object detection has benefited enormously from large-scale datasets, especially in the context of deep learning. For semantic urban scene understanding, however, no current dataset adequately captures the complexity of real-world urban scenes. To address this, we introduce Cityscapes, a benchmark suite and large-scale dataset to train and test approaches for pixel-level and instance-level semantic labeling. Cityscapes is comprised of a large, diverse set of stereo video sequences recorded in streets from 50 different cities. 5000 of these images have high quality pixel-level annotations; 20000 additional images have coarse annotations to enable methods that leverage large volumes of weakly-labeled data. Crucially, our effort exceeds previous attempts in terms of dataset size, annotation richness, scene variability, and complexity. Our accompanying empirical study provides an in-depth analysis of the dataset characteristics, as well as a performance evaluation of several state-of-the-art approaches based on our benchmark.
Hierarchical Adaptive Structural SVM for Domain Adaptation
Aug 22, 2014

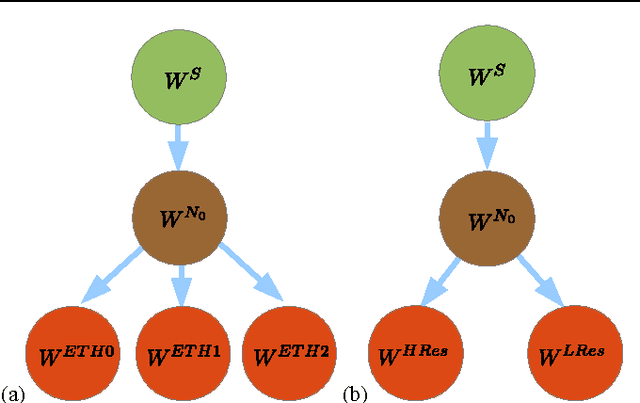
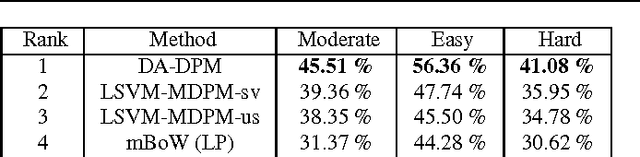
A key topic in classification is the accuracy loss produced when the data distribution in the training (source) domain differs from that in the testing (target) domain. This is being recognized as a very relevant problem for many computer vision tasks such as image classification, object detection, and object category recognition. In this paper, we present a novel domain adaptation method that leverages multiple target domains (or sub-domains) in a hierarchical adaptation tree. The core idea is to exploit the commonalities and differences of the jointly considered target domains. Given the relevance of structural SVM (SSVM) classifiers, we apply our idea to the adaptive SSVM (A-SSVM), which only requires the target domain samples together with the existing source-domain classifier for performing the desired adaptation. Altogether, we term our proposal as hierarchical A-SSVM (HA-SSVM). As proof of concept we use HA-SSVM for pedestrian detection and object category recognition. In the former we apply HA-SSVM to the deformable part-based model (DPM) while in the latter HA-SSVM is applied to multi-category classifiers. In both cases, we show how HA-SSVM is effective in increasing the detection/recognition accuracy with respect to adaptation strategies that ignore the structure of the target data. Since, the sub-domains of the target data are not always known a priori, we shown how HA-SSVM can incorporate sub-domain structure discovery for object category recognition.
Spatiotemporal Stacked Sequential Learning for Pedestrian Detection
Jul 14, 2014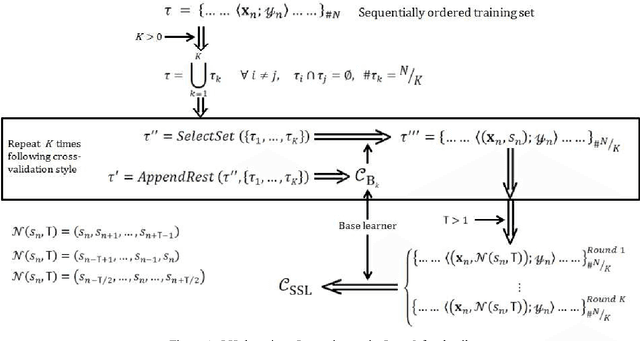
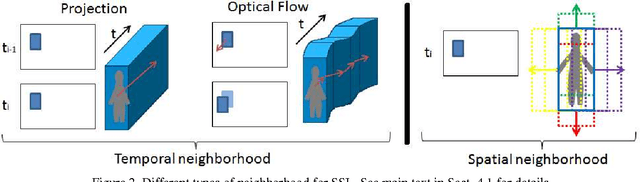
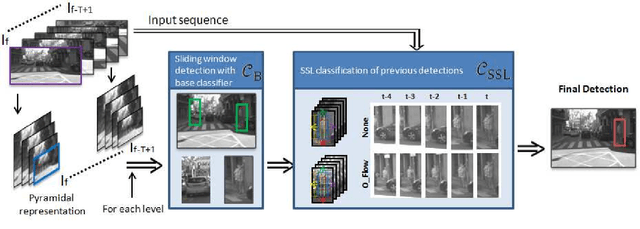
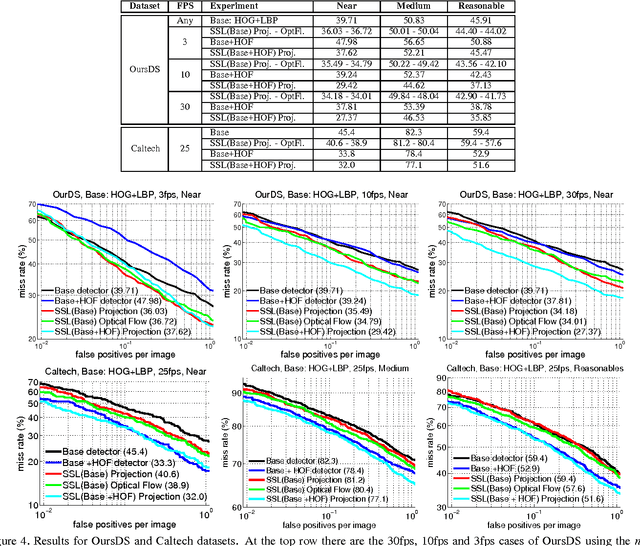
Pedestrian classifiers decide which image windows contain a pedestrian. In practice, such classifiers provide a relatively high response at neighbor windows overlapping a pedestrian, while the responses around potential false positives are expected to be lower. An analogous reasoning applies for image sequences. If there is a pedestrian located within a frame, the same pedestrian is expected to appear close to the same location in neighbor frames. Therefore, such a location has chances of receiving high classification scores during several frames, while false positives are expected to be more spurious. In this paper we propose to exploit such correlations for improving the accuracy of base pedestrian classifiers. In particular, we propose to use two-stage classifiers which not only rely on the image descriptors required by the base classifiers but also on the response of such base classifiers in a given spatiotemporal neighborhood. More specifically, we train pedestrian classifiers using a stacked sequential learning (SSL) paradigm. We use a new pedestrian dataset we have acquired from a car to evaluate our proposal at different frame rates. We also test on a well known dataset: Caltech. The obtained results show that our SSL proposal boosts detection accuracy significantly with a minimal impact on the computational cost. Interestingly, SSL improves more the accuracy at the most dangerous situations, i.e. when a pedestrian is close to the camera.