 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearchAD: Large-Scale Rare Image Retrieval Dataset for Autonomous Driving
Apr 09, 2026Retrieving rare and safety-critical driving scenarios from large-scale datasets is essential for building robust autonomous driving (AD) systems. As dataset sizes continue to grow, the key challenge shifts from collecting more data to efficiently identifying the most relevant samples. We introduce SearchAD, a large-scale rare image retrieval dataset for AD containing over 423k frames drawn from 11 established datasets. SearchAD provides high-quality manual annotations of more than 513k bounding boxes covering 90 rare categories. It specifically targets the needle-in-a-haystack problem of locating extremely rare classes, with some appearing fewer than 50 times across the entire dataset. Unlike existing benchmarks, which focused on instance-level retrieval, SearchAD emphasizes semantic image retrieval with a well-defined data split, enabling text-to-image and image-to-image retrieval, few-shot learning, and fine-tuning of multi-modal retrieval models. Comprehensive evaluations show that text-based methods outperform image-based ones due to stronger inherent semantic grounding. While models directly aligning spatial visual features with language achieve the best zero-shot results, and our fine-tuning baseline significantly improves performance, absolute retrieval capabilities remain unsatisfactory. With a held-out test set on a public benchmark server, SearchAD establishes the first large-scale dataset for retrieval-driven data curation and long-tail perception research in AD: https://iis-esslingen.github.io/searchad/
What Matters for Scalable and Robust Learning in End-to-End Driving Planners?
Mar 16, 2026End-to-end autonomous driving has gained significant attention for its potential to learn robust behavior in interactive scenarios and scale with data. Popular architectures often build on separate modules for perception and planning connected through latent representations, such as bird's eye view feature grids, to maintain end-to-end differentiability. This paradigm emerged mostly on open-loop datasets, with evaluation focusing not only on driving performance, but also intermediate perception tasks. Unfortunately, architectural advances that excel in open-loop often fail to translate to scalable learning of robust closed-loop driving. In this paper, we systematically re-examine the impact of common architectural patterns on closed-loop performance: (1) high-resolution perceptual representations, (2) disentangled trajectory representations, and (3) generative planning. Crucially, our analysis evaluates the combined impact of these patterns, revealing both unexpected limitations as well as underexplored synergies. Building on these insights, we introduce BevAD, a novel lightweight and highly scalable end-to-end driving architecture. BevAD achieves 72.7% success rate on the Bench2Drive benchmark and demonstrates strong data-scaling behavior using pure imitation learning. Our code and models are publicly available here: https://dmholtz.github.io/bevad/
AGO: Adaptive Grounding for Open World 3D Occupancy Prediction
Apr 14, 2025Open-world 3D semantic occupancy prediction aims to generate a voxelized 3D representation from sensor inputs while recognizing both known and unknown objects. Transferring open-vocabulary knowledge from vision-language models (VLMs) offers a promising direction but remains challenging. However, methods based on VLM-derived 2D pseudo-labels with traditional supervision are limited by a predefined label space and lack general prediction capabilities. Direct alignment with pretrained image embeddings, on the other hand, fails to achieve reliable performance due to often inconsistent image and text representations in VLMs. To address these challenges, we propose AGO, a novel 3D occupancy prediction framework with adaptive grounding to handle diverse open-world scenarios. AGO first encodes surrounding images and class prompts into 3D and text embeddings, respectively, leveraging similarity-based grounding training with 3D pseudo-labels. Additionally, a modality adapter maps 3D embeddings into a space aligned with VLM-derived image embeddings, reducing modality gaps. Experiments on Occ3D-nuScenes show that AGO improves unknown object prediction in zero-shot and few-shot transfer while achieving state-of-the-art closed-world self-supervised performance, surpassing prior methods by 4.09 mIoU.
EMPERROR: A Flexible Generative Perception Error Model for Probing Self-Driving Planners
Nov 12, 2024



To handle the complexities of real-world traffic, learning planners for self-driving from data is a promising direction. While recent approaches have shown great progress, they typically assume a setting in which the ground-truth world state is available as input. However, when deployed, planning needs to be robust to the long-tail of errors incurred by a noisy perception system, which is often neglected in evaluation. To address this, previous work has proposed drawing adversarial samples from a perception error model (PEM) mimicking the noise characteristics of a target object detector. However, these methods use simple PEMs that fail to accurately capture all failure modes of detection. In this paper, we present EMPERROR, a novel transformer-based generative PEM, apply it to stress-test an imitation learning (IL)-based planner and show that it imitates modern detectors more faithfully than previous work. Furthermore, it is able to produce realistic noisy inputs that increase the planner's collision rate by up to 85%, demonstrating its utility as a valuable tool for a more complete evaluation of self-driving planners.
DualAD: Disentangling the Dynamic and Static World for End-to-End Driving
Jun 10, 2024State-of-the-art approaches for autonomous driving integrate multiple sub-tasks of the overall driving task into a single pipeline that can be trained in an end-to-end fashion by passing latent representations between the different modules. In contrast to previous approaches that rely on a unified grid to represent the belief state of the scene, we propose dedicated representations to disentangle dynamic agents and static scene elements. This allows us to explicitly compensate for the effect of both ego and object motion between consecutive time steps and to flexibly propagate the belief state through time. Furthermore, dynamic objects can not only attend to the input camera images, but also directly benefit from the inferred static scene structure via a novel dynamic-static cross-attention. Extensive experiments on the challenging nuScenes benchmark demonstrate the benefits of the proposed dual-stream design, especially for modelling highly dynamic agents in the scene, and highlight the improved temporal consistency of our approach. Our method titled DualAD not only outperforms independently trained single-task networks, but also improves over previous state-of-the-art end-to-end models by a large margin on all tasks along the functional chain of driving.
ADA-Track: End-to-End Multi-Camera 3D Multi-Object Tracking with Alternating Detection and Association
May 14, 2024Many query-based approaches for 3D Multi-Object Tracking (MOT) adopt the tracking-by-attention paradigm, utilizing track queries for identity-consistent detection and object queries for identity-agnostic track spawning. Tracking-by-attention, however, entangles detection and tracking queries in one embedding for both the detection and tracking task, which is sub-optimal. Other approaches resemble the tracking-by-detection paradigm, detecting objects using decoupled track and detection queries followed by a subsequent association. These methods, however, do not leverage synergies between the detection and association task. Combining the strengths of both paradigms, we introduce ADA-Track, a novel end-to-end framework for 3D MOT from multi-view cameras. We introduce a learnable data association module based on edge-augmented cross-attention, leveraging appearance and geometric features. Furthermore, we integrate this association module into the decoder layer of a DETR-based 3D detector, enabling simultaneous DETR-like query-to-image cross-attention for detection and query-to-query cross-attention for data association. By stacking these decoder layers, queries are refined for the detection and association task alternately, effectively harnessing the task dependencies. We evaluate our method on the nuScenes dataset and demonstrate the advantage of our approach compared to the two previous paradigms. Code is available at https://github.com/dsx0511/ADA-Track.
3DMOTFormer: Graph Transformer for Online 3D Multi-Object Tracking
Aug 12, 2023Tracking 3D objects accurately and consistently is crucial for autonomous vehicles, enabling more reliable downstream tasks such as trajectory prediction and motion planning. Based on the substantial progress in object detection in recent years, the tracking-by-detection paradigm has become a popular choice due to its simplicity and efficiency. State-of-the-art 3D multi-object tracking (MOT) approaches typically rely on non-learned model-based algorithms such as Kalman Filter but require many manually tuned parameters. On the other hand, learning-based approaches face the problem of adapting the training to the online setting, leading to inevitable distribution mismatch between training and inference as well as suboptimal performance. In this work, we propose 3DMOTFormer, a learned geometry-based 3D MOT framework building upon the transformer architecture. We use an Edge-Augmented Graph Transformer to reason on the track-detection bipartite graph frame-by-frame and conduct data association via edge classification. To reduce the distribution mismatch between training and inference, we propose a novel online training strategy with an autoregressive and recurrent forward pass as well as sequential batch optimization. Using CenterPoint detections, our approach achieves 71.2% and 68.2% AMOTA on the nuScenes validation and test split, respectively. In addition, a trained 3DMOTFormer model generalizes well across different object detectors. Code is available at: https://github.com/dsx0511/3DMOTFormer.
PowerBEV: A Powerful Yet Lightweight Framework for Instance Prediction in Bird's-Eye View
Jun 19, 2023Accurately perceiving instances and predicting their future motion are key tasks for autonomous vehicles, enabling them to navigate safely in complex urban traffic. While bird's-eye view (BEV) representations are commonplace in perception for autonomous driving, their potential in a motion prediction setting is less explored. Existing approaches for BEV instance prediction from surround cameras rely on a multi-task auto-regressive setup coupled with complex post-processing to predict future instances in a spatio-temporally consistent manner. In this paper, we depart from this paradigm and propose an efficient novel end-to-end framework named POWERBEV, which differs in several design choices aimed at reducing the inherent redundancy in previous methods. First, rather than predicting the future in an auto-regressive fashion, POWERBEV uses a parallel, multi-scale module built from lightweight 2D convolutional networks. Second, we show that segmentation and centripetal backward flow are sufficient for prediction, simplifying previous multi-task objectives by eliminating redundant output modalities. Building on this output representation, we propose a simple, flow warping-based post-processing approach which produces more stable instance associations across time. Through this lightweight yet powerful design, POWERBEV outperforms state-of-the-art baselines on the NuScenes Dataset and poses an alternative paradigm for BEV instance prediction. We made our code publicly available at: https://github.com/EdwardLeeLPZ/PowerBEV.
Structural Knowledge Distillation for Object Detection
Nov 23, 2022Knowledge Distillation (KD) is a well-known training paradigm in deep neural networks where knowledge acquired by a large teacher model is transferred to a small student. KD has proven to be an effective technique to significantly improve the student's performance for various tasks including object detection. As such, KD techniques mostly rely on guidance at the intermediate feature level, which is typically implemented by minimizing an lp-norm distance between teacher and student activations during training. In this paper, we propose a replacement for the pixel-wise independent lp-norm based on the structural similarity (SSIM). By taking into account additional contrast and structural cues, feature importance, correlation and spatial dependence in the feature space are considered in the loss formulation. Extensive experiments on MSCOCO demonstrate the effectiveness of our method across different training schemes and architectures. Our method adds only little computational overhead, is straightforward to implement and at the same time it significantly outperforms the standard lp-norms. Moreover, more complex state-of-the-art KD methods using attention-based sampling mechanisms are outperformed, including a +3.5 AP gain using a Faster R-CNN R-50 compared to a vanilla model.
Cityscapes 3D: Dataset and Benchmark for 9 DoF Vehicle Detection
Jun 14, 2020
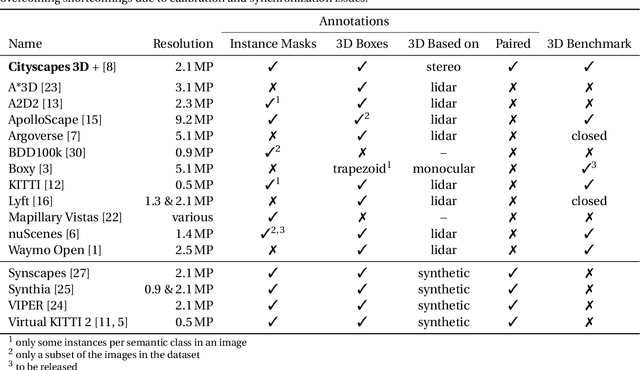
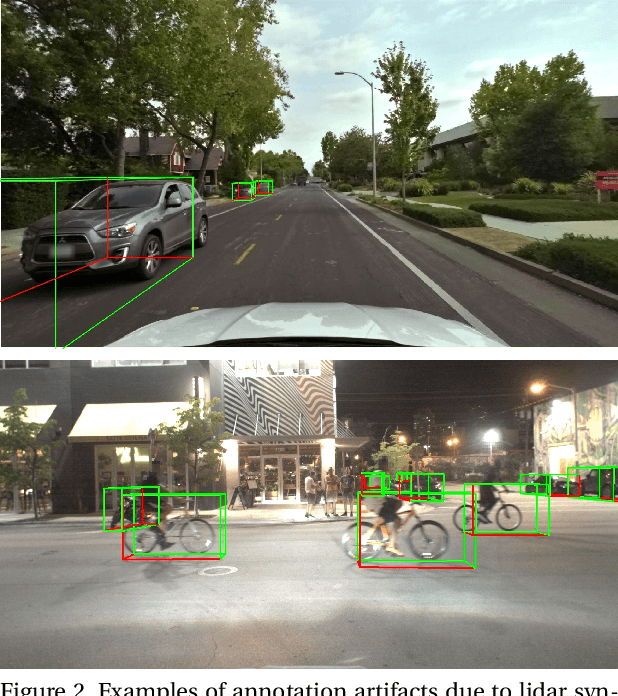
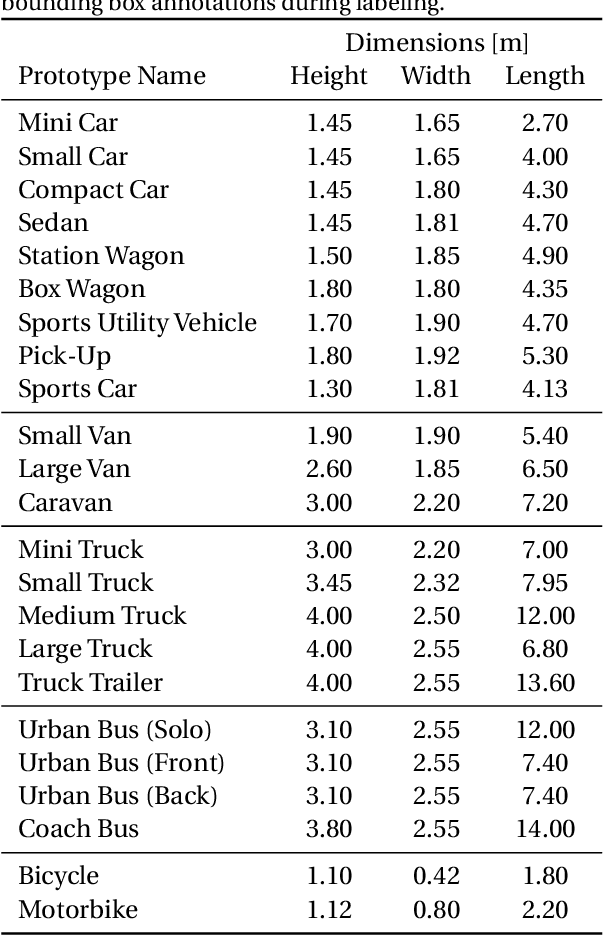
Detecting vehicles and representing their position and orientation in the three dimensional space is a key technology for autonomous driving. Recently, methods for 3D vehicle detection solely based on monocular RGB images gained popularity. In order to facilitate this task as well as to compare and drive state-of-the-art methods, several new datasets and benchmarks have been published. Ground truth annotations of vehicles are usually obtained using lidar point clouds, which often induces errors due to imperfect calibration or synchronization between both sensors. To this end, we propose Cityscapes 3D, extending the original Cityscapes dataset with 3D bounding box annotations for all types of vehicles. In contrast to existing datasets, our 3D annotations were labeled using stereo RGB images only and capture all nine degrees of freedom. This leads to a pixel-accurate reprojection in the RGB image and a higher range of annotations compared to lidar-based approaches. In order to ease multitask learning, we provide a pairing of 2D instance segments with 3D bounding boxes. In addition, we complement the Cityscapes benchmark suite with 3D vehicle detection based on the new annotations as well as metrics presented in this work. Dataset and benchmark are available online.