 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Semantic Stixels via Multimodal Sensor Fusion
Sep 27, 2018
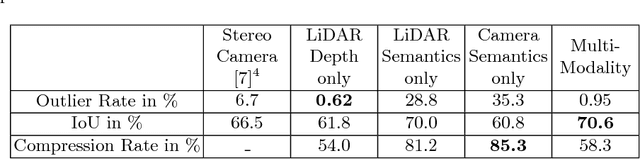
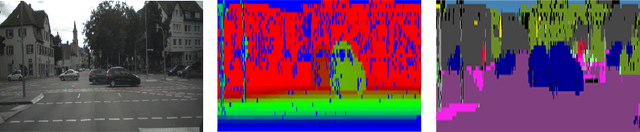
This paper presents a compact and accurate representation of 3D scenes that are observed by a LiDAR sensor and a monocular camera. The proposed method is based on the well-established Stixel model originally developed for stereo vision applications. We extend this Stixel concept to incorporate data from multiple sensor modalities. The resulting mid-level fusion scheme takes full advantage of the geometric accuracy of LiDAR measurements as well as the high resolution and semantic detail of RGB images. The obtained environment model provides a geometrically and semantically consistent representation of the 3D scene at a significantly reduced amount of data while minimizing information loss at the same time. Since the different sensor modalities are considered as input to a joint optimization problem, the solution is obtained with only minor computational overhead. We demonstrate the effectiveness of the proposed multimodal Stixel algorithm on a manually annotated ground truth dataset. Our results indicate that the proposed mid-level fusion of LiDAR and camera data improves both the geometric and semantic accuracy of the Stixel model significantly while reducing the computational overhead as well as the amount of generated data in comparison to using a single modality on its own.
Boosting LiDAR-based Semantic Labeling by Cross-Modal Training Data Generation
Apr 26, 2018



Mobile robots and autonomous vehicles rely on multi-modal sensor setups to perceive and understand their surroundings. Aside from cameras, LiDAR sensors represent a central component of state-of-the-art perception systems. In addition to accurate spatial perception, a comprehensive semantic understanding of the environment is essential for efficient and safe operation. In this paper we present a novel deep neural network architecture called LiLaNet for point-wise, multi-class semantic labeling of semi-dense LiDAR data. The network utilizes virtual image projections of the 3D point clouds for efficient inference. Further, we propose an automated process for large-scale cross-modal training data generation called Autolabeling, in order to boost semantic labeling performance while keeping the manual annotation effort low. The effectiveness of the proposed network architecture as well as the automated data generation process is demonstrated on a manually annotated ground truth dataset. LiLaNet is shown to significantly outperform current state-of-the-art CNN architectures for LiDAR data. Applying our automatically generated large-scale training data yields a boost of up to 14 percentage points compared to networks trained on manually annotated data only.
The Stixel world: A medium-level representation of traffic scenes
Apr 02, 2017

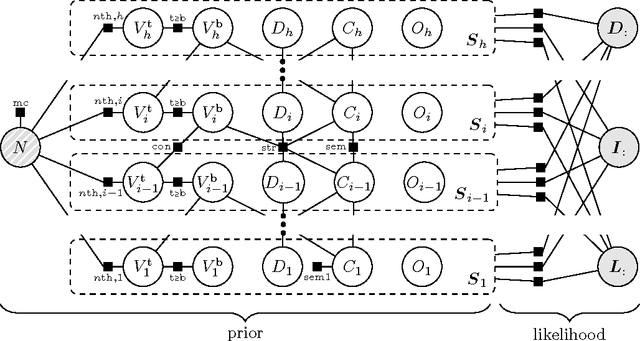

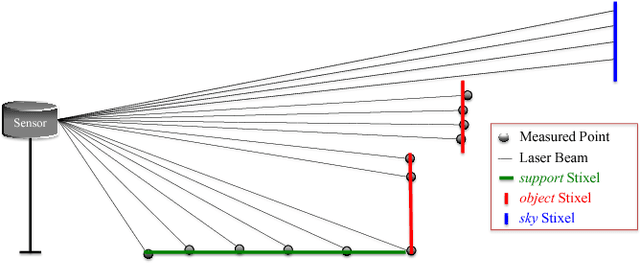
Recent progress in advanced driver assistance systems and the race towards autonomous vehicles is mainly driven by two factors: (1) increasingly sophisticated algorithms that interpret the environment around the vehicle and react accordingly, and (2) the continuous improvements of sensor technology itself. In terms of cameras, these improvements typically include higher spatial resolution, which as a consequence requires more data to be processed. The trend to add multiple cameras to cover the entire surrounding of the vehicle is not conducive in that matter. At the same time, an increasing number of special purpose algorithms need access to the sensor input data to correctly interpret the various complex situations that can occur, particularly in urban traffic. By observing those trends, it becomes clear that a key challenge for vision architectures in intelligent vehicles is to share computational resources. We believe this challenge should be faced by introducing a representation of the sensory data that provides compressed and structured access to all relevant visual content of the scene. The Stixel World discussed in this paper is such a representation. It is a medium-level model of the environment that is specifically designed to compress information about obstacles by leveraging the typical layout of outdoor traffic scenes. It has proven useful for a multitude of automotive vision applications, including object detection, tracking, segmentation, and mapping. In this paper, we summarize the ideas behind the model and generalize it to take into account multiple dense input streams: the image itself, stereo depth maps, and semantic class probability maps that can be generated, e.g., by CNNs. Our generalization is embedded into a novel mathematical formulation for the Stixel model. We further sketch how the free parameters of the model can be learned using structured SVMs.