 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Control Using Model Based Meta Adaption
Oct 07, 2022
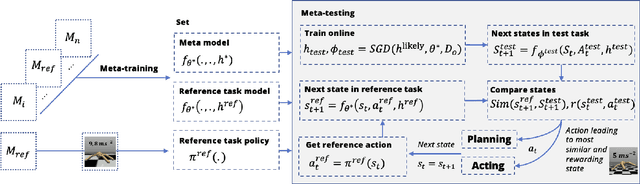

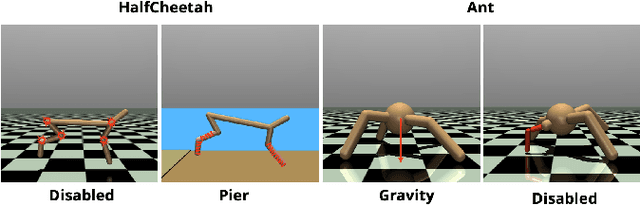
In machine learning, meta-learning methods aim for fast adaptability to unknown tasks using prior knowledge. Model-based meta-reinforcement learning combines reinforcement learning via world models with Meta Reinforcement Learning (MRL) for increased sample efficiency. However, adaption to unknown tasks does not always result in preferable agent behavior. This paper introduces a new Meta Adaptation Controller (MAC) that employs MRL to apply a preferred robot behavior from one task to many similar tasks. To do this, MAC aims to find actions an agent has to take in a new task to reach a similar outcome as in a learned task. As a result, the agent will adapt quickly to the change in the dynamic and behave appropriately without the need to construct a reward function that enforces the preferred behavior.
Sample-Specific Output Constraints for Neural Networks
Mar 23, 2020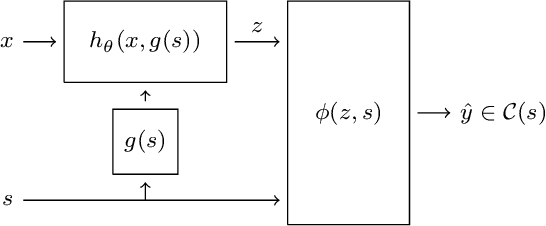
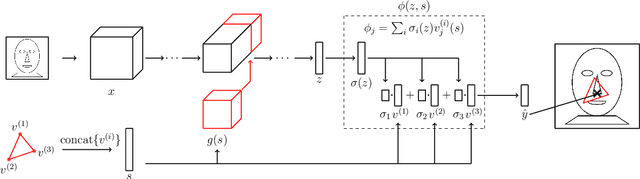
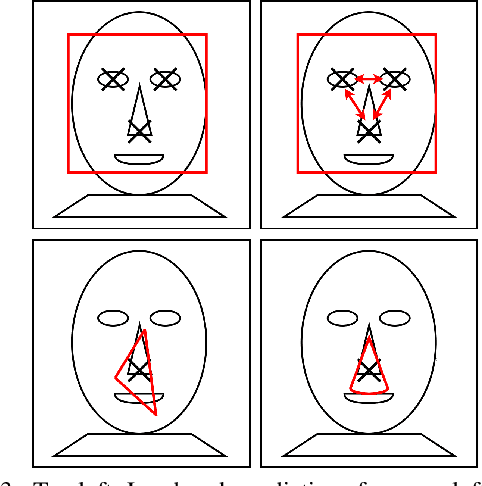
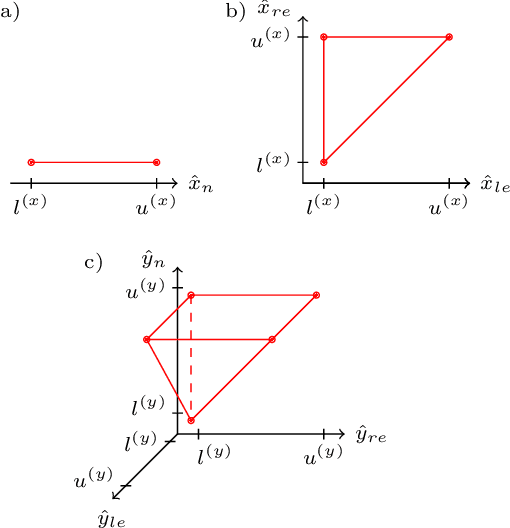
Neural networks reach state-of-the-art performance in a variety of learning tasks. However, a lack of understanding the decision making process yields to an appearance as black box. We address this and propose ConstraintNet, a neural network with the capability to constrain the output space in each forward pass via an additional input. The prediction of ConstraintNet is proven within the specified domain. This enables ConstraintNet to exclude unintended or even hazardous outputs explicitly whereas the final prediction is still learned from data. We focus on constraints in form of convex polytopes and show the generalization to further classes of constraints. ConstraintNet can be constructed easily by modifying existing neural network architectures. We highlight that ConstraintNet is end-to-end trainable with no overhead in the forward and backward pass. For illustration purposes, we model ConstraintNet by modifying a CNN and construct constraints for facial landmark prediction tasks. Furthermore, we demonstrate the application to a follow object controller for vehicles as a safety-critical application. We submitted an approach and system for the generation of safety-critical outputs of an entity based on ConstraintNet at the German Patent and Trademark Office with the official registration mark DE10 2019 119 739.
Analyzing the Cross-Sensor Portability of Neural Network Architectures for LiDAR-based Semantic Labeling
Jul 03, 2019


State-of-the-art approaches for the semantic labeling of LiDAR point clouds heavily rely on the use of deep Convolutional Neural Networks (CNNs). However, transferring network architectures across different LiDAR sensor types represents a significant challenge, especially due to sensor specific design choices with regard to network architecture as well as data representation. In this paper we propose a new CNN architecture for the point-wise semantic labeling of LiDAR data which achieves state-of-the-art results while increasing portability across sensor types. This represents a significant advantage given the fast-paced development of LiDAR hardware technology. We perform a thorough quantitative cross-sensor analysis of semantic labeling performance in comparison to a state-of-the-art reference method. Our evaluation shows that the proposed architecture is indeed highly portable, yielding an improvement of 10 percentage points in the Intersection-over-Union (IoU) score when compared to the reference approach. Further, the results indicate that the proposed network architecture can provide an efficient way for the automated generation of large-scale training data for novel LiDAR sensor types without the need for extensive manual annotation or multi-modal label transfer.
Improved Semantic Stixels via Multimodal Sensor Fusion
Sep 27, 2018
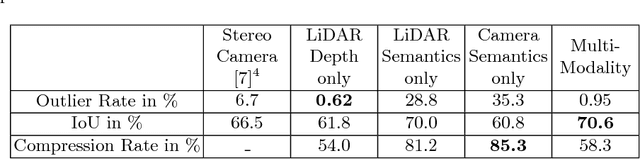
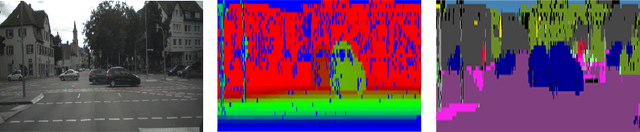
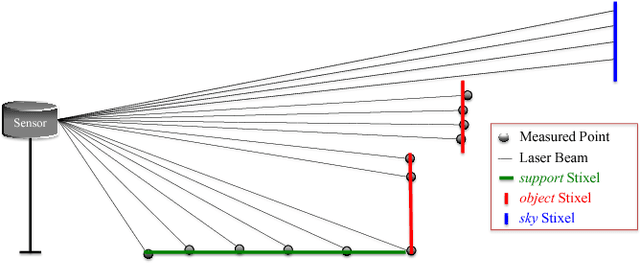
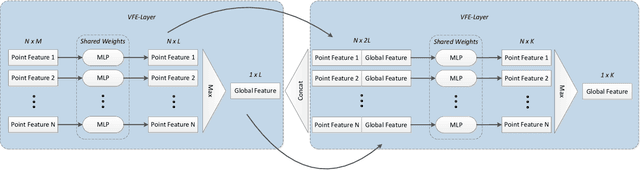
This paper presents a compact and accurate representation of 3D scenes that are observed by a LiDAR sensor and a monocular camera. The proposed method is based on the well-established Stixel model originally developed for stereo vision applications. We extend this Stixel concept to incorporate data from multiple sensor modalities. The resulting mid-level fusion scheme takes full advantage of the geometric accuracy of LiDAR measurements as well as the high resolution and semantic detail of RGB images. The obtained environment model provides a geometrically and semantically consistent representation of the 3D scene at a significantly reduced amount of data while minimizing information loss at the same time. Since the different sensor modalities are considered as input to a joint optimization problem, the solution is obtained with only minor computational overhead. We demonstrate the effectiveness of the proposed multimodal Stixel algorithm on a manually annotated ground truth dataset. Our results indicate that the proposed mid-level fusion of LiDAR and camera data improves both the geometric and semantic accuracy of the Stixel model significantly while reducing the computational overhead as well as the amount of generated data in comparison to using a single modality on its own.
Boosting LiDAR-based Semantic Labeling by Cross-Modal Training Data Generation
Apr 26, 2018



Mobile robots and autonomous vehicles rely on multi-modal sensor setups to perceive and understand their surroundings. Aside from cameras, LiDAR sensors represent a central component of state-of-the-art perception systems. In addition to accurate spatial perception, a comprehensive semantic understanding of the environment is essential for efficient and safe operation. In this paper we present a novel deep neural network architecture called LiLaNet for point-wise, multi-class semantic labeling of semi-dense LiDAR data. The network utilizes virtual image projections of the 3D point clouds for efficient inference. Further, we propose an automated process for large-scale cross-modal training data generation called Autolabeling, in order to boost semantic labeling performance while keeping the manual annotation effort low. The effectiveness of the proposed network architecture as well as the automated data generation process is demonstrated on a manually annotated ground truth dataset. LiLaNet is shown to significantly outperform current state-of-the-art CNN architectures for LiDAR data. Applying our automatically generated large-scale training data yields a boost of up to 14 percentage points compared to networks trained on manually annotated data only.