 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Meta Agnostic Reinforcement Learning
Jun 20, 2024Meta-Reinforcement Learning (Meta-RL) aims to acquire meta-knowledge for quick adaptation to diverse tasks. However, applying these policies in real-world environments presents a significant challenge in balancing rapid adaptability with adherence to environmental constraints. Our novel approach, Constraint Model Agnostic Meta Learning (C-MAML), merges meta learning with constrained optimization to address this challenge. C-MAML enables rapid and efficient task adaptation by incorporating task-specific constraints directly into its meta-algorithm framework during the training phase. This fusion results in safer initial parameters for learning new tasks. We demonstrate the effectiveness of C-MAML in simulated locomotion with wheeled robot tasks of varying complexity, highlighting its practicality and robustness in dynamic environments.
Robotic Control Using Model Based Meta Adaption
Oct 07, 2022
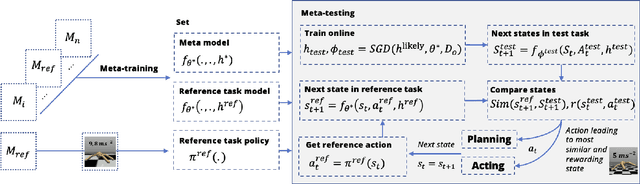

In machine learning, meta-learning methods aim for fast adaptability to unknown tasks using prior knowledge. Model-based meta-reinforcement learning combines reinforcement learning via world models with Meta Reinforcement Learning (MRL) for increased sample efficiency. However, adaption to unknown tasks does not always result in preferable agent behavior. This paper introduces a new Meta Adaptation Controller (MAC) that employs MRL to apply a preferred robot behavior from one task to many similar tasks. To do this, MAC aims to find actions an agent has to take in a new task to reach a similar outcome as in a learned task. As a result, the agent will adapt quickly to the change in the dynamic and behave appropriately without the need to construct a reward function that enforces the preferred behavior.
Safe Continuous Control with Constrained Model-Based Policy Optimization
Apr 14, 2021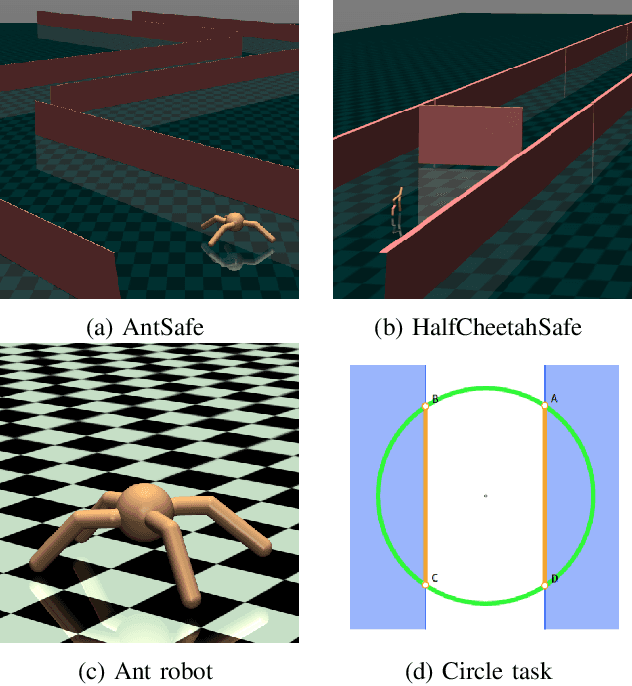
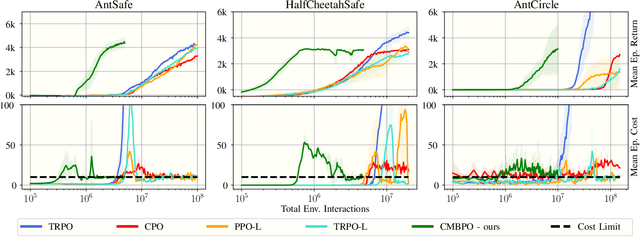
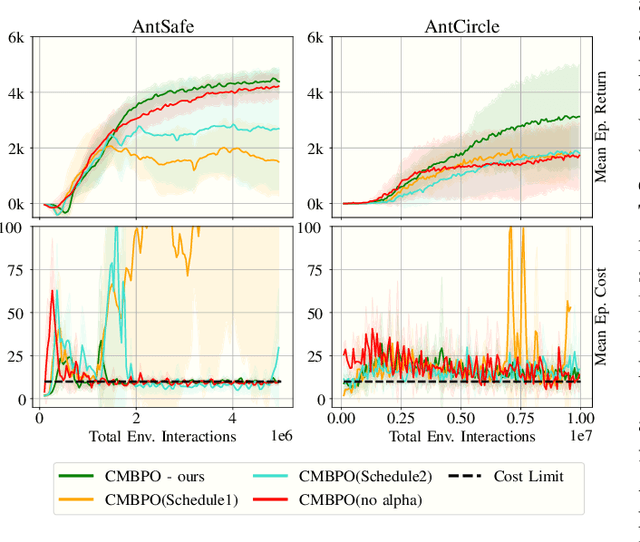

The applicability of reinforcement learning (RL) algorithms in real-world domains often requires adherence to safety constraints, a need difficult to address given the asymptotic nature of the classic RL optimization objective. In contrast to the traditional RL objective, safe exploration considers the maximization of expected returns under safety constraints expressed in expected cost returns. We introduce a model-based safe exploration algorithm for constrained high-dimensional control to address the often prohibitively high sample complexity of model-free safe exploration algorithms. Further, we provide theoretical and empirical analyses regarding the implications of model-usage on constrained policy optimization problems and introduce a practical algorithm that accelerates policy search with model-generated data. The need for accurate estimates of a policy's constraint satisfaction is in conflict with accumulating model-errors. We address this issue by quantifying model-uncertainty as the expected Kullback-Leibler divergence between predictions of an ensemble of probabilistic dynamics models and constrain this error-measure, resulting in an adaptive resampling scheme and dynamically limited rollout horizons. We evaluate this approach on several simulated constrained robot locomotion tasks with high-dimensional action- and state-spaces. Our empirical studies find that our algorithm reaches model-free performances with a 10-20 fold reduction of training samples while maintaining approximate constraint satisfaction levels of model-free methods.
Generalizing Decision Making for Automated Driving with an Invariant Environment Representation using Deep Reinforcement Learning
Feb 12, 2021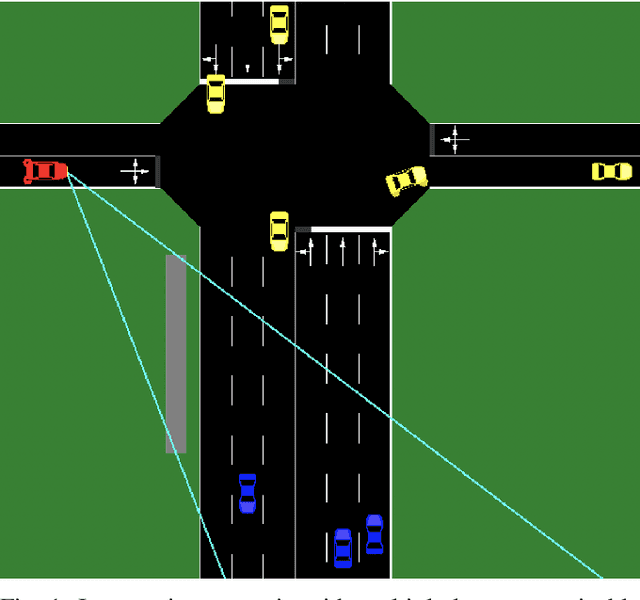
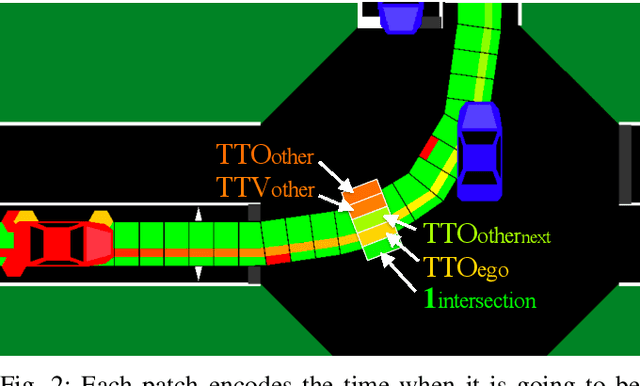
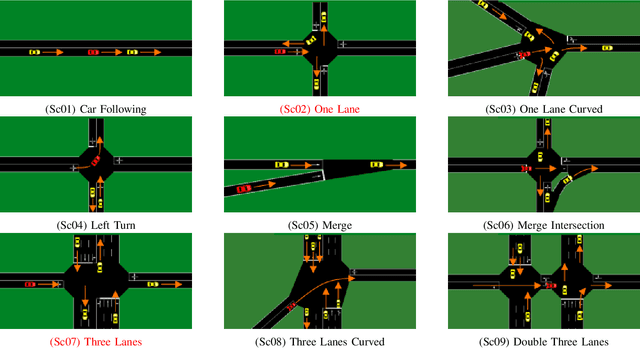
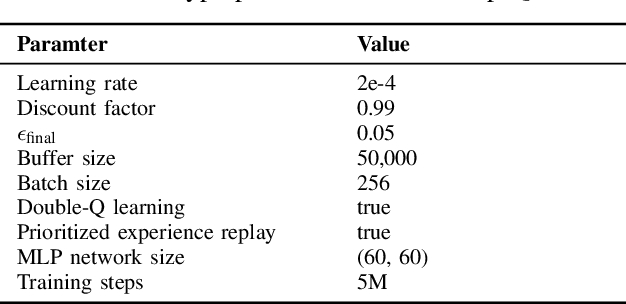
Data driven approaches for decision making applied to automated driving require appropriate generalization strategies, to ensure applicability to the world's variability. Current approaches either do not generalize well beyond the training data or are not capable to consider a variable number of traffic participants. Therefore we propose an invariant environment representation from the perspective of the ego vehicle. The representation encodes all necessary information for safe decision making. To assess the generalization capabilities of the novel environment representation, we train our agents on a small subset of scenarios and evaluate on the entire set. Here we show that the agents are capable to generalize successfully to unseen scenarios, due to the abstraction. In addition we present a simple occlusion model that enables our agents to navigate intersections with occlusions without a significant change in performance.