 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Equivalence of Random Network Distillation, Deep Ensembles, and Bayesian Inference
Feb 26, 2026Uncertainty quantification is central to safe and efficient deployments of deep learning models, yet many computationally practical methods lack lacking rigorous theoretical motivation. Random network distillation (RND) is a lightweight technique that measures novelty via prediction errors against a fixed random target. While empirically effective, it has remained unclear what uncertainties RND measures and how its estimates relate to other approaches, e.g. Bayesian inference or deep ensembles. This paper establishes these missing theoretical connections by analyzing RND within the neural tangent kernel framework in the limit of infinite network width. Our analysis reveals two central findings in this limit: (1) The uncertainty signal from RND -- its squared self-predictive error -- is equivalent to the predictive variance of a deep ensemble. (2) By constructing a specific RND target function, we show that the RND error distribution can be made to mirror the centered posterior predictive distribution of Bayesian inference with wide neural networks. Based on this equivalence, we moreover devise a posterior sampling algorithm that generates i.i.d. samples from an exact Bayesian posterior predictive distribution using this modified \textit{Bayesian RND} model. Collectively, our findings provide a unified theoretical perspective that places RND within the principled frameworks of deep ensembles and Bayesian inference, and offer new avenues for efficient yet theoretically grounded uncertainty quantification methods.
Universal Value-Function Uncertainties
May 27, 2025


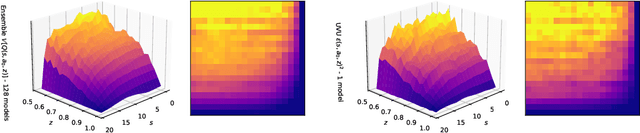
Estimating epistemic uncertainty in value functions is a crucial challenge for many aspects of reinforcement learning (RL), including efficient exploration, safe decision-making, and offline RL. While deep ensembles provide a robust method for quantifying value uncertainty, they come with significant computational overhead. Single-model methods, while computationally favorable, often rely on heuristics and typically require additional propagation mechanisms for myopic uncertainty estimates. In this work we introduce universal value-function uncertainties (UVU), which, similar in spirit to random network distillation (RND), quantify uncertainty as squared prediction errors between an online learner and a fixed, randomly initialized target network. Unlike RND, UVU errors reflect policy-conditional value uncertainty, incorporating the future uncertainties any given policy may encounter. This is due to the training procedure employed in UVU: the online network is trained using temporal difference learning with a synthetic reward derived from the fixed, randomly initialized target network. We provide an extensive theoretical analysis of our approach using neural tangent kernel (NTK) theory and show that in the limit of infinite network width, UVU errors are exactly equivalent to the variance of an ensemble of independent universal value functions. Empirically, we show that UVU achieves equal performance to large ensembles on challenging multi-task offline RL settings, while offering simplicity and substantial computational savings.
How Ensembles of Distilled Policies Improve Generalisation in Reinforcement Learning
May 22, 2025

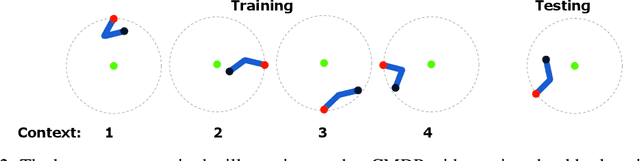

In the zero-shot policy transfer setting in reinforcement learning, the goal is to train an agent on a fixed set of training environments so that it can generalise to similar, but unseen, testing environments. Previous work has shown that policy distillation after training can sometimes produce a policy that outperforms the original in the testing environments. However, it is not yet entirely clear why that is, or what data should be used to distil the policy. In this paper, we prove, under certain assumptions, a generalisation bound for policy distillation after training. The theory provides two practical insights: for improved generalisation, you should 1) train an ensemble of distilled policies, and 2) distil it on as much data from the training environments as possible. We empirically verify that these insights hold in more general settings, when the assumptions required for the theory no longer hold. Finally, we demonstrate that an ensemble of policies distilled on a diverse dataset can generalise significantly better than the original agent.
Contextual Similarity Distillation: Ensemble Uncertainties with a Single Model
Mar 14, 2025
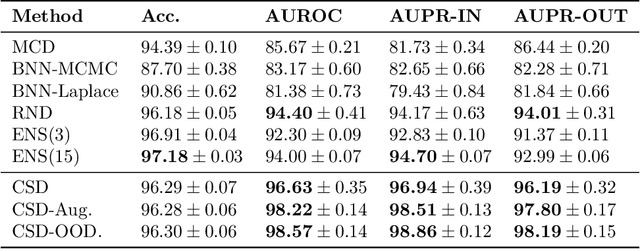
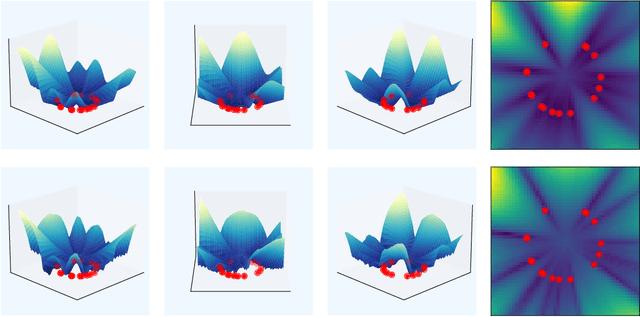

Uncertainty quantification is a critical aspect of reinforcement learning and deep learning, with numerous applications ranging from efficient exploration and stable offline reinforcement learning to outlier detection in medical diagnostics. The scale of modern neural networks, however, complicates the use of many theoretically well-motivated approaches such as full Bayesian inference. Approximate methods like deep ensembles can provide reliable uncertainty estimates but still remain computationally expensive. In this work, we propose contextual similarity distillation, a novel approach that explicitly estimates the variance of an ensemble of deep neural networks with a single model, without ever learning or evaluating such an ensemble in the first place. Our method builds on the predictable learning dynamics of wide neural networks, governed by the neural tangent kernel, to derive an efficient approximation of the predictive variance of an infinite ensemble. Specifically, we reinterpret the computation of ensemble variance as a supervised regression problem with kernel similarities as regression targets. The resulting model can estimate predictive variance at inference time with a single forward pass, and can make use of unlabeled target-domain data or data augmentations to refine its uncertainty estimates. We empirically validate our method across a variety of out-of-distribution detection benchmarks and sparse-reward reinforcement learning environments. We find that our single-model method performs competitively and sometimes superior to ensemble-based baselines and serves as a reliable signal for efficient exploration. These results, we believe, position contextual similarity distillation as a principled and scalable alternative for uncertainty quantification in reinforcement learning and general deep learning.
Value Improved Actor Critic Algorithms
Jun 03, 2024Many modern reinforcement learning algorithms build on the actor-critic (AC) framework: iterative improvement of a policy (the actor) using policy improvement operators and iterative approximation of the policy's value (the critic). In contrast, the popular value-based algorithm family employs improvement operators in the value update, to iteratively improve the value function directly. In this work, we propose a general extension to the AC framework that employs two separate improvement operators: one applied to the policy in the spirit of policy-based algorithms and one applied to the value in the spirit of value-based algorithms, which we dub Value-Improved AC (VI-AC). We design two practical VI-AC algorithms based in the popular online off-policy AC algorithms TD3 and DDPG. We evaluate VI-TD3 and VI-DDPG in the Mujoco benchmark and find that both improve upon or match the performance of their respective baselines in all environments tested.
Diverse Projection Ensembles for Distributional Reinforcement Learning
Jun 12, 2023



In contrast to classical reinforcement learning, distributional reinforcement learning algorithms aim to learn the distribution of returns rather than their expected value. Since the nature of the return distribution is generally unknown a priori or arbitrarily complex, a common approach finds approximations within a set of representable, parametric distributions. Typically, this involves a projection of the unconstrained distribution onto the set of simplified distributions. We argue that this projection step entails a strong inductive bias when coupled with neural networks and gradient descent, thereby profoundly impacting the generalization behavior of learned models. In order to facilitate reliable uncertainty estimation through diversity, this work studies the combination of several different projections and representations in a distributional ensemble. We establish theoretical properties of such projection ensembles and derive an algorithm that uses ensemble disagreement, measured by the average $1$-Wasserstein distance, as a bonus for deep exploration. We evaluate our algorithm on the behavior suite benchmark and find that diverse projection ensembles lead to significant performance improvements over existing methods on a wide variety of tasks with the most pronounced gains in directed exploration problems.
Safe Continuous Control with Constrained Model-Based Policy Optimization
Apr 14, 2021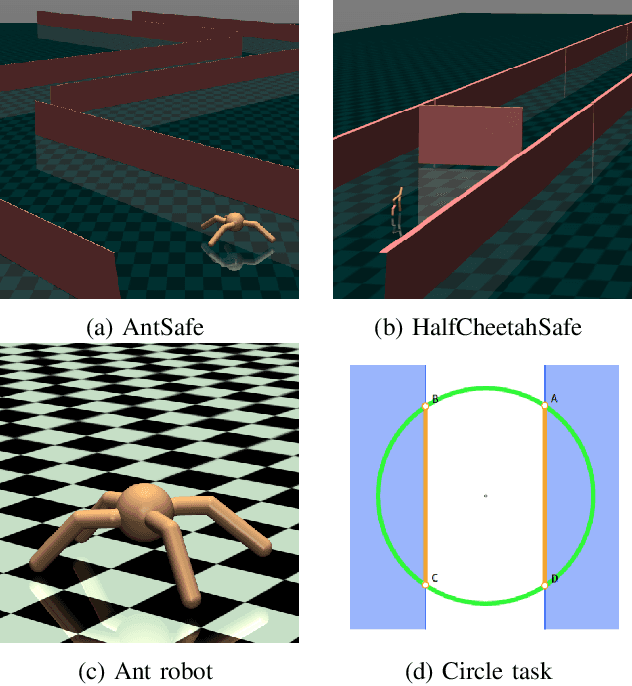
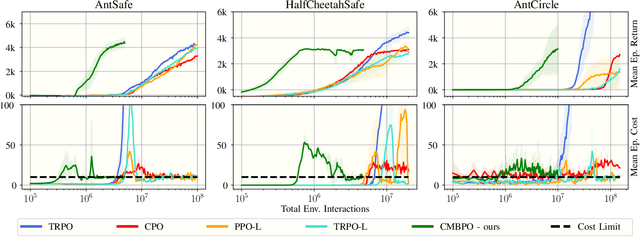
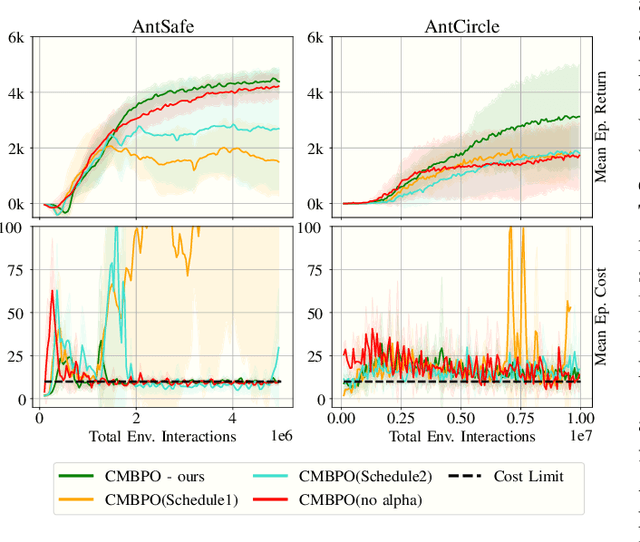

The applicability of reinforcement learning (RL) algorithms in real-world domains often requires adherence to safety constraints, a need difficult to address given the asymptotic nature of the classic RL optimization objective. In contrast to the traditional RL objective, safe exploration considers the maximization of expected returns under safety constraints expressed in expected cost returns. We introduce a model-based safe exploration algorithm for constrained high-dimensional control to address the often prohibitively high sample complexity of model-free safe exploration algorithms. Further, we provide theoretical and empirical analyses regarding the implications of model-usage on constrained policy optimization problems and introduce a practical algorithm that accelerates policy search with model-generated data. The need for accurate estimates of a policy's constraint satisfaction is in conflict with accumulating model-errors. We address this issue by quantifying model-uncertainty as the expected Kullback-Leibler divergence between predictions of an ensemble of probabilistic dynamics models and constrain this error-measure, resulting in an adaptive resampling scheme and dynamically limited rollout horizons. We evaluate this approach on several simulated constrained robot locomotion tasks with high-dimensional action- and state-spaces. Our empirical studies find that our algorithm reaches model-free performances with a 10-20 fold reduction of training samples while maintaining approximate constraint satisfaction levels of model-free methods.