 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Value-Function Uncertainties
May 27, 2025


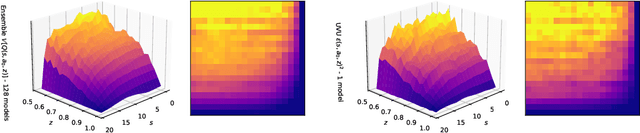
Estimating epistemic uncertainty in value functions is a crucial challenge for many aspects of reinforcement learning (RL), including efficient exploration, safe decision-making, and offline RL. While deep ensembles provide a robust method for quantifying value uncertainty, they come with significant computational overhead. Single-model methods, while computationally favorable, often rely on heuristics and typically require additional propagation mechanisms for myopic uncertainty estimates. In this work we introduce universal value-function uncertainties (UVU), which, similar in spirit to random network distillation (RND), quantify uncertainty as squared prediction errors between an online learner and a fixed, randomly initialized target network. Unlike RND, UVU errors reflect policy-conditional value uncertainty, incorporating the future uncertainties any given policy may encounter. This is due to the training procedure employed in UVU: the online network is trained using temporal difference learning with a synthetic reward derived from the fixed, randomly initialized target network. We provide an extensive theoretical analysis of our approach using neural tangent kernel (NTK) theory and show that in the limit of infinite network width, UVU errors are exactly equivalent to the variance of an ensemble of independent universal value functions. Empirically, we show that UVU achieves equal performance to large ensembles on challenging multi-task offline RL settings, while offering simplicity and substantial computational savings.
Training on more Reachable Tasks for Generalisation in Reinforcement Learning
Oct 04, 2024



In multi-task reinforcement learning, agents train on a fixed set of tasks and have to generalise to new ones. Recent work has shown that increased exploration improves this generalisation, but it remains unclear why exactly that is. In this paper, we introduce the concept of reachability in multi-task reinforcement learning and show that an initial exploration phase increases the number of reachable tasks the agent is trained on. This, and not the increased exploration, is responsible for the improved generalisation, even to unreachable tasks. Inspired by this, we propose a novel method Explore-Go that implements such an exploration phase at the beginning of each episode. Explore-Go only modifies the way experience is collected and can be used with most existing on-policy or off-policy reinforcement learning algorithms. We demonstrate the effectiveness of our method when combined with some popular algorithms and show an increase in generalisation performance across several environments.
PettingZoo: Gym for Multi-Agent Reinforcement Learning
Sep 30, 2020
OpenAI's Gym library contains a large, diverse set of environments that are useful benchmarks in reinforcement learning, under a single elegant Python API (with tools to develop new compliant environments) . The introduction of this library has proven a watershed moment for the reinforcement learning community, because it created an accessible set of benchmark environments that everyone could use (including wrapper important existing libraries), and because a standardized API let RL learning methods and environments from anywhere be trivially exchanged. This paper similarly introduces PettingZoo, a library of diverse set of multi-agent environments under a single elegant Python API, with tools to easily make new compliant environments.
Agent Environment Cycle Games
Sep 28, 2020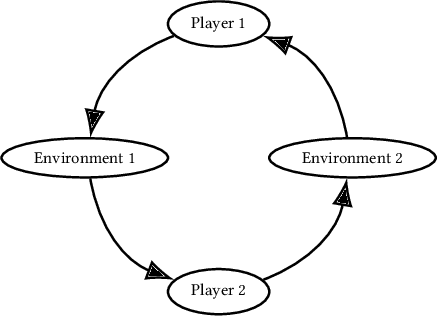
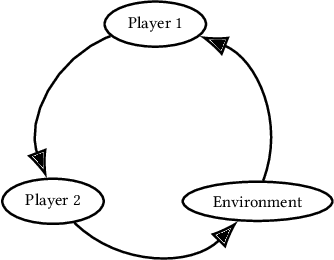

Partially Observable Stochastic Games (POSGs), are the most general model of games used in Multi-Agent Reinforcement Learning (MARL), modeling actions and observations as happening sequentially for all agents. We introduce Agent Environment Cycle Games (AEC Games), a model of games based on sequential agent actions and observations. AEC Games can be thought of as sequential versions of POSGs, and we prove that they are equally powerful. We argue conceptually and through case studies that the AEC games model is useful in important scenarios in MARL for which the POSG model is not well suited. We additionally introduce "cyclically expansive curriculum learning," a new MARL curriculum learning method motivated by the AEC games model. It can be applied "for free," and experimentally we show this technique to achieve up to 35.1% more total reward on average.