 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCliff Diving: Exploring Reward Surfaces in Reinforcement Learning Environments
May 17, 2022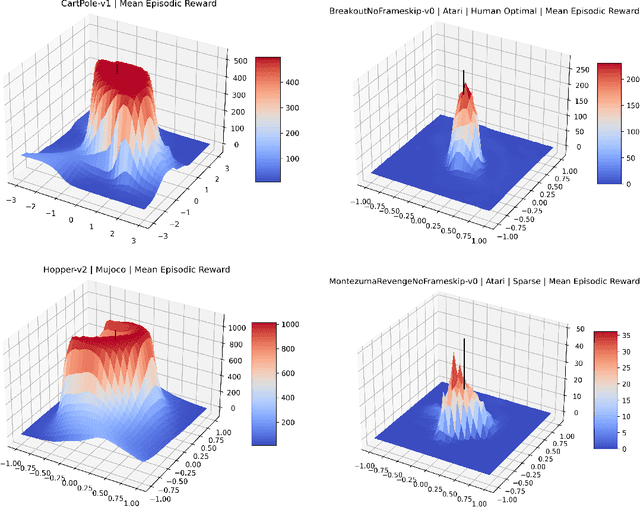
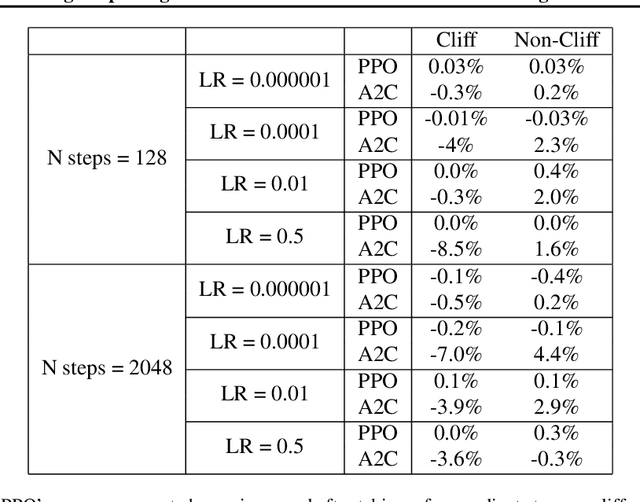
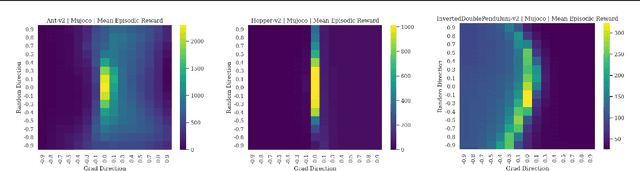
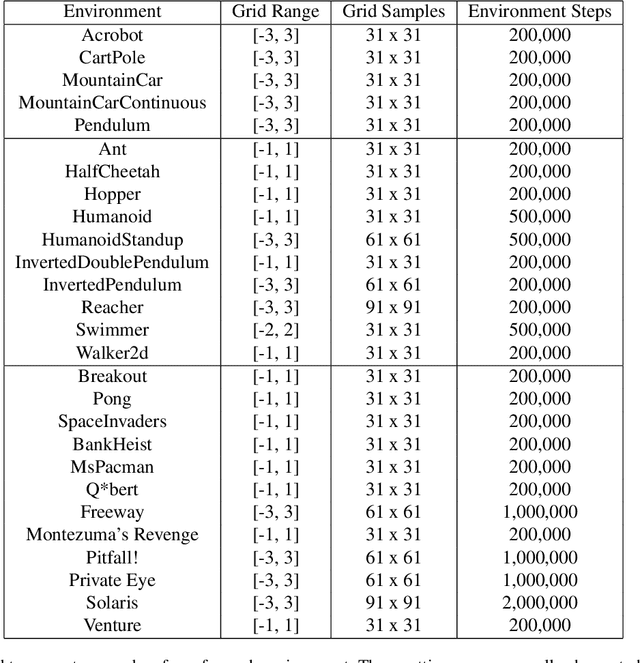
Visualizing optimization landscapes has led to many fundamental insights in numeric optimization, and novel improvements to optimization techniques. However, visualizations of the objective that reinforcement learning optimizes (the "reward surface") have only ever been generated for a small number of narrow contexts. This work presents reward surfaces and related visualizations of 27 of the most widely used reinforcement learning environments in Gym for the first time. We also explore reward surfaces in the policy gradient direction and show for the first time that many popular reinforcement learning environments have frequent "cliffs" (sudden large drops in expected return). We demonstrate that A2C often "dives off" these cliffs into low reward regions of the parameter space while PPO avoids them, confirming a popular intuition for PPO's improved performance over previous methods. We additionally introduce a highly extensible library that allows researchers to easily generate these visualizations in the future. Our findings provide new intuition to explain the successes and failures of modern RL methods, and our visualizations concretely characterize several failure modes of reinforcement learning agents in novel ways.
PettingZoo: Gym for Multi-Agent Reinforcement Learning
Sep 30, 2020
OpenAI's Gym library contains a large, diverse set of environments that are useful benchmarks in reinforcement learning, under a single elegant Python API (with tools to develop new compliant environments) . The introduction of this library has proven a watershed moment for the reinforcement learning community, because it created an accessible set of benchmark environments that everyone could use (including wrapper important existing libraries), and because a standardized API let RL learning methods and environments from anywhere be trivially exchanged. This paper similarly introduces PettingZoo, a library of diverse set of multi-agent environments under a single elegant Python API, with tools to easily make new compliant environments.
Agent Environment Cycle Games
Sep 28, 2020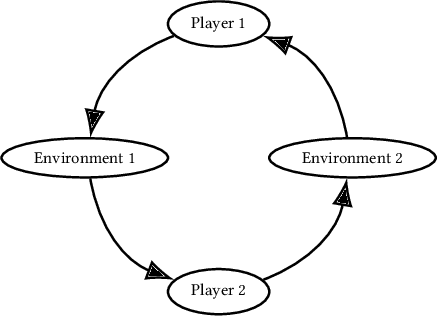
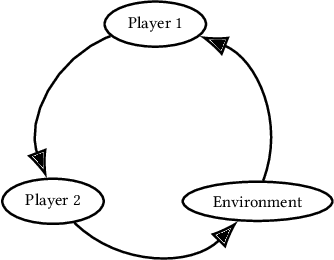

Partially Observable Stochastic Games (POSGs), are the most general model of games used in Multi-Agent Reinforcement Learning (MARL), modeling actions and observations as happening sequentially for all agents. We introduce Agent Environment Cycle Games (AEC Games), a model of games based on sequential agent actions and observations. AEC Games can be thought of as sequential versions of POSGs, and we prove that they are equally powerful. We argue conceptually and through case studies that the AEC games model is useful in important scenarios in MARL for which the POSG model is not well suited. We additionally introduce "cyclically expansive curriculum learning," a new MARL curriculum learning method motivated by the AEC games model. It can be applied "for free," and experimentally we show this technique to achieve up to 35.1% more total reward on average.
Multiplayer Support for the Arcade Learning Environment
Sep 20, 2020


The Arcade Learning Environment ("ALE") is a widely used library in the reinforcement learning community that allows easy program-matic interfacing with Atari 2600 games, via the Stella emulator. We introduce a publicly available extension to the ALE that extends its support to multiplayer games and game modes. This interface is additionally integrated with PettingZoo to allow for a simple Gym-like interface in Python to interact with these games.
SuperSuit: Simple Microwrappers for Reinforcement Learning Environments
Aug 17, 2020In reinforcement learning, wrappers are universally used to transform the information that passes between a model and an environment. Despite their ubiquity, no library exists with reasonable implementations of all popular preprocessing methods. This leads to unnecessary bugs, code inefficiencies, and wasted developer time. Accordingly we introduce SuperSuit, a Python library that includes all popular wrappers, and wrappers that can easily apply lambda functions to the observations/actions/reward. It's compatible with the standard Gym environment specification, as well as the PettingZoo specification for multi-agent environments. The library is available at https://github.com/PettingZoo-Team/SuperSuit,and can be installed via pip.