 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCliff Diving: Exploring Reward Surfaces in Reinforcement Learning Environments
May 17, 2022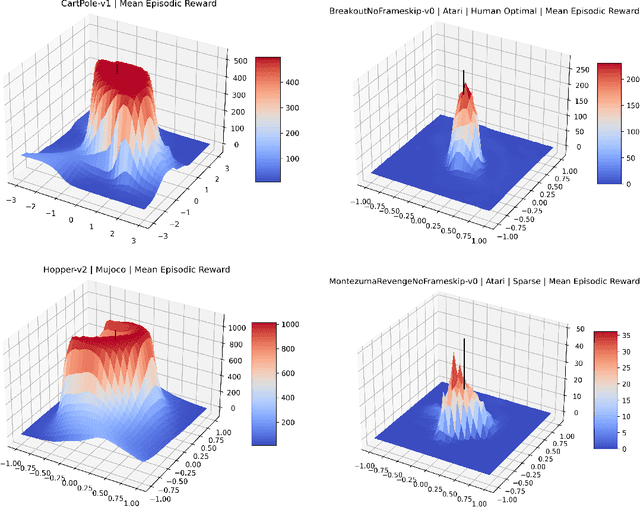
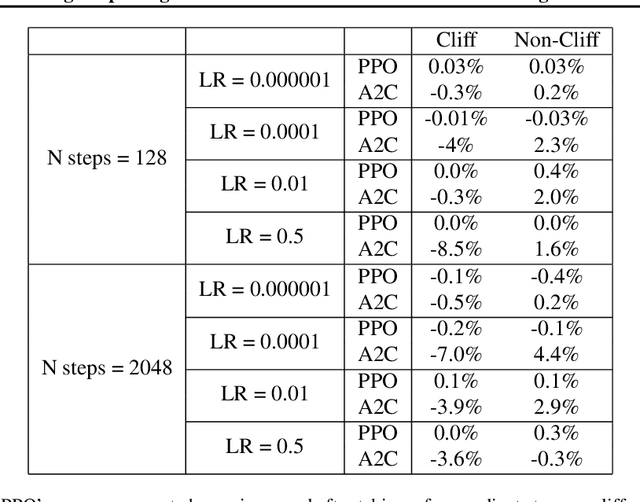
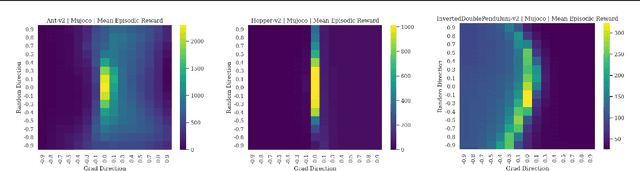
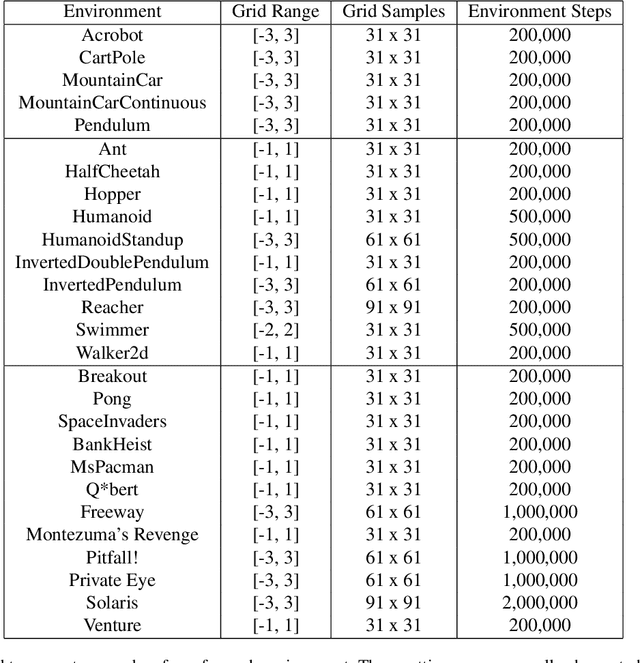
Visualizing optimization landscapes has led to many fundamental insights in numeric optimization, and novel improvements to optimization techniques. However, visualizations of the objective that reinforcement learning optimizes (the "reward surface") have only ever been generated for a small number of narrow contexts. This work presents reward surfaces and related visualizations of 27 of the most widely used reinforcement learning environments in Gym for the first time. We also explore reward surfaces in the policy gradient direction and show for the first time that many popular reinforcement learning environments have frequent "cliffs" (sudden large drops in expected return). We demonstrate that A2C often "dives off" these cliffs into low reward regions of the parameter space while PPO avoids them, confirming a popular intuition for PPO's improved performance over previous methods. We additionally introduce a highly extensible library that allows researchers to easily generate these visualizations in the future. Our findings provide new intuition to explain the successes and failures of modern RL methods, and our visualizations concretely characterize several failure modes of reinforcement learning agents in novel ways.
Statistically Significant Stopping of Neural Network Training
Mar 21, 2021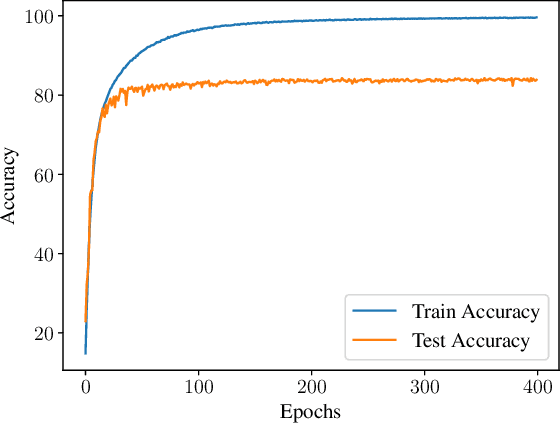
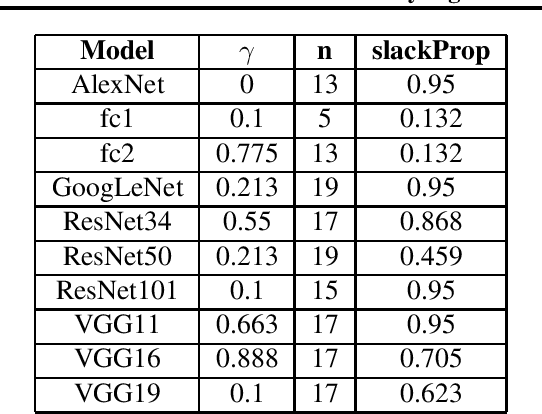
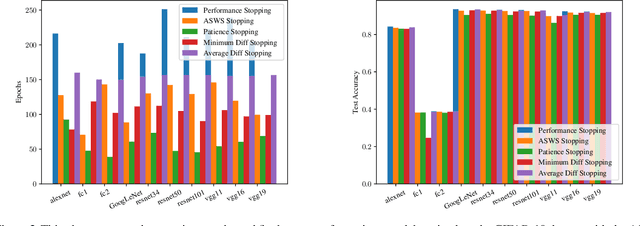

The general approach taken when training deep learning classifiers is to save the parameters after every few iterations, train until either a human observer or a simple metric-based heuristic decides the network isn't learning anymore, and then backtrack and pick the saved parameters with the best validation accuracy. Simple methods are used to determine if a neural network isn't learning anymore because, as long as it's well after the optimal values are found, the condition doesn't impact the final accuracy of the model. However from a runtime perspective, this is of great significance to the many cases where numerous neural networks are trained simultaneously (e.g. hyper-parameter tuning). Motivated by this, we introduce a statistical significance test to determine if a neural network has stopped learning. This stopping criterion appears to represent a happy medium compared to other popular stopping criterions, achieving comparable accuracy to the criterions that achieve the highest final accuracies in 77% or fewer epochs, while the criterions which stop sooner do so with an appreciable loss to final accuracy. Additionally, we use this as the basis of a new learning rate scheduler, removing the need to manually choose learning rate schedules and acting as a quasi-line search, achieving superior or comparable empirical performance to existing methods.