 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Stixel world: A medium-level representation of traffic scenes
Paper and Code
Apr 02, 2017

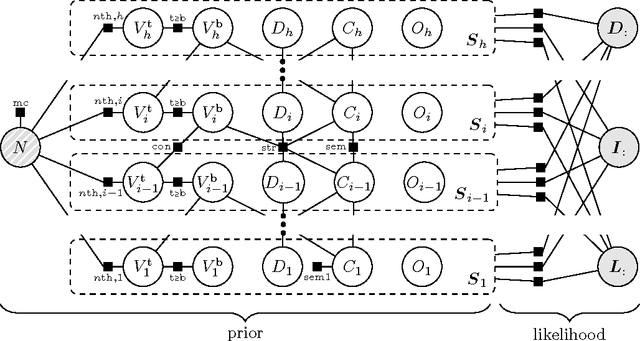

Recent progress in advanced driver assistance systems and the race towards autonomous vehicles is mainly driven by two factors: (1) increasingly sophisticated algorithms that interpret the environment around the vehicle and react accordingly, and (2) the continuous improvements of sensor technology itself. In terms of cameras, these improvements typically include higher spatial resolution, which as a consequence requires more data to be processed. The trend to add multiple cameras to cover the entire surrounding of the vehicle is not conducive in that matter. At the same time, an increasing number of special purpose algorithms need access to the sensor input data to correctly interpret the various complex situations that can occur, particularly in urban traffic. By observing those trends, it becomes clear that a key challenge for vision architectures in intelligent vehicles is to share computational resources. We believe this challenge should be faced by introducing a representation of the sensory data that provides compressed and structured access to all relevant visual content of the scene. The Stixel World discussed in this paper is such a representation. It is a medium-level model of the environment that is specifically designed to compress information about obstacles by leveraging the typical layout of outdoor traffic scenes. It has proven useful for a multitude of automotive vision applications, including object detection, tracking, segmentation, and mapping. In this paper, we summarize the ideas behind the model and generalize it to take into account multiple dense input streams: the image itself, stereo depth maps, and semantic class probability maps that can be generated, e.g., by CNNs. Our generalization is embedded into a novel mathematical formulation for the Stixel model. We further sketch how the free parameters of the model can be learned using structured SVMs.