 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNCOVER: Unknown Class Object Detection for Autonomous Vehicles in Real-time
Dec 05, 2024



Autonomous driving (AD) operates in open-world scenarios, where encountering unknown objects is inevitable. However, standard object detectors trained on a limited number of base classes tend to ignore any unknown objects, posing potential risks on the road. To address this, it is important to learn a generic rather than a class specific objectness from objects seen during training. We therefore introduce an occupancy prediction together with bounding box regression. It learns to score the objectness by calculating the ratio of the predicted area occupied by actual objects. To enhance its generalizability, we increase the object diversity by exploiting data from other domains via Mosaic and Mixup augmentation. The objects outside the AD training classes are classified as a newly added out-of-distribution (OOD) class. Our solution UNCOVER, for UNknown Class Object detection for autonomous VEhicles in Real-time, excels at achieving both real-time detection and high recall of unknown objects on challenging AD benchmarks. To further attain very low false positive rates, particularly for close objects, we introduce a post-hoc filtering step that utilizes geometric cues extracted from the depth map, typically available within the AD system.
Annotating Ambiguous Images: General Annotation Strategy for Image Classification with Real-World Biomedical Validation on Vertebral Fracture Diagnosis
Jun 21, 2023
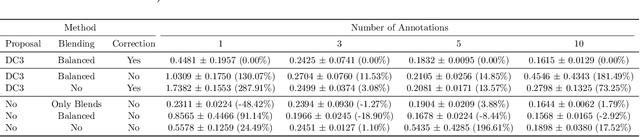
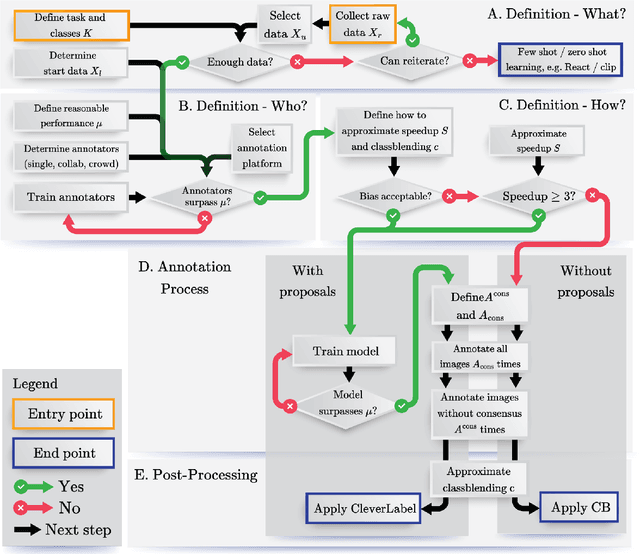

While numerous methods exist to solve classification problems within curated datasets, these solutions often fall short in biomedical applications due to the biased or ambiguous nature of the data. These difficulties are particularly evident when inferring height reduction from vertebral data, a key component of the clinically-recognized Genant score. Although strategies such as semi-supervised learning, proposal usage, and class blending may provide some resolution, a clear and superior solution remains elusive. This paper introduces a flowchart of general strategy to address these issues. We demonstrate the application of this strategy by constructing a vertebral fracture dataset with over 300,000 annotations. This work facilitates the transition of the classification problem into clinically meaningful scores and enriches our understanding of vertebral height reduction.
Label Smarter, Not Harder: CleverLabel for Faster Annotation of Ambiguous Image Classification with Higher Quality
May 22, 2023



High-quality data is crucial for the success of machine learning, but labeling large datasets is often a time-consuming and costly process. While semi-supervised learning can help mitigate the need for labeled data, label quality remains an open issue due to ambiguity and disagreement among annotators. Thus, we use proposal-guided annotations as one option which leads to more consistency between annotators. However, proposing a label increases the probability of the annotators deciding in favor of this specific label. This introduces a bias which we can simulate and remove. We propose a new method CleverLabel for Cost-effective LabEling using Validated proposal-guidEd annotations and Repaired LABELs. CleverLabel can reduce labeling costs by up to 30.0%, while achieving a relative improvement in Kullback-Leibler divergence of up to 29.8% compared to the previous state-of-the-art on a multi-domain real-world image classification benchmark. CleverLabel offers a novel solution to the challenge of efficiently labeling large datasets while also improving the label quality.
Opportunistic hip fracture risk prediction in Men from X-ray: Findings from the Osteoporosis in Men (MrOS) Study
Jul 22, 2022



Osteoporosis is a common disease that increases fracture risk. Hip fractures, especially in elderly people, lead to increased morbidity, decreased quality of life and increased mortality. Being a silent disease before fracture, osteoporosis often remains undiagnosed and untreated. Areal bone mineral density (aBMD) assessed by dual-energy X-ray absorptiometry (DXA) is the gold-standard method for osteoporosis diagnosis and hence also for future fracture prediction (prognostic). However, the required special equipment is not broadly available everywhere, in particular not to patients in developing countries. We propose a deep learning classification model (FORM) that can directly predict hip fracture risk from either plain radiographs (X-ray) or 2D projection images of computed tomography (CT) data. Our method is fully automated and therefore well suited for opportunistic screening settings, identifying high risk patients in a broader population without additional screening. FORM was trained and evaluated on X-rays and CT projections from the Osteoporosis in Men (MrOS) study. 3108 X-rays (89 incident hip fractures) or 2150 CTs (80 incident hip fractures) with a 80/20 split were used. We show that FORM can correctly predict the 10-year hip fracture risk with a validation AUC of 81.44 +- 3.11% / 81.04 +- 5.54% (mean +- STD) including additional information like age, BMI, fall history and health background across a 5-fold cross validation on the X-ray and CT cohort, respectively. Our approach significantly (p < 0.01) outperforms previous methods like Cox Proportional-Hazards Model and \frax with 70.19 +- 6.58 and 74.72 +- 7.21 respectively on the X-ray cohort. Our model outperform on both cohorts hip aBMD based predictions. We are confident that FORM can contribute on improving osteoporosis diagnosis at an early stage.
Beyond Hard Labels: Investigating data label distributions
Jul 13, 2022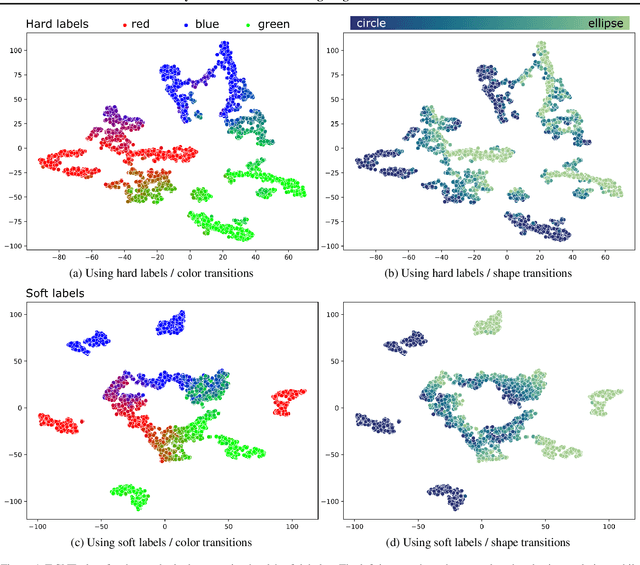

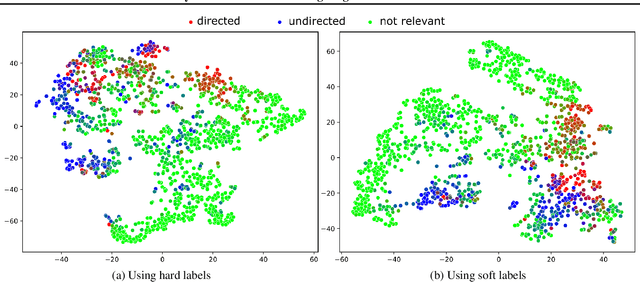
High-quality data is a key aspect of modern machine learning. However, labels generated by humans suffer from issues like label noise and class ambiguities. We raise the question of whether hard labels are sufficient to represent the underlying ground truth distribution in the presence of these inherent imprecision. Therefore, we compare the disparity of learning with hard and soft labels quantitatively and qualitatively for a synthetic and a real-world dataset. We show that the application of soft labels leads to improved performance and yields a more regular structure of the internal feature space.
Is one annotation enough? A data-centric image classification benchmark for noisy and ambiguous label estimation
Jul 13, 2022
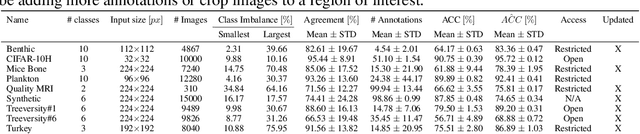
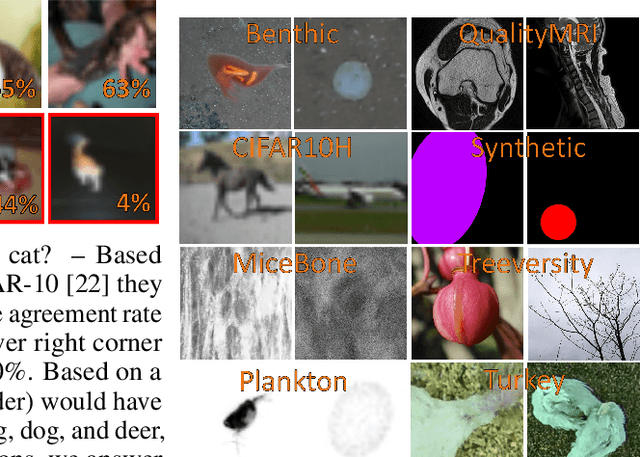
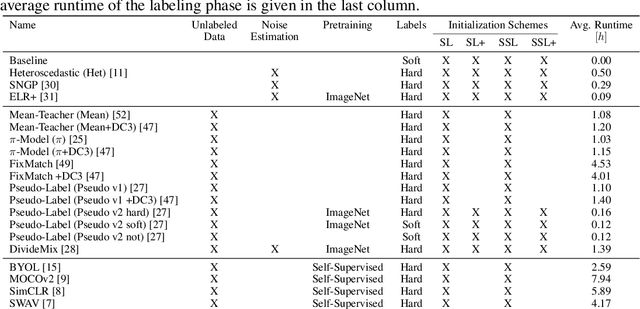
High-quality data is necessary for modern machine learning. However, the acquisition of such data is difficult due to noisy and ambiguous annotations of humans. The aggregation of such annotations to determine the label of an image leads to a lower data quality. We propose a data-centric image classification benchmark with nine real-world datasets and multiple annotations per image to investigate and quantify the impact of such data quality issues. We focus on a data-centric perspective by asking how we could improve the data quality. Across thousands of experiments, we show that multiple annotations allow a better approximation of the real underlying class distribution. We identify that hard labels can not capture the ambiguity of the data and this might lead to the common issue of overconfident models. Based on the presented datasets, benchmark baselines, and analysis, we create multiple research opportunities for the future.
Fuzzy Overclustering: Semi-Supervised Classification of Fuzzy Labels with Overclustering and Inverse Cross-Entropy
Oct 13, 2021



Deep learning has been successfully applied to many classification problems including underwater challenges. However, a long-standing issue with deep learning is the need for large and consistently labeled datasets. Although current approaches in semi-supervised learning can decrease the required amount of annotated data by a factor of 10 or even more, this line of research still uses distinct classes. For underwater classification, and uncurated real-world datasets in general, clean class boundaries can often not be given due to a limited information content in the images and transitional stages of the depicted objects. This leads to different experts having different opinions and thus producing fuzzy labels which could also be considered ambiguous or divergent. We propose a novel framework for handling semi-supervised classifications of such fuzzy labels. It is based on the idea of overclustering to detect substructures in these fuzzy labels. We propose a novel loss to improve the overclustering capability of our framework and show the benefit of overclustering for fuzzy labels. We show that our framework is superior to previous state-of-the-art semi-supervised methods when applied to real-world plankton data with fuzzy labels. Moreover, we acquire 5 to 10\% more consistent predictions of substructures.
* Source code: https://github.com/Emprime/FuzzyOverclustering Datasets: https://doi.org/10.5281/zenodo.5550918. arXiv admin note: substantial text overlap with arXiv:2012.01768
Life is not black and white -- Combining Semi-Supervised Learning with fuzzy labels
Oct 13, 2021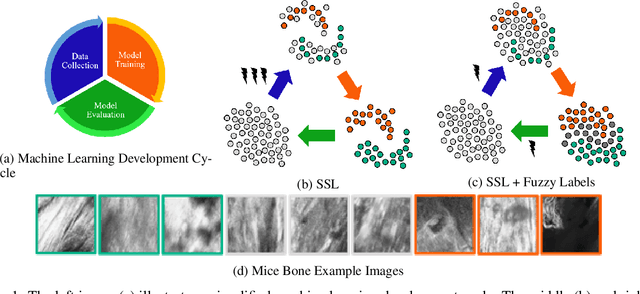
The required amount of labeled data is one of the biggest issues in deep learning. Semi-Supervised Learning can potentially solve this issue by using additional unlabeled data. However, many datasets suffer from variability in the annotations. The aggregated labels from these annotation are not consistent between different annotators and thus are considered fuzzy. These fuzzy labels are often not considered by Semi-Supervised Learning. This leads either to an inferior performance or to higher initial annotation costs in the complete machine learning development cycle. We envision the incorporation of fuzzy labels into Semi-Supervised Learning and give a proof-of-concept of the potential lower costs and higher consistency in the complete development cycle. As part of our concept, we discuss current limitations, futures research opportunities and potential broad impacts.
Learning Stixel-based Instance Segmentation
Jul 07, 2021Stixels have been successfully applied to a wide range of vision tasks in autonomous driving, recently including instance segmentation. However, due to their sparse occurrence in the image, until now Stixels seldomly served as input for Deep Learning algorithms, restricting their utility for such approaches. In this work we present StixelPointNet, a novel method to perform fast instance segmentation directly on Stixels. By regarding the Stixel representation as unstructured data similar to point clouds, architectures like PointNet are able to learn features from Stixels. We use a bounding box detector to propose candidate instances, for which the relevant Stixels are extracted from the input image. On these Stixels, a PointNet models learns binary segmentations, which we then unify throughout the whole image in a final selection step. StixelPointNet achieves state-of-the-art performance on Stixel-level, is considerably faster than pixel-based segmentation methods, and shows that with our approach the Stixel domain can be introduced to many new 3D Deep Learning tasks.
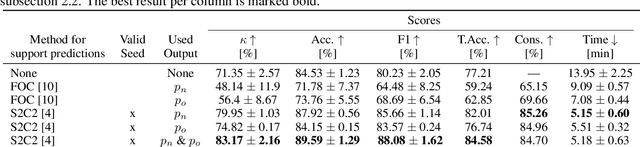
S2C2 - An orthogonal method for Semi-Supervised Learning on fuzzy labels
Jun 30, 2021
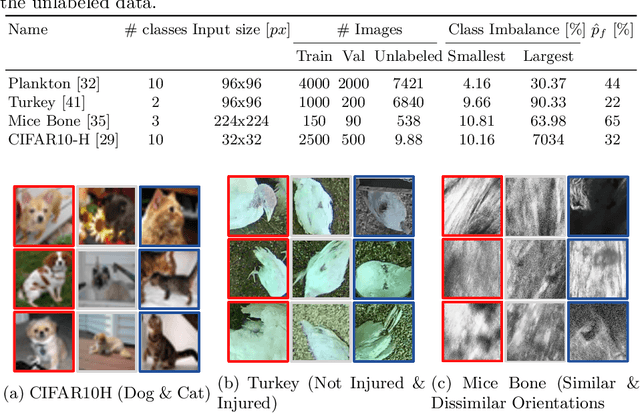
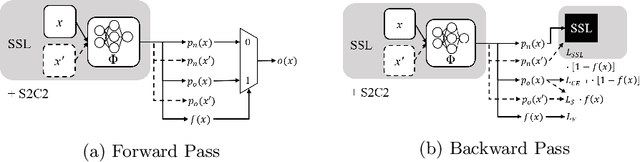

Semi-Supervised Learning (SSL) can decrease the amount of required labeled image data and thus the cost for deep learning. Most SSL methods only consider a clear distinction between classes but in many real-world datasets, this clear distinction is not given due to intra- or interobserver variability. This variability can lead to different annotations per image. Thus many images have ambiguous annotations and their label needs to be considered "fuzzy". This fuzziness of labels must be addressed as it will limit the performance of Semi-Supervised Learning (SSL) and deep learning in general. We propose Semi-Supervised Classification & Clustering (S2C2) which can extend many deep SSL algorithms. S2C2 can estimate the fuzziness of a label and applies SSL as a classification to certainly labeled data while creating distinct clusters for images with similar but fuzzy labels. We show that S2C2 results in median 7.4% better F1-score for classifications and 5.4% lower inner distance of clusters across multiple SSL algorithms and datasets while being more interpretable due to the fuzziness estimation of our method. Overall, a combination of Semi-Supervised Learning with our method S2C2 leads to better handling of the fuzziness of labels and thus real-world datasets.