 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotating Ambiguous Images: General Annotation Strategy for Image Classification with Real-World Biomedical Validation on Vertebral Fracture Diagnosis
Jun 21, 2023
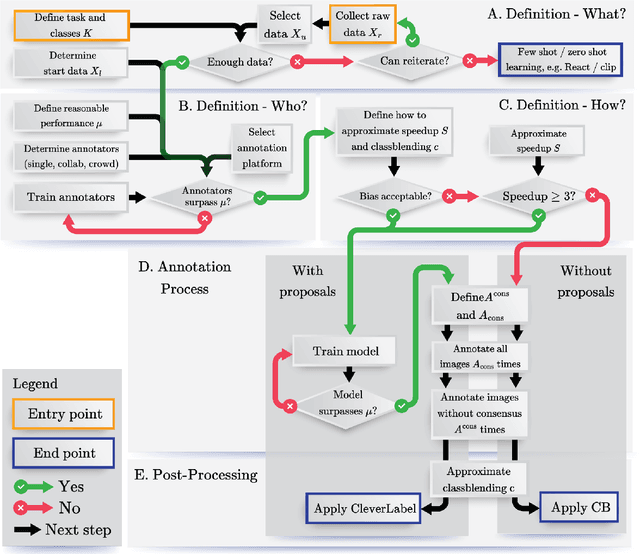

While numerous methods exist to solve classification problems within curated datasets, these solutions often fall short in biomedical applications due to the biased or ambiguous nature of the data. These difficulties are particularly evident when inferring height reduction from vertebral data, a key component of the clinically-recognized Genant score. Although strategies such as semi-supervised learning, proposal usage, and class blending may provide some resolution, a clear and superior solution remains elusive. This paper introduces a flowchart of general strategy to address these issues. We demonstrate the application of this strategy by constructing a vertebral fracture dataset with over 300,000 annotations. This work facilitates the transition of the classification problem into clinically meaningful scores and enriches our understanding of vertebral height reduction.
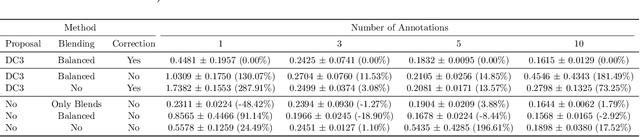
Label Smarter, Not Harder: CleverLabel for Faster Annotation of Ambiguous Image Classification with Higher Quality
May 22, 2023



High-quality data is crucial for the success of machine learning, but labeling large datasets is often a time-consuming and costly process. While semi-supervised learning can help mitigate the need for labeled data, label quality remains an open issue due to ambiguity and disagreement among annotators. Thus, we use proposal-guided annotations as one option which leads to more consistency between annotators. However, proposing a label increases the probability of the annotators deciding in favor of this specific label. This introduces a bias which we can simulate and remove. We propose a new method CleverLabel for Cost-effective LabEling using Validated proposal-guidEd annotations and Repaired LABELs. CleverLabel can reduce labeling costs by up to 30.0%, while achieving a relative improvement in Kullback-Leibler divergence of up to 29.8% compared to the previous state-of-the-art on a multi-domain real-world image classification benchmark. CleverLabel offers a novel solution to the challenge of efficiently labeling large datasets while also improving the label quality.
Beyond Hard Labels: Investigating data label distributions
Jul 13, 2022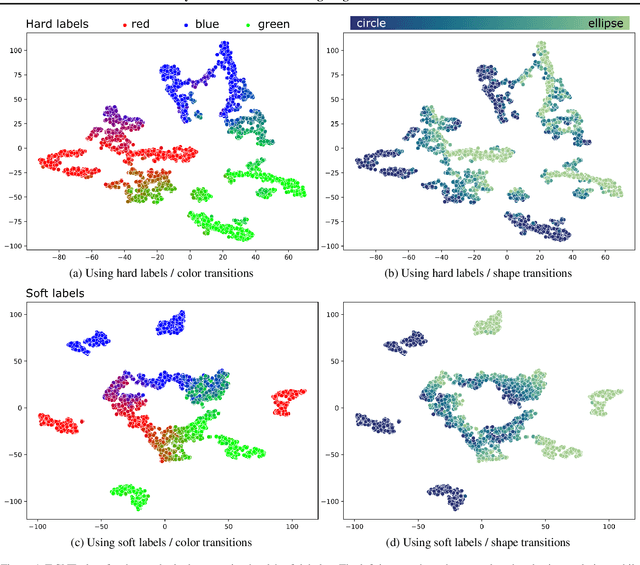

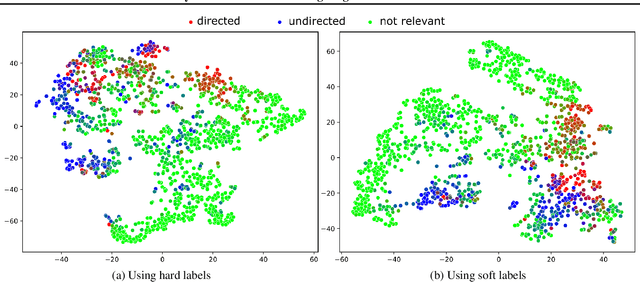
High-quality data is a key aspect of modern machine learning. However, labels generated by humans suffer from issues like label noise and class ambiguities. We raise the question of whether hard labels are sufficient to represent the underlying ground truth distribution in the presence of these inherent imprecision. Therefore, we compare the disparity of learning with hard and soft labels quantitatively and qualitatively for a synthetic and a real-world dataset. We show that the application of soft labels leads to improved performance and yields a more regular structure of the internal feature space.
Is one annotation enough? A data-centric image classification benchmark for noisy and ambiguous label estimation
Jul 13, 2022
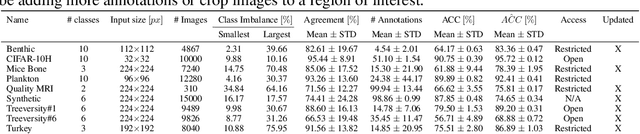
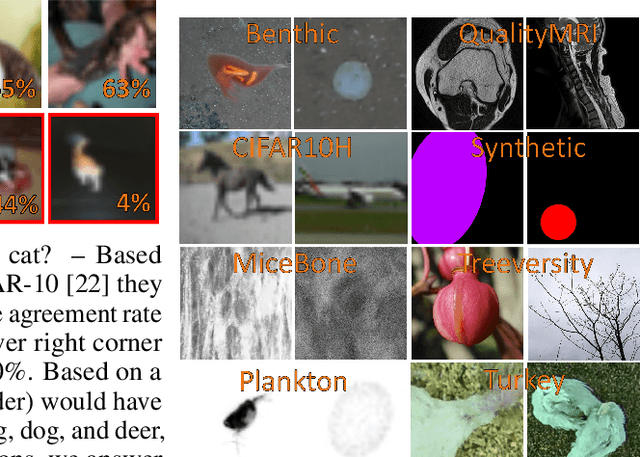
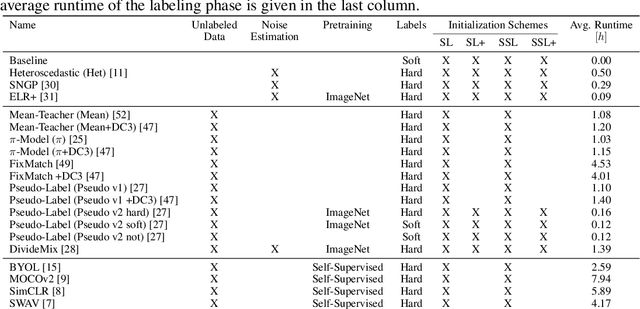
High-quality data is necessary for modern machine learning. However, the acquisition of such data is difficult due to noisy and ambiguous annotations of humans. The aggregation of such annotations to determine the label of an image leads to a lower data quality. We propose a data-centric image classification benchmark with nine real-world datasets and multiple annotations per image to investigate and quantify the impact of such data quality issues. We focus on a data-centric perspective by asking how we could improve the data quality. Across thousands of experiments, we show that multiple annotations allow a better approximation of the real underlying class distribution. We identify that hard labels can not capture the ambiguity of the data and this might lead to the common issue of overconfident models. Based on the presented datasets, benchmark baselines, and analysis, we create multiple research opportunities for the future.