 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs one annotation enough? A data-centric image classification benchmark for noisy and ambiguous label estimation
Jul 13, 2022
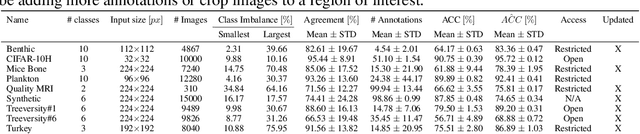
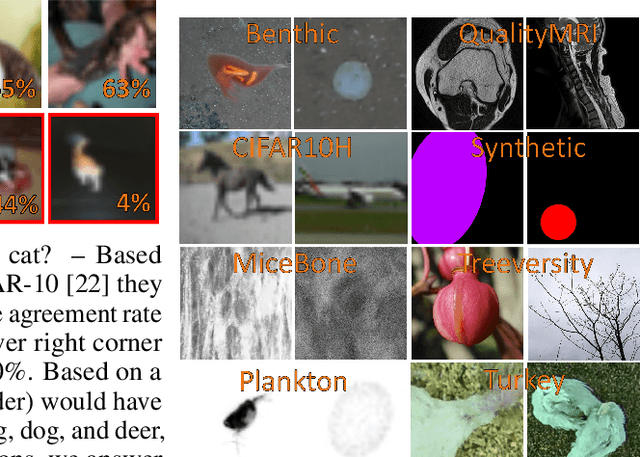
High-quality data is necessary for modern machine learning. However, the acquisition of such data is difficult due to noisy and ambiguous annotations of humans. The aggregation of such annotations to determine the label of an image leads to a lower data quality. We propose a data-centric image classification benchmark with nine real-world datasets and multiple annotations per image to investigate and quantify the impact of such data quality issues. We focus on a data-centric perspective by asking how we could improve the data quality. Across thousands of experiments, we show that multiple annotations allow a better approximation of the real underlying class distribution. We identify that hard labels can not capture the ambiguity of the data and this might lead to the common issue of overconfident models. Based on the presented datasets, benchmark baselines, and analysis, we create multiple research opportunities for the future.
S2C2 - An orthogonal method for Semi-Supervised Learning on fuzzy labels
Jun 30, 2021
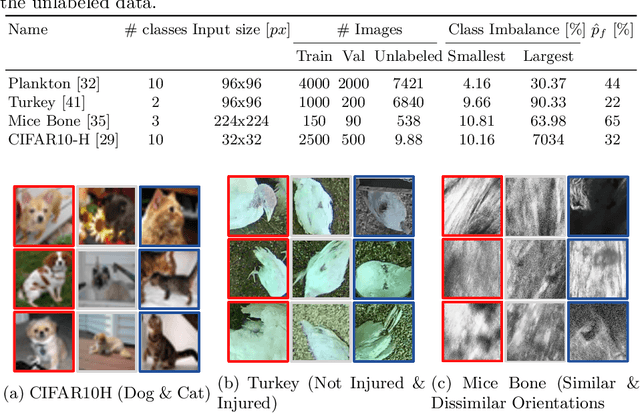
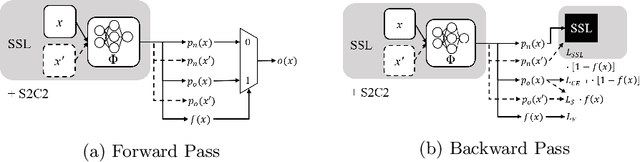

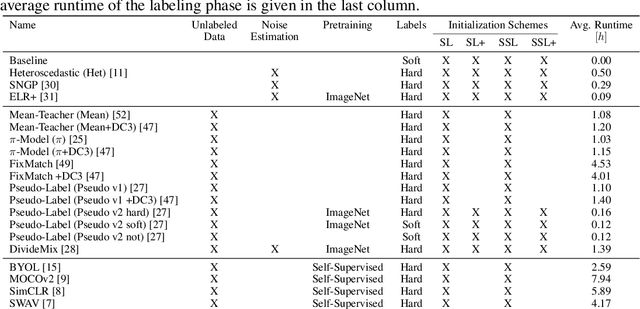
Semi-Supervised Learning (SSL) can decrease the amount of required labeled image data and thus the cost for deep learning. Most SSL methods only consider a clear distinction between classes but in many real-world datasets, this clear distinction is not given due to intra- or interobserver variability. This variability can lead to different annotations per image. Thus many images have ambiguous annotations and their label needs to be considered "fuzzy". This fuzziness of labels must be addressed as it will limit the performance of Semi-Supervised Learning (SSL) and deep learning in general. We propose Semi-Supervised Classification & Clustering (S2C2) which can extend many deep SSL algorithms. S2C2 can estimate the fuzziness of a label and applies SSL as a classification to certainly labeled data while creating distinct clusters for images with similar but fuzzy labels. We show that S2C2 results in median 7.4% better F1-score for classifications and 5.4% lower inner distance of clusters across multiple SSL algorithms and datasets while being more interpretable due to the fuzziness estimation of our method. Overall, a combination of Semi-Supervised Learning with our method S2C2 leads to better handling of the fuzziness of labels and thus real-world datasets.