 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Mind the Gaps: Implicit Neural Representations for Resolution-Agnostic Retinal OCT Analysis
Jan 05, 2026Routine clinical imaging of the retina using optical coherence tomography (OCT) is performed with large slice spacing, resulting in highly anisotropic images and a sparsely scanned retina. Most learning-based methods circumvent the problems arising from the anisotropy by using 2D approaches rather than performing volumetric analyses. These approaches inherently bear the risk of generating inconsistent results for neighboring B-scans. For example, 2D retinal layer segmentations can have irregular surfaces in 3D. Furthermore, the typically used convolutional neural networks are bound to the resolution of the training data, which prevents their usage for images acquired with a different imaging protocol. Implicit neural representations (INRs) have recently emerged as a tool to store voxelized data as a continuous representation. Using coordinates as input, INRs are resolution-agnostic, which allows them to be applied to anisotropic data. In this paper, we propose two frameworks that make use of this characteristic of INRs for dense 3D analyses of retinal OCT volumes. 1) We perform inter-B-scan interpolation by incorporating additional information from en-face modalities, that help retain relevant structures between B-scans. 2) We create a resolution-agnostic retinal atlas that enables general analysis without strict requirements for the data. Both methods leverage generalizable INRs, improving retinal shape representation through population-based training and allowing predictions for unseen cases. Our resolution-independent frameworks facilitate the analysis of OCT images with large B-scan distances, opening up possibilities for the volumetric evaluation of retinal structures and pathologies.
Label Smarter, Not Harder: CleverLabel for Faster Annotation of Ambiguous Image Classification with Higher Quality
May 22, 2023



High-quality data is crucial for the success of machine learning, but labeling large datasets is often a time-consuming and costly process. While semi-supervised learning can help mitigate the need for labeled data, label quality remains an open issue due to ambiguity and disagreement among annotators. Thus, we use proposal-guided annotations as one option which leads to more consistency between annotators. However, proposing a label increases the probability of the annotators deciding in favor of this specific label. This introduces a bias which we can simulate and remove. We propose a new method CleverLabel for Cost-effective LabEling using Validated proposal-guidEd annotations and Repaired LABELs. CleverLabel can reduce labeling costs by up to 30.0%, while achieving a relative improvement in Kullback-Leibler divergence of up to 29.8% compared to the previous state-of-the-art on a multi-domain real-world image classification benchmark. CleverLabel offers a novel solution to the challenge of efficiently labeling large datasets while also improving the label quality.
Fuzzy Overclustering: Semi-Supervised Classification of Fuzzy Labels with Overclustering and Inverse Cross-Entropy
Oct 13, 2021



Deep learning has been successfully applied to many classification problems including underwater challenges. However, a long-standing issue with deep learning is the need for large and consistently labeled datasets. Although current approaches in semi-supervised learning can decrease the required amount of annotated data by a factor of 10 or even more, this line of research still uses distinct classes. For underwater classification, and uncurated real-world datasets in general, clean class boundaries can often not be given due to a limited information content in the images and transitional stages of the depicted objects. This leads to different experts having different opinions and thus producing fuzzy labels which could also be considered ambiguous or divergent. We propose a novel framework for handling semi-supervised classifications of such fuzzy labels. It is based on the idea of overclustering to detect substructures in these fuzzy labels. We propose a novel loss to improve the overclustering capability of our framework and show the benefit of overclustering for fuzzy labels. We show that our framework is superior to previous state-of-the-art semi-supervised methods when applied to real-world plankton data with fuzzy labels. Moreover, we acquire 5 to 10\% more consistent predictions of substructures.
* Source code: https://github.com/Emprime/FuzzyOverclustering Datasets: https://doi.org/10.5281/zenodo.5550918. arXiv admin note: substantial text overlap with arXiv:2012.01768
Learning Stixel-based Instance Segmentation
Jul 07, 2021Stixels have been successfully applied to a wide range of vision tasks in autonomous driving, recently including instance segmentation. However, due to their sparse occurrence in the image, until now Stixels seldomly served as input for Deep Learning algorithms, restricting their utility for such approaches. In this work we present StixelPointNet, a novel method to perform fast instance segmentation directly on Stixels. By regarding the Stixel representation as unstructured data similar to point clouds, architectures like PointNet are able to learn features from Stixels. We use a bounding box detector to propose candidate instances, for which the relevant Stixels are extracted from the input image. On these Stixels, a PointNet models learns binary segmentations, which we then unify throughout the whole image in a final selection step. StixelPointNet achieves state-of-the-art performance on Stixel-level, is considerably faster than pixel-based segmentation methods, and shows that with our approach the Stixel domain can be introduced to many new 3D Deep Learning tasks.
S2C2 - An orthogonal method for Semi-Supervised Learning on fuzzy labels
Jun 30, 2021
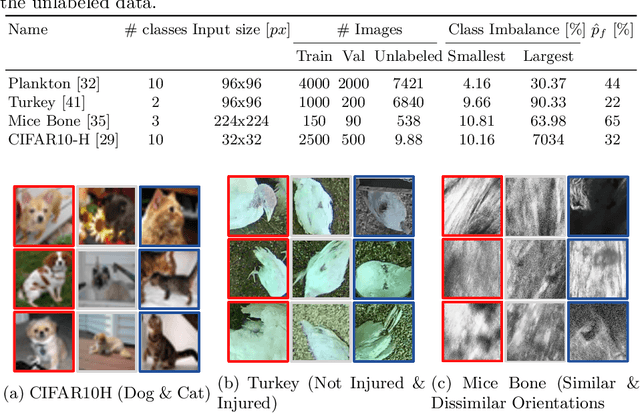
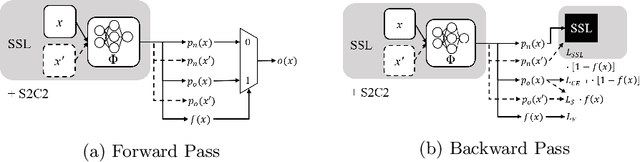

Semi-Supervised Learning (SSL) can decrease the amount of required labeled image data and thus the cost for deep learning. Most SSL methods only consider a clear distinction between classes but in many real-world datasets, this clear distinction is not given due to intra- or interobserver variability. This variability can lead to different annotations per image. Thus many images have ambiguous annotations and their label needs to be considered "fuzzy". This fuzziness of labels must be addressed as it will limit the performance of Semi-Supervised Learning (SSL) and deep learning in general. We propose Semi-Supervised Classification & Clustering (S2C2) which can extend many deep SSL algorithms. S2C2 can estimate the fuzziness of a label and applies SSL as a classification to certainly labeled data while creating distinct clusters for images with similar but fuzzy labels. We show that S2C2 results in median 7.4% better F1-score for classifications and 5.4% lower inner distance of clusters across multiple SSL algorithms and datasets while being more interpretable due to the fuzziness estimation of our method. Overall, a combination of Semi-Supervised Learning with our method S2C2 leads to better handling of the fuzziness of labels and thus real-world datasets.
Beyond Cats and Dogs: Semi-supervised Classification of fuzzy labels with overclustering
Dec 03, 2020



A long-standing issue with deep learning is the need for large and consistently labeled datasets. Although the current research in semi-supervised learning can decrease the required amount of annotated data by a factor of 10 or even more, this line of research still uses distinct classes like cats and dogs. However, in the real-world we often encounter problems where different experts have different opinions, thus producing fuzzy labels. We propose a novel framework for handling semi-supervised classifications of such fuzzy labels. Our framework is based on the idea of overclustering to detect substructures in these fuzzy labels. We propose a novel loss to improve the overclustering capability of our framework and show on the common image classification dataset STL-10 that it is faster and has better overclustering performance than previous work. On a real-world plankton dataset, we illustrate the benefit of overclustering for fuzzy labels and show that we beat previous state-of-the-art semisupervised methods. Moreover, we acquire 5 to 10% more consistent predictions of substructures.
A survey on Semi-, Self- and Unsupervised Techniques in Image Classification
Feb 20, 2020


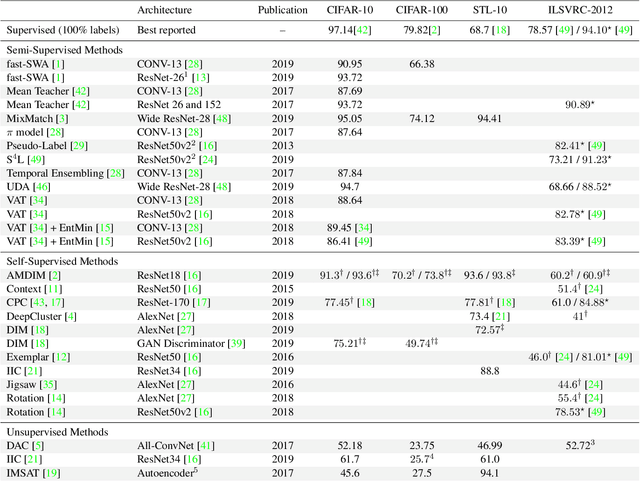
While deep learning strategies achieve outstanding results in computer vision tasks, one issue remains. The current strategies rely heavily on a huge amount of labeled data. In many real-world problems it is not feasible to create such an amount of labeled training data. Therefore, researchers try to incorporate unlabeled data into the training process to reach equal results with fewer labels. Due to a lot of concurrent research, it is difficult to keep track of recent developments. In this survey we provide an overview of often used techniques and methods in image classification with fewer labels. We compare 21 methods. In our analysis we identify three major trends. 1. State-of-the-art methods are scaleable to real world applications based on their accuracy. 2. The degree of supervision which is needed to achieve comparable results to the usage of all labels is decreasing. 3. All methods share common techniques while only few methods combine these techniques to achieve better performance. Based on all of these three trends we discover future research opportunities.