 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Overclustering: Semi-Supervised Classification of Fuzzy Labels with Overclustering and Inverse Cross-Entropy
Oct 13, 2021



Deep learning has been successfully applied to many classification problems including underwater challenges. However, a long-standing issue with deep learning is the need for large and consistently labeled datasets. Although current approaches in semi-supervised learning can decrease the required amount of annotated data by a factor of 10 or even more, this line of research still uses distinct classes. For underwater classification, and uncurated real-world datasets in general, clean class boundaries can often not be given due to a limited information content in the images and transitional stages of the depicted objects. This leads to different experts having different opinions and thus producing fuzzy labels which could also be considered ambiguous or divergent. We propose a novel framework for handling semi-supervised classifications of such fuzzy labels. It is based on the idea of overclustering to detect substructures in these fuzzy labels. We propose a novel loss to improve the overclustering capability of our framework and show the benefit of overclustering for fuzzy labels. We show that our framework is superior to previous state-of-the-art semi-supervised methods when applied to real-world plankton data with fuzzy labels. Moreover, we acquire 5 to 10\% more consistent predictions of substructures.
* Source code: https://github.com/Emprime/FuzzyOverclustering Datasets: https://doi.org/10.5281/zenodo.5550918. arXiv admin note: substantial text overlap with arXiv:2012.01768
Beyond Cats and Dogs: Semi-supervised Classification of fuzzy labels with overclustering
Dec 03, 2020



A long-standing issue with deep learning is the need for large and consistently labeled datasets. Although the current research in semi-supervised learning can decrease the required amount of annotated data by a factor of 10 or even more, this line of research still uses distinct classes like cats and dogs. However, in the real-world we often encounter problems where different experts have different opinions, thus producing fuzzy labels. We propose a novel framework for handling semi-supervised classifications of such fuzzy labels. Our framework is based on the idea of overclustering to detect substructures in these fuzzy labels. We propose a novel loss to improve the overclustering capability of our framework and show on the common image classification dataset STL-10 that it is faster and has better overclustering performance than previous work. On a real-world plankton dataset, we illustrate the benefit of overclustering for fuzzy labels and show that we beat previous state-of-the-art semisupervised methods. Moreover, we acquire 5 to 10% more consistent predictions of substructures.
Panoptic Instance Segmentation on Pigs
May 21, 2020
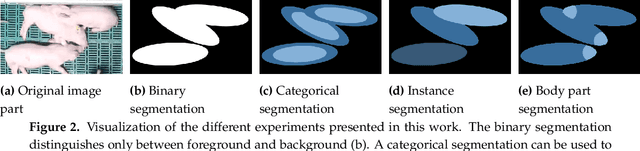


The behavioural research of pigs can be greatly simplified if automatic recognition systems are used. Especially systems based on computer vision have the advantage that they allow an evaluation without affecting the normal behaviour of the animals. In recent years, methods based on deep learning have been introduced and have shown pleasingly good results. Especially object and keypoint detectors have been used to detect the individual animals. Despite good results, bounding boxes and sparse keypoints do not trace the contours of the animals, resulting in a lot of information being lost. Therefore this work follows the relatively new definition of a panoptic segmentation and aims at the pixel accurate segmentation of the individual pigs. For this a framework of a neural network for semantic segmentation, different network heads and postprocessing methods is presented. With the resulting instance segmentation masks further information like the size or weight of the animals could be estimated. The method is tested on a specially created data set with 1000 hand-labeled images and achieves detection rates of around 95% (F1 Score) despite disturbances such as occlusions and dirty lenses.