 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNCOVER: Unknown Class Object Detection for Autonomous Vehicles in Real-time
Dec 05, 2024



Autonomous driving (AD) operates in open-world scenarios, where encountering unknown objects is inevitable. However, standard object detectors trained on a limited number of base classes tend to ignore any unknown objects, posing potential risks on the road. To address this, it is important to learn a generic rather than a class specific objectness from objects seen during training. We therefore introduce an occupancy prediction together with bounding box regression. It learns to score the objectness by calculating the ratio of the predicted area occupied by actual objects. To enhance its generalizability, we increase the object diversity by exploiting data from other domains via Mosaic and Mixup augmentation. The objects outside the AD training classes are classified as a newly added out-of-distribution (OOD) class. Our solution UNCOVER, for UNknown Class Object detection for autonomous VEhicles in Real-time, excels at achieving both real-time detection and high recall of unknown objects on challenging AD benchmarks. To further attain very low false positive rates, particularly for close objects, we introduce a post-hoc filtering step that utilizes geometric cues extracted from the depth map, typically available within the AD system.
Mind the Exit Pupil Gap: Revisiting the Intrinsics of a Standard Plenoptic Camera
Feb 20, 2024



Among the common applications of plenoptic cameras are depth reconstruction and post-shot refocusing. These require a calibration relating the camera-side light field to that of the scene. Numerous methods with this goal have been developed based on thin lens models for the plenoptic camera's main lens and microlenses. Our work addresses the often-overlooked role of the main lens exit pupil in these models and specifically in the decoding process of standard plenoptic camera (SPC) images. We formally deduce the connection between the refocusing distance and the resampling parameter for the decoded light field and provide an analysis of the errors that arise when the exit pupil is not considered. In addition, previous work is revisited with respect to the exit pupil's role and all theoretical results are validated through a ray-tracing-based simulation. With the public release of the evaluated SPC designs alongside our simulation and experimental data we aim to contribute to a more accurate and nuanced understanding of plenoptic camera optics.
Annotating Ambiguous Images: General Annotation Strategy for Image Classification with Real-World Biomedical Validation on Vertebral Fracture Diagnosis
Jun 21, 2023
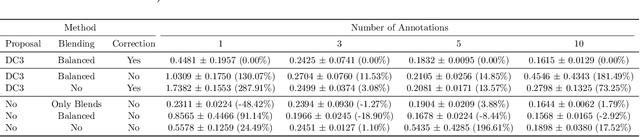
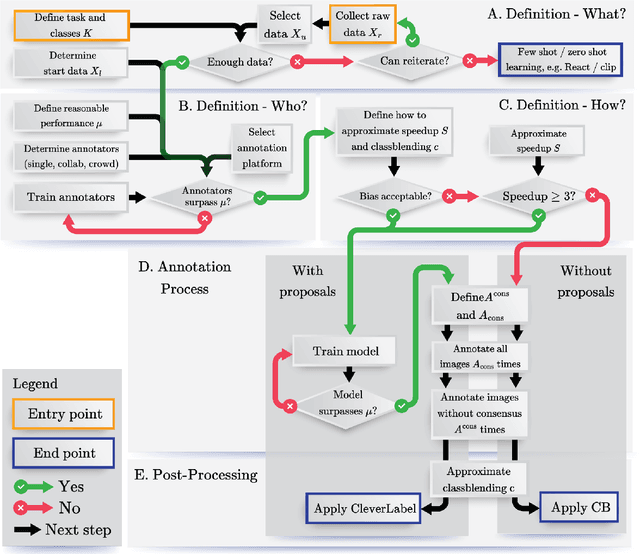

While numerous methods exist to solve classification problems within curated datasets, these solutions often fall short in biomedical applications due to the biased or ambiguous nature of the data. These difficulties are particularly evident when inferring height reduction from vertebral data, a key component of the clinically-recognized Genant score. Although strategies such as semi-supervised learning, proposal usage, and class blending may provide some resolution, a clear and superior solution remains elusive. This paper introduces a flowchart of general strategy to address these issues. We demonstrate the application of this strategy by constructing a vertebral fracture dataset with over 300,000 annotations. This work facilitates the transition of the classification problem into clinically meaningful scores and enriches our understanding of vertebral height reduction.
Label Smarter, Not Harder: CleverLabel for Faster Annotation of Ambiguous Image Classification with Higher Quality
May 22, 2023



High-quality data is crucial for the success of machine learning, but labeling large datasets is often a time-consuming and costly process. While semi-supervised learning can help mitigate the need for labeled data, label quality remains an open issue due to ambiguity and disagreement among annotators. Thus, we use proposal-guided annotations as one option which leads to more consistency between annotators. However, proposing a label increases the probability of the annotators deciding in favor of this specific label. This introduces a bias which we can simulate and remove. We propose a new method CleverLabel for Cost-effective LabEling using Validated proposal-guidEd annotations and Repaired LABELs. CleverLabel can reduce labeling costs by up to 30.0%, while achieving a relative improvement in Kullback-Leibler divergence of up to 29.8% compared to the previous state-of-the-art on a multi-domain real-world image classification benchmark. CleverLabel offers a novel solution to the challenge of efficiently labeling large datasets while also improving the label quality.
Automated Classification of Nanoparticles with Various Ultrastructures and Sizes
Jul 28, 2022

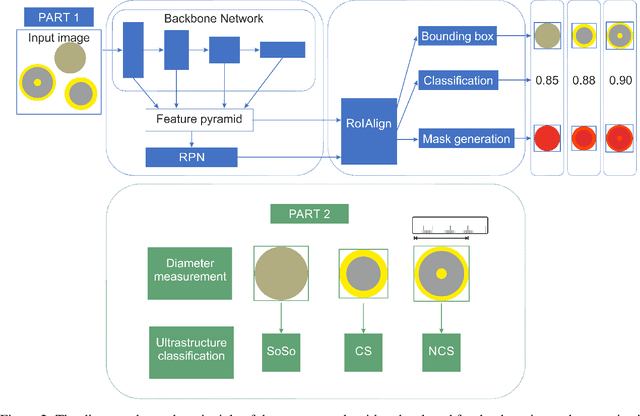
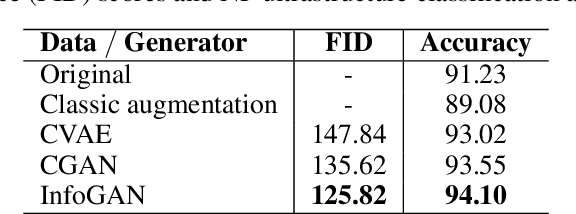
Accurately measuring the size, morphology, and structure of nanoparticles is very important, because they are strongly dependent on their properties for many applications. In this paper, we present a deep-learning based method for nanoparticle measurement and classification trained from a small data set of scanning transmission electron microscopy images. Our approach is comprised of two stages: localization, i.e., detection of nanoparticles, and classification, i.e., categorization of their ultrastructure. For each stage, we optimize the segmentation and classification by analysis of the different state-of-the-art neural networks. We show how the generation of synthetic images, either using image processing or using various image generation neural networks, can be used to improve the results in both stages. Finally, the application of the algorithm to bimetallic nanoparticles demonstrates the automated data collection of size distributions including classification of complex ultrastructures. The developed method can be easily transferred to other material systems and nanoparticle structures.
Opportunistic hip fracture risk prediction in Men from X-ray: Findings from the Osteoporosis in Men (MrOS) Study
Jul 22, 2022



Osteoporosis is a common disease that increases fracture risk. Hip fractures, especially in elderly people, lead to increased morbidity, decreased quality of life and increased mortality. Being a silent disease before fracture, osteoporosis often remains undiagnosed and untreated. Areal bone mineral density (aBMD) assessed by dual-energy X-ray absorptiometry (DXA) is the gold-standard method for osteoporosis diagnosis and hence also for future fracture prediction (prognostic). However, the required special equipment is not broadly available everywhere, in particular not to patients in developing countries. We propose a deep learning classification model (FORM) that can directly predict hip fracture risk from either plain radiographs (X-ray) or 2D projection images of computed tomography (CT) data. Our method is fully automated and therefore well suited for opportunistic screening settings, identifying high risk patients in a broader population without additional screening. FORM was trained and evaluated on X-rays and CT projections from the Osteoporosis in Men (MrOS) study. 3108 X-rays (89 incident hip fractures) or 2150 CTs (80 incident hip fractures) with a 80/20 split were used. We show that FORM can correctly predict the 10-year hip fracture risk with a validation AUC of 81.44 +- 3.11% / 81.04 +- 5.54% (mean +- STD) including additional information like age, BMI, fall history and health background across a 5-fold cross validation on the X-ray and CT cohort, respectively. Our approach significantly (p < 0.01) outperforms previous methods like Cox Proportional-Hazards Model and \frax with 70.19 +- 6.58 and 74.72 +- 7.21 respectively on the X-ray cohort. Our model outperform on both cohorts hip aBMD based predictions. We are confident that FORM can contribute on improving osteoporosis diagnosis at an early stage.
Beyond Hard Labels: Investigating data label distributions
Jul 13, 2022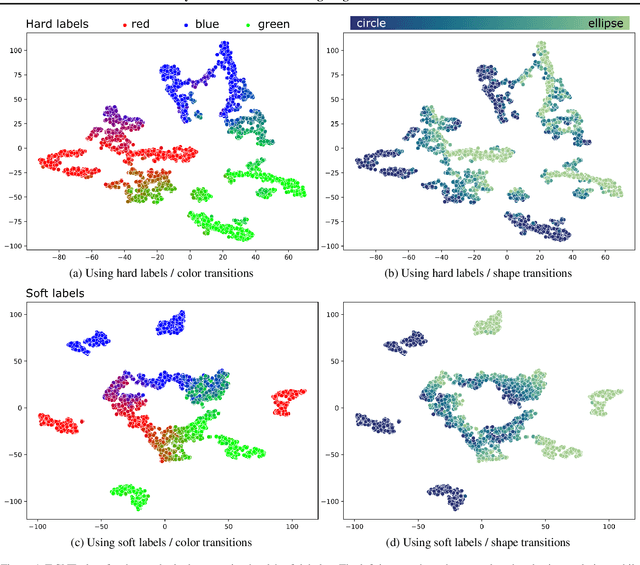

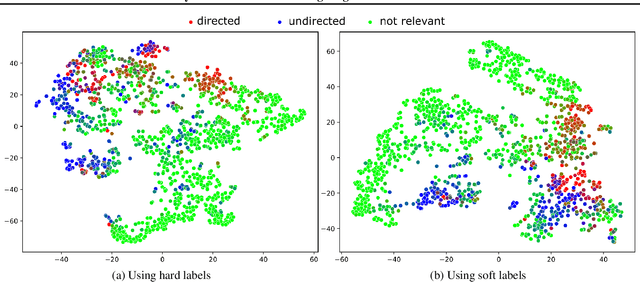
High-quality data is a key aspect of modern machine learning. However, labels generated by humans suffer from issues like label noise and class ambiguities. We raise the question of whether hard labels are sufficient to represent the underlying ground truth distribution in the presence of these inherent imprecision. Therefore, we compare the disparity of learning with hard and soft labels quantitatively and qualitatively for a synthetic and a real-world dataset. We show that the application of soft labels leads to improved performance and yields a more regular structure of the internal feature space.
Simulation of Plenoptic Cameras
Mar 09, 2022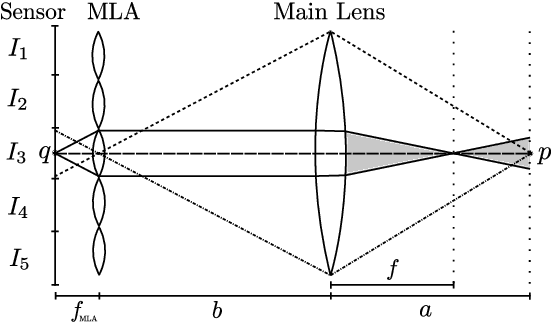
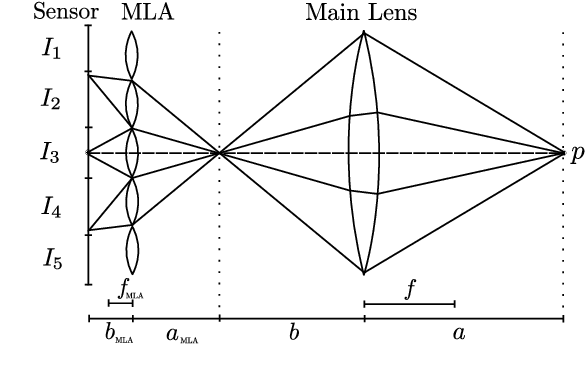


Plenoptic cameras enable the capturing of spatial as well as angular color information which can be used for various applications among which are image refocusing and depth calculations. However, these cameras are expensive and research in this area currently lacks data for ground truth comparisons. In this work we describe a flexible, easy-to-use Blender model for the different plenoptic camera types which is on the one hand able to provide the ground truth data for research and on the other hand allows an inexpensive assessment of the cameras usefulness for the desired applications. Furthermore we show that the rendering results exhibit the same image degradation effects as real cameras and make our simulation publicly available.
Creating Realistic Ground Truth Data for the Evaluation of Calibration Methods for Plenoptic and Conventional Cameras
Mar 09, 2022



Camera calibration methods usually consist of capturing images of known calibration patterns and using the detected correspondences to optimize the parameters of the assumed camera model. A meaningful evaluation of these methods relies on the availability of realistic synthetic data. In previous works concerned with conventional cameras the synthetic data was mainly created by rendering perfect images with a pinhole camera and subsequently adding distortions and aberrations to the renderings and correspondences according to the assumed camera model. This method can bias the evaluation since not every camera perfectly complies with an assumed model. Furthermore, in the field of plenoptic camera calibration there is no synthetic ground truth data available at all. We address these problems by proposing a method based on backward ray tracing to create realistic ground truth data that can be used for an unbiased evaluation of calibration methods for both types of cameras.
* 9 pages, 8 figures. Accepted at 3DV 2019
Ray Tracing-Guided Design of Plenoptic Cameras
Mar 09, 2022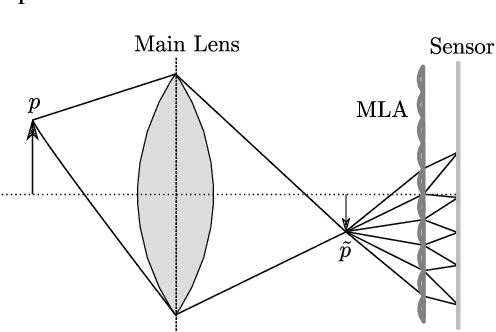


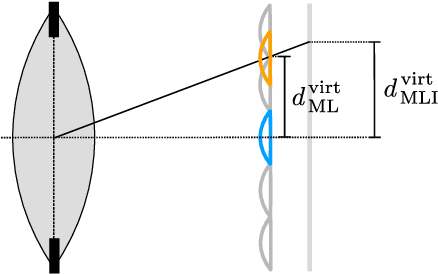
The design of a plenoptic camera requires the combination of two dissimilar optical systems, namely a main lens and an array of microlenses. And while the construction process of a conventional camera is mainly concerned with focusing the image onto a single plane, in the case of plenoptic cameras there can be additional requirements such as a predefined depth of field or a desired range of disparities in neighboring microlens images. Due to this complexity, the manual creation of multiple plenoptic camera setups is often a time-consuming task. In this work we assume a simulation framework as well as the main lens data given and present a method to calculate the remaining aperture, sensor and microlens array parameters under different sets of constraints. Our ray tracing-based approach is shown to result in models outperforming their pendants generated with the commonly used paraxial approximations in terms of image quality, while still meeting the desired constraints. Both the implementation and evaluation setup including 30 plenoptic camera designs are made publicly available.