 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of Microplastic Particles in Water using Polarized Light Scattering and Machine Learning Methods
Nov 10, 2025



Facing the critical need for continuous, large-scale microplastic monitoring, which is hindered by the limitations of gold-standard methods in aquatic environments, this paper introduces and validates a novel, reflection-based approach for the in-situ classification and identification of microplastics directly in water bodies, which is based on polarized light scattering. In this experiment, we classify colorless microplastic particles (50-300 $μ$m) by illuminating them with linearly polarized laser light and capturing their reflected signals using a polarization-sensitive camera. This reflection-based technique successfully circumvents the transmission-based interference issues that plague many conventional methods when applied in water. Using a deep convolutional neural network (CNN) for image-based classification, we successfully identified three common polymer types, high-density polyethylene, low-density polyethylene, and polypropylene, achieving a peak mean classification accuracy of 80% on the test dataset. A subsequent feature hierarchy analysis demonstrated that the CNN's decision-making process relies mainly on the microstructural integrity and internal texture (polarization patterns) of the particle rather than its macroshape. Critically, we found that the Angle of Linear Polarization (AOLP) signal is significantly more robust against contextual noise than the Degree of Linear Polarization (DOLP) signal. While the AOLP-based classification achieved superior overall performance, its strength lies in distinguishing between the two polyethylene plastics, showing a lower confusion rate between high-density and low-density polyethylene. Conversely, the DOLP signal demonstrated slightly worse overall classification results but excels at accurately identifying the polypropylene class, which it isolated with greater success than AOLP.
Is one annotation enough? A data-centric image classification benchmark for noisy and ambiguous label estimation
Jul 13, 2022
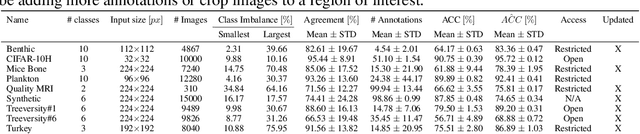
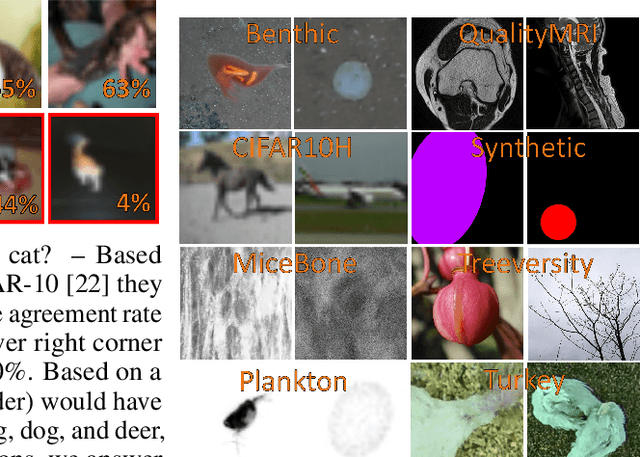
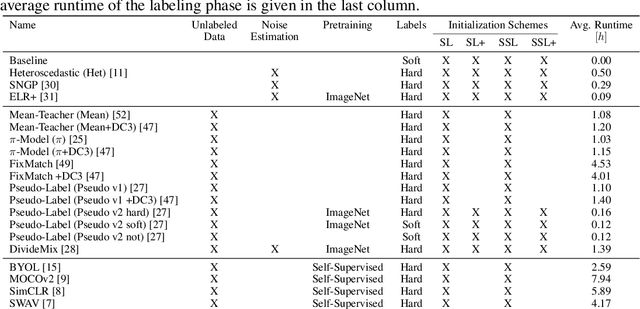
High-quality data is necessary for modern machine learning. However, the acquisition of such data is difficult due to noisy and ambiguous annotations of humans. The aggregation of such annotations to determine the label of an image leads to a lower data quality. We propose a data-centric image classification benchmark with nine real-world datasets and multiple annotations per image to investigate and quantify the impact of such data quality issues. We focus on a data-centric perspective by asking how we could improve the data quality. Across thousands of experiments, we show that multiple annotations allow a better approximation of the real underlying class distribution. We identify that hard labels can not capture the ambiguity of the data and this might lead to the common issue of overconfident models. Based on the presented datasets, benchmark baselines, and analysis, we create multiple research opportunities for the future.
Fuzzy Overclustering: Semi-Supervised Classification of Fuzzy Labels with Overclustering and Inverse Cross-Entropy
Oct 13, 2021



Deep learning has been successfully applied to many classification problems including underwater challenges. However, a long-standing issue with deep learning is the need for large and consistently labeled datasets. Although current approaches in semi-supervised learning can decrease the required amount of annotated data by a factor of 10 or even more, this line of research still uses distinct classes. For underwater classification, and uncurated real-world datasets in general, clean class boundaries can often not be given due to a limited information content in the images and transitional stages of the depicted objects. This leads to different experts having different opinions and thus producing fuzzy labels which could also be considered ambiguous or divergent. We propose a novel framework for handling semi-supervised classifications of such fuzzy labels. It is based on the idea of overclustering to detect substructures in these fuzzy labels. We propose a novel loss to improve the overclustering capability of our framework and show the benefit of overclustering for fuzzy labels. We show that our framework is superior to previous state-of-the-art semi-supervised methods when applied to real-world plankton data with fuzzy labels. Moreover, we acquire 5 to 10\% more consistent predictions of substructures.
* Source code: https://github.com/Emprime/FuzzyOverclustering Datasets: https://doi.org/10.5281/zenodo.5550918. arXiv admin note: substantial text overlap with arXiv:2012.01768
S2C2 - An orthogonal method for Semi-Supervised Learning on fuzzy labels
Jun 30, 2021
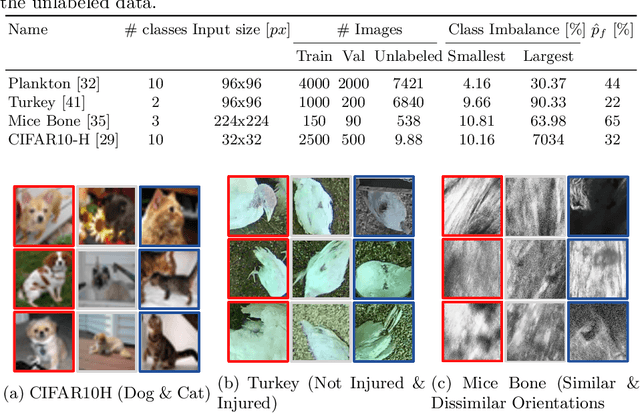
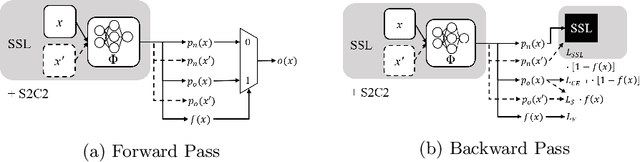

Semi-Supervised Learning (SSL) can decrease the amount of required labeled image data and thus the cost for deep learning. Most SSL methods only consider a clear distinction between classes but in many real-world datasets, this clear distinction is not given due to intra- or interobserver variability. This variability can lead to different annotations per image. Thus many images have ambiguous annotations and their label needs to be considered "fuzzy". This fuzziness of labels must be addressed as it will limit the performance of Semi-Supervised Learning (SSL) and deep learning in general. We propose Semi-Supervised Classification & Clustering (S2C2) which can extend many deep SSL algorithms. S2C2 can estimate the fuzziness of a label and applies SSL as a classification to certainly labeled data while creating distinct clusters for images with similar but fuzzy labels. We show that S2C2 results in median 7.4% better F1-score for classifications and 5.4% lower inner distance of clusters across multiple SSL algorithms and datasets while being more interpretable due to the fuzziness estimation of our method. Overall, a combination of Semi-Supervised Learning with our method S2C2 leads to better handling of the fuzziness of labels and thus real-world datasets.
Beyond Cats and Dogs: Semi-supervised Classification of fuzzy labels with overclustering
Dec 03, 2020



A long-standing issue with deep learning is the need for large and consistently labeled datasets. Although the current research in semi-supervised learning can decrease the required amount of annotated data by a factor of 10 or even more, this line of research still uses distinct classes like cats and dogs. However, in the real-world we often encounter problems where different experts have different opinions, thus producing fuzzy labels. We propose a novel framework for handling semi-supervised classifications of such fuzzy labels. Our framework is based on the idea of overclustering to detect substructures in these fuzzy labels. We propose a novel loss to improve the overclustering capability of our framework and show on the common image classification dataset STL-10 that it is faster and has better overclustering performance than previous work. On a real-world plankton dataset, we illustrate the benefit of overclustering for fuzzy labels and show that we beat previous state-of-the-art semisupervised methods. Moreover, we acquire 5 to 10% more consistent predictions of substructures.
MorphoCluster: Efficient Annotation of Plankton images by Clustering
May 04, 2020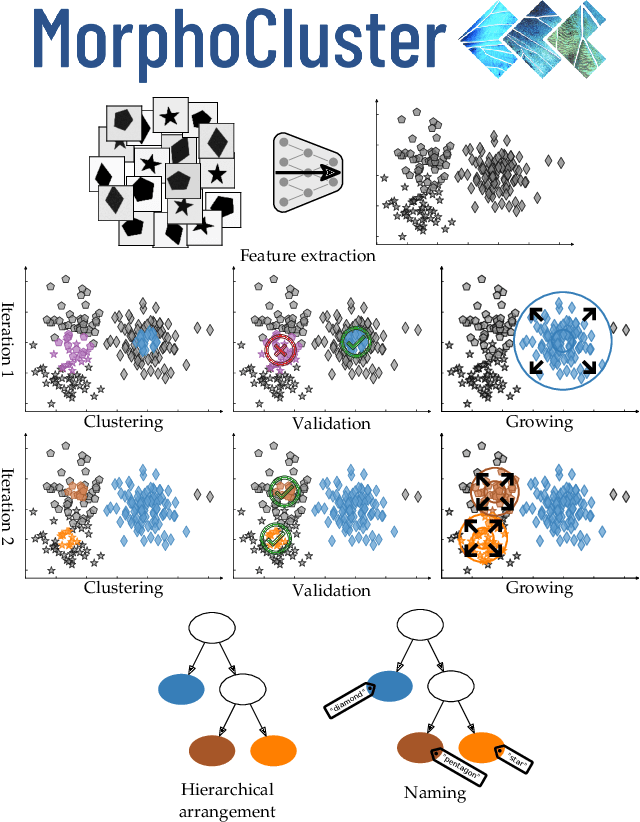
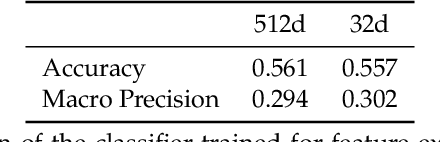
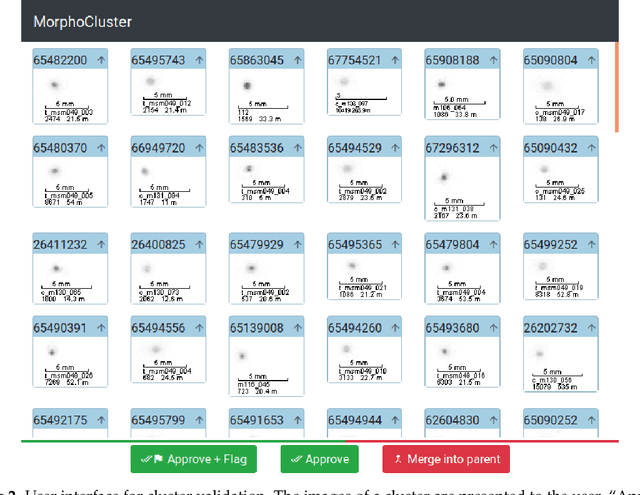
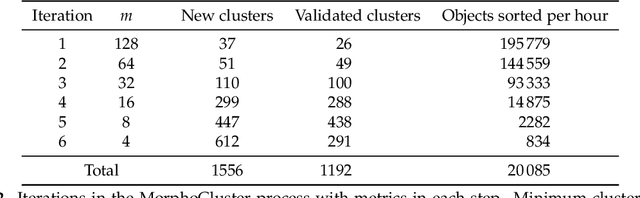
In this work, we present MorphoCluster, a software tool for data-driven, fast and accurate annotation of large image data sets. While already having surpassed the annotation rate of human experts, volume and complexity of marine data will continue to increase in the coming years. Still, this data requires interpretation. MorphoCluster augments the human ability to discover patterns and perform object classification in large amounts of data by embedding unsupervised clustering in an interactive process. By aggregating similar images into clusters, our novel approach to image annotation increases consistency, multiplies the throughput of an annotator and allows experts to adapt the granularity of their sorting scheme to the structure in the data. By sorting a set of 1.2M objects into 280 data-driven classes in 71 hours (16k objects per hour), with 90% of these classes having a precision of 0.889 or higher. This shows that MorphoCluster is at the same time fast, accurate and consistent, provides a fine-grained and data-driven classification and enables novelty detection. MorphoCluster is available as open-source software at https://github.com/morphocluster.