 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Optimization for Macro Placement
Jul 18, 2022
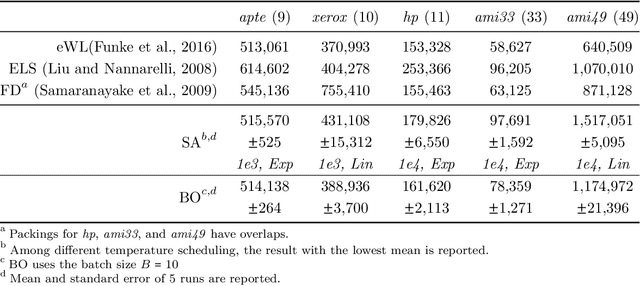
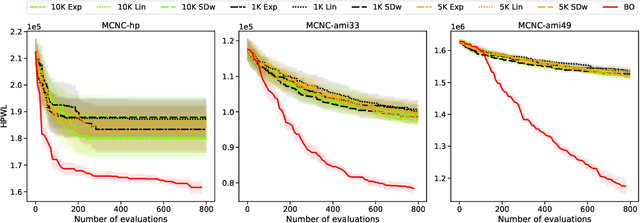

Macro placement is the problem of placing memory blocks on a chip canvas. It can be formulated as a combinatorial optimization problem over sequence pairs, a representation which describes the relative positions of macros. Solving this problem is particularly challenging since the objective function is expensive to evaluate. In this paper, we develop a novel approach to macro placement using Bayesian optimization (BO) over sequence pairs. BO is a machine learning technique that uses a probabilistic surrogate model and an acquisition function that balances exploration and exploitation to efficiently optimize a black-box objective function. BO is more sample-efficient than reinforcement learning and therefore can be used with more realistic objectives. Additionally, the ability to learn from data and adapt the algorithm to the objective function makes BO an appealing alternative to other black-box optimization methods such as simulated annealing, which relies on problem-dependent heuristics and parameter-tuning. We benchmark our algorithm on the fixed-outline macro placement problem with the half-perimeter wire length objective and demonstrate competitive performance.
Bias and Fairness on Multimodal Emotion Detection Algorithms
May 11, 2022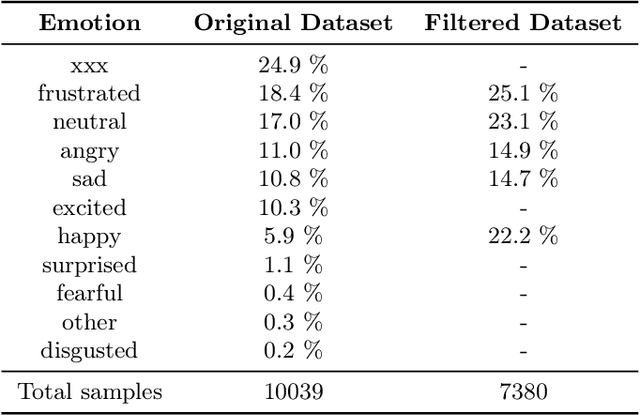
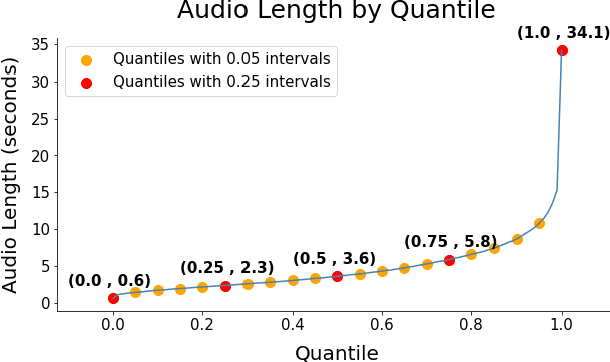
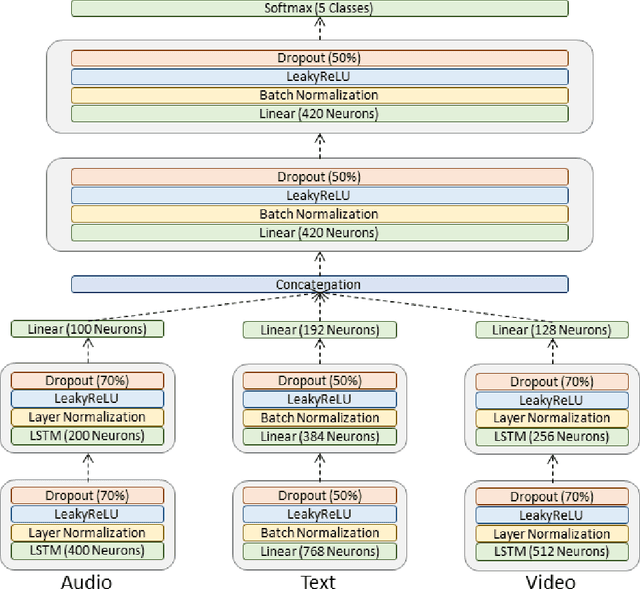
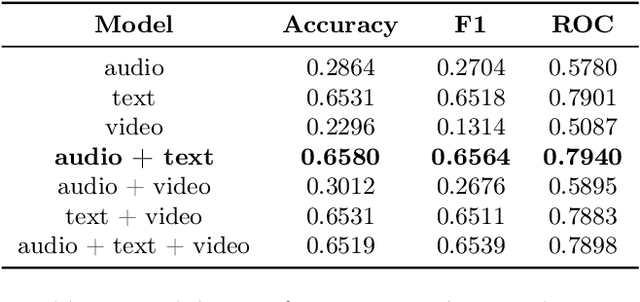
Numerous studies have shown that machine learning algorithms can latch onto protected attributes such as race and gender and generate predictions that systematically discriminate against one or more groups. To date the majority of bias and fairness research has been on unimodal models. In this work, we explore the biases that exist in emotion recognition systems in relationship to the modalities utilized, and study how multimodal approaches affect system bias and fairness. We consider audio, text, and video modalities, as well as all possible multimodal combinations of those, and find that text alone has the least bias, and accounts for the majority of the models' performances, raising doubts about the worthiness of multimodal emotion recognition systems when bias and fairness are desired alongside model performance.
Deep Learning for EEG Seizure Detection in Preterm Infants
May 28, 2021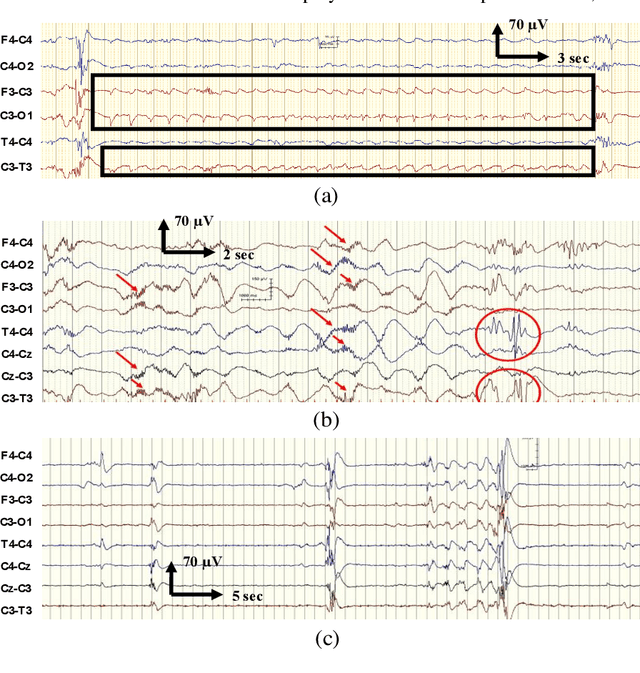

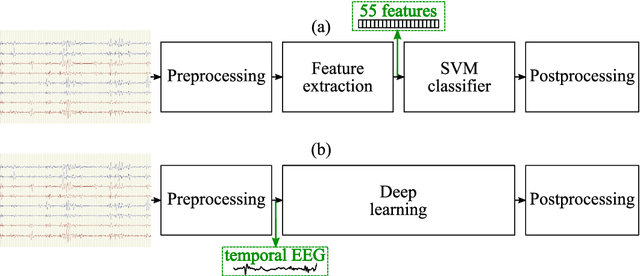
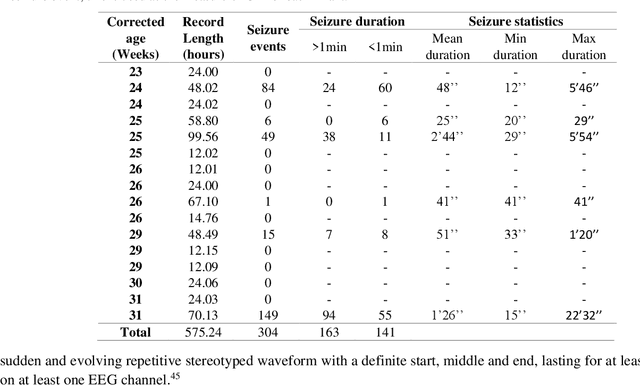
EEG is the gold standard for seizure detection in the newborn infant, but EEG interpretation in the preterm group is particularly challenging; trained experts are scarce and the task of interpreting EEG in real-time is arduous. Preterm infants are reported to have a higher incidence of seizures compared to term infants. Preterm EEG morphology differs from that of term infants, which implies that seizure detection algorithms trained on term EEG may not be appropriate. The task of developing preterm specific algorithms becomes extra-challenging given the limited amount of annotated preterm EEG data available. This paper explores novel deep learning (DL) architectures for the task of neonatal seizure detection in preterm infants. The study tests and compares several approaches to address the problem: training on data from full-term infants; training on data from preterm infants; training on age-specific preterm data and transfer learning. The system performance is assessed on a large database of continuous EEG recordings of 575h in duration. It is shown that the accuracy of a validated term-trained EEG seizure detection algorithm, based on a support vector machine classifier, when tested on preterm infants falls well short of the performance achieved for full-term infants. An AUC of 88.3% was obtained when tested on preterm EEG as compared to 96.6% obtained when tested on term EEG. When re-trained on preterm EEG, the performance marginally increases to 89.7%. An alternative DL approach shows a more stable trend when tested on the preterm cohort, starting with an AUC of 93.3% for the term-trained algorithm and reaching 95.0% by transfer learning from the term model using available preterm data.
RED-Attack: Resource Efficient Decision based Attack for Machine Learning
Jan 30, 2019

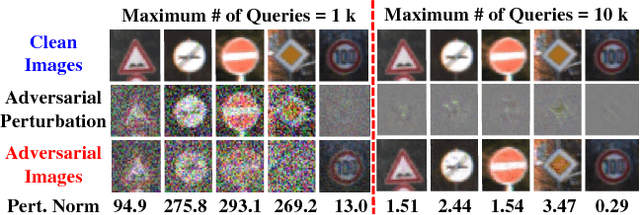
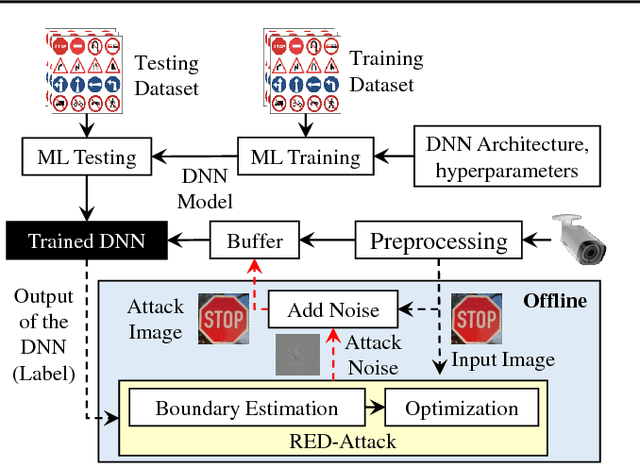
Due to data dependency and model leakage properties, Deep Neural Networks (DNNs) exhibit several security vulnerabilities. Several security attacks exploited them but most of them require the output probability vector. These attacks can be mitigated by concealing the output probability vector. To address this limitation, decision-based attacks have been proposed which can estimate the model but they require several thousand queries to generate a single untargeted attack image. However, in real-time attacks, resources and attack time are very crucial parameters. Therefore, in resource-constrained systems, e.g., autonomous vehicles where an untargeted attack can have a catastrophic effect, these attacks may not work efficiently. To address this limitation, we propose a resource efficient decision-based methodology which generates the imperceptible attack, i.e., the RED-Attack, for a given black-box model. The proposed methodology follows two main steps to generate the imperceptible attack, i.e., classification boundary estimation and adversarial noise optimization. Firstly, we propose a half-interval search-based algorithm for estimating a sample on the classification boundary using a target image and a randomly selected image from another class. Secondly, we propose an optimization algorithm which first, introduces a small perturbation in some randomly selected pixels of the estimated sample. Then to ensure imperceptibility, it optimizes the distance between the perturbed and target samples. For illustration, we evaluate it for CFAR-10 and German Traffic Sign Recognition (GTSR) using state-of-the-art networks.
SSCNets: A Selective Sobel Convolution-based Technique to Enhance the Robustness of Deep Neural Networks against Security Attacks
Nov 04, 2018

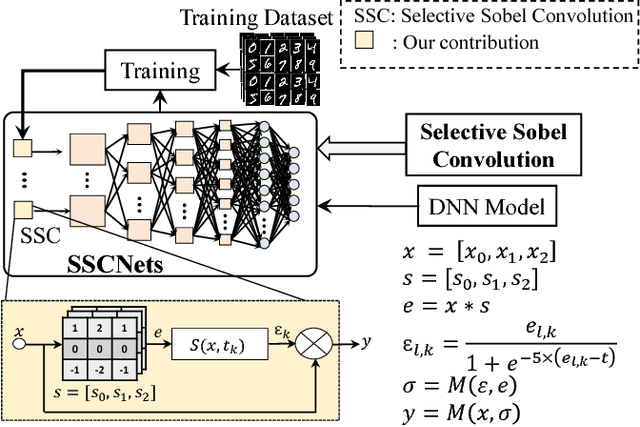
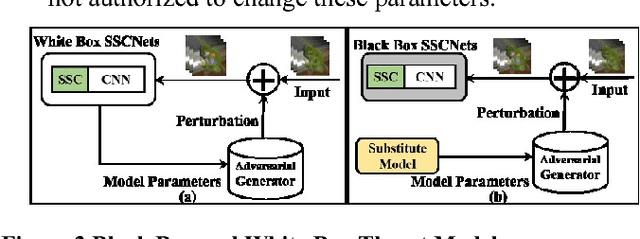
Recent studies have shown that slight perturbations in the input data can significantly affect the robustness of Deep Neural Networks (DNNs), leading to misclassification and confidence reduction. In this paper, we introduce a novel technique based on the Selective Sobel Convolution (SSC) operation in the training loop, that increases the robustness of a given DNN by allowing it to learn important edges in the input in a controlled fashion. This is achieved by introducing a trainable parameter, which acts as a threshold for eliminating the weaker edges. We validate our technique against the attacks of Cleverhans library on Convolutional DNNs against adversarial attacks. Our experimental results on the MNIST and CIFAR10 datasets illustrate that this controlled learning considerably increases the accuracy of the DNNs by 1.53% even when subjected to adversarial attacks.
QuSecNets: Quantization-based Defense Mechanism for Securing Deep Neural Network against Adversarial Attacks
Nov 04, 2018

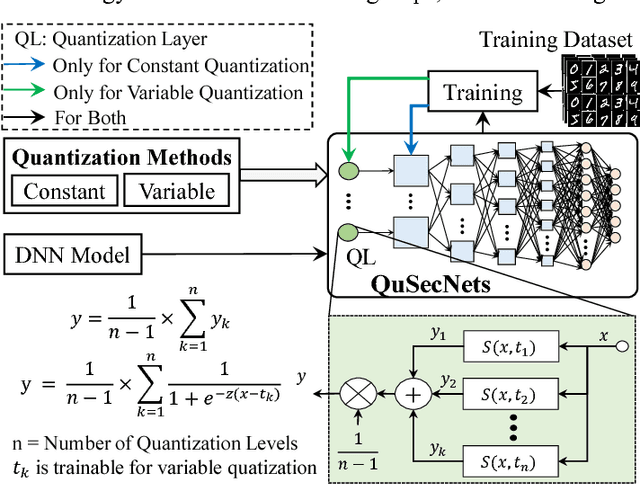

Deep Neural Networks (DNNs) have recently been shown vulnerable to adversarial attacks in which the input examples are perturbed to fool these DNNs towards confidence reduction and (targeted or random) misclassification. In this paper, we demonstrate that how an efficient quantization technique can be leveraged to increase the robustness of a given DNN against adversarial attacks. We present two quantization-based defense mechanisms, namely Constant Quantization (CQ) and Variable Quantization (VQ), applied at the input to increase the robustness of DNNs. In CQ, the intensity of the input pixel is quantized according to the number of quantization levels. While in VQ, the quantization levels are recursively updated during the training phase, thereby providing a stronger defense mechanism. We apply our techniques on the Convolutional Neural Networks (CNNs, a particular type of DNN which is heavily used in vision-based applications) against adversarial attacks from the open-source Cleverhans library. Our experimental results show 1%-5% increase in the adversarial accuracy for MNIST and 0%-2.4% increase in the adversarial accuracy for CIFAR10.