 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias and Fairness on Multimodal Emotion Detection Algorithms
Paper and Code
May 11, 2022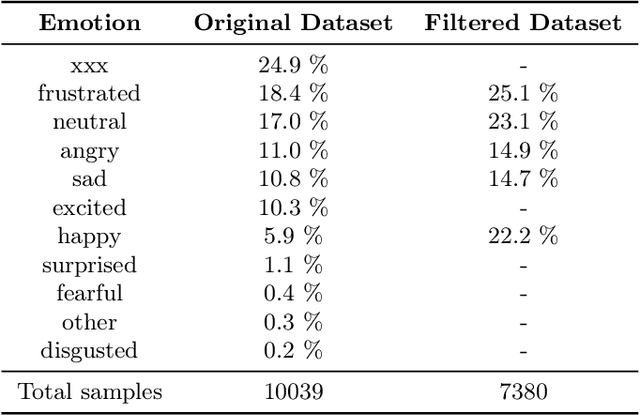
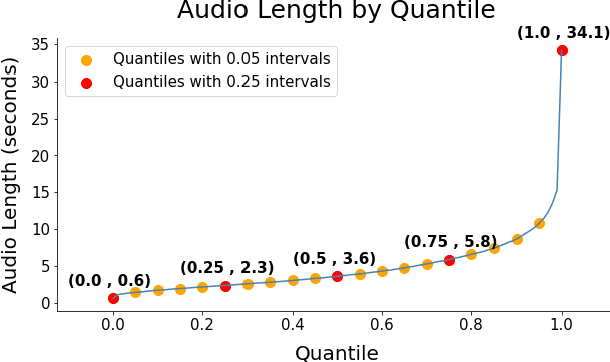
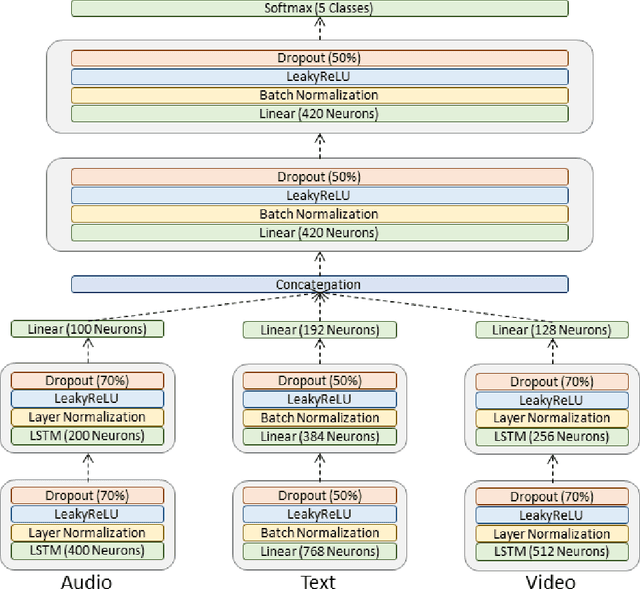
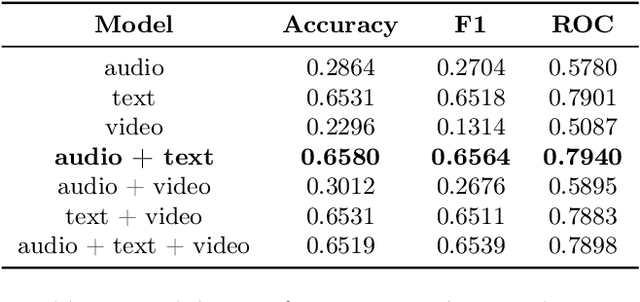
Numerous studies have shown that machine learning algorithms can latch onto protected attributes such as race and gender and generate predictions that systematically discriminate against one or more groups. To date the majority of bias and fairness research has been on unimodal models. In this work, we explore the biases that exist in emotion recognition systems in relationship to the modalities utilized, and study how multimodal approaches affect system bias and fairness. We consider audio, text, and video modalities, as well as all possible multimodal combinations of those, and find that text alone has the least bias, and accounts for the majority of the models' performances, raising doubts about the worthiness of multimodal emotion recognition systems when bias and fairness are desired alongside model performance.