 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Concave-Utility Reinforcement Learning is Inverse Game Theory
Paper and Code
May 29, 2024
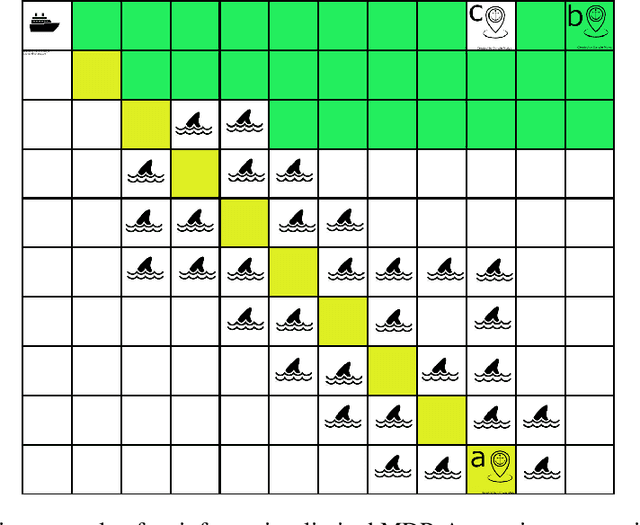
We consider inverse reinforcement learning problems with concave utilities. Concave Utility Reinforcement Learning (CURL) is a generalisation of the standard RL objective, which employs a concave function of the state occupancy measure, rather than a linear function. CURL has garnered recent attention for its ability to represent instances of many important applications including the standard RL such as imitation learning, pure exploration, constrained MDPs, offline RL, human-regularized RL, and others. Inverse reinforcement learning is a powerful paradigm that focuses on recovering an unknown reward function that can rationalize the observed behaviour of an agent. There has been recent theoretical advances in inverse RL where the problem is formulated as identifying the set of feasible reward functions. However, inverse RL for CURL problems has not been considered previously. In this paper we show that most of the standard IRL results do not apply to CURL in general, since CURL invalidates the classical Bellman equations. This calls for a new theoretical framework for the inverse CURL problem. Using a recent equivalence result between CURL and Mean-field Games, we propose a new definition for the feasible rewards for I-CURL by proving that this problem is equivalent to an inverse game theory problem in a subclass of mean-field games. We present initial query and sample complexity results for the I-CURL problem under assumptions such as Lipschitz-continuity. Finally, we outline future directions and applications in human--AI collaboration enabled by our results.