 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reasoning on the Edge
Mar 17, 2026Large language models (LLMs) with chain-of-thought reasoning achieve state-of-the-art performance across complex problem-solving tasks, but their verbose reasoning traces and large context requirements make them impractical for edge deployment. These challenges include high token generation costs, large KV-cache footprints, and inefficiencies when distilling reasoning capabilities into smaller models for mobile devices. Existing approaches often rely on distilling reasoning traces from larger models into smaller models, which are verbose and stylistically redundant, undesirable for on-device inference. In this work, we propose a lightweight approach to enable reasoning in small LLMs using LoRA adapters combined with supervised fine-tuning. We further introduce budget forcing via reinforcement learning on these adapters, significantly reducing response length with minimal accuracy loss. To address memory-bound decoding, we exploit parallel test-time scaling, improving accuracy at minor latency increase. Finally, we present a dynamic adapter-switching mechanism that activates reasoning only when needed and a KV-cache sharing strategy during prompt encoding, reducing time-to-first-token for on-device inference. Experiments on Qwen2.5-7B demonstrate that our method achieves efficient, accurate reasoning under strict resource constraints, making LLM reasoning practical for mobile scenarios. Videos demonstrating our solution running on mobile devices are available on our project page.
$\mathrm{E}(n)$ Equivariant Message Passing Simplicial Networks
May 11, 2023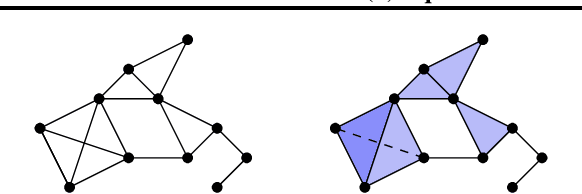
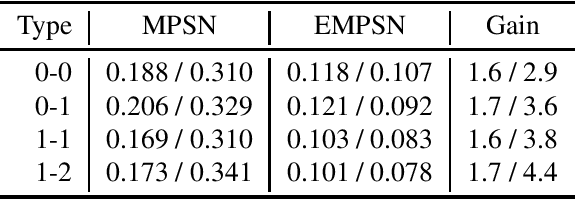
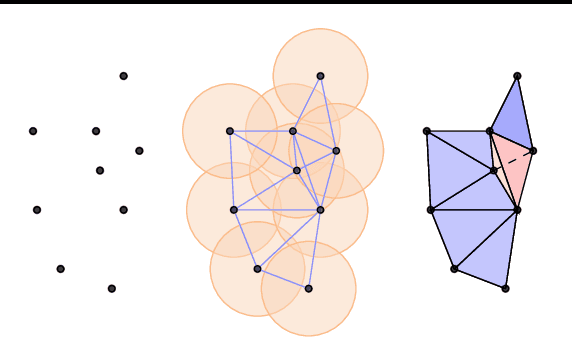
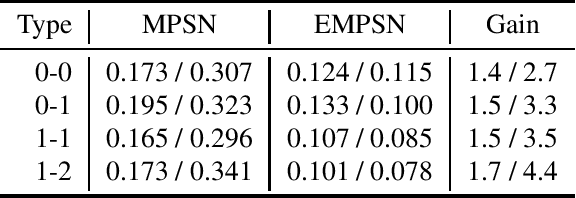
This paper presents $\mathrm{E}(n)$ Equivariant Message Passing Simplicial Networks (EMPSNs), a novel approach to learning on geometric graphs and point clouds that is equivariant to rotations, translations, and reflections. EMPSNs can learn high-dimensional simplex features in graphs (e.g. triangles), and use the increase of geometric information of higher-dimensional simplices in an $\mathrm{E}(n)$ equivariant fashion. EMPSNs simultaneously generalize $\mathrm{E}(n)$ Equivariant Graph Neural Networks to a topologically more elaborate counterpart and provide an approach for including geometric information in Message Passing Simplicial Networks. The results indicate that EMPSNs can leverage the benefits of both approaches, leading to a general increase in performance when compared to either method. Furthermore, the results suggest that incorporating geometric information serves as an effective measure against over-smoothing in message passing networks, especially when operating on high-dimensional simplicial structures. Last, we show that EMPSNs are on par with state-of-the-art approaches for learning on geometric graphs.
Geometric and Physical Quantities improve E(3) Equivariant Message Passing
Oct 06, 2021



Including covariant information, such as position, force, velocity or spin is important in many tasks in computational physics and chemistry. We introduce Steerable E(3) Equivariant Graph Neural Networks (SEGNNs) that generalise equivariant graph networks, such that node and edge attributes are not restricted to invariant scalars, but can contain covariant information, such as vectors or tensors. This model, composed of steerable MLPs, is able to incorporate geometric and physical information in both the message and update functions. Through the definition of steerable node attributes, the MLPs provide a new class of activation functions for general use with steerable feature fields. We discuss ours and related work through the lens of equivariant non-linear convolutions, which further allows us to pin-point the successful components of SEGNNs: non-linear message aggregation improves upon classic linear (steerable) point convolutions; steerable messages improve upon recent equivariant graph networks that send invariant messages. We demonstrate the effectiveness of our method on several tasks in computational physics and chemistry and provide extensive ablation studies.
Latent Transformations for Discrete-Data Normalising Flows
Jun 11, 2020

Normalising flows (NFs) for discrete data are challenging because parameterising bijective transformations of discrete variables requires predicting discrete/integer parameters. Having a neural network architecture predict discrete parameters takes a non-differentiable activation function (eg, the step function) which precludes gradient-based learning. To circumvent this non-differentiability, previous work has employed biased proxy gradients, such as the straight-through estimator. We present an unbiased alternative where rather than deterministically parameterising one transformation, we predict a distribution over latent transformations. With stochastic transformations, the marginal likelihood of the data is differentiable and gradient-based learning is possible via score function estimation. To test the viability of discrete-data NFs we investigate performance on binary MNIST. We observe great challenges with both deterministic proxy gradients and unbiased score function estimation. Whereas the former often fails to learn even a shallow transformation, the variance of the latter could not be sufficiently controlled to admit deeper NFs.