 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Mental Health Diagnostic Assessments: Exploring The Potential of Large Language Models for Assisting with Mental Health Diagnostic Assessments -- The Depression and Anxiety Case
Jan 02, 2025



Large language models (LLMs) are increasingly attracting the attention of healthcare professionals for their potential to assist in diagnostic assessments, which could alleviate the strain on the healthcare system caused by a high patient load and a shortage of providers. For LLMs to be effective in supporting diagnostic assessments, it is essential that they closely replicate the standard diagnostic procedures used by clinicians. In this paper, we specifically examine the diagnostic assessment processes described in the Patient Health Questionnaire-9 (PHQ-9) for major depressive disorder (MDD) and the Generalized Anxiety Disorder-7 (GAD-7) questionnaire for generalized anxiety disorder (GAD). We investigate various prompting and fine-tuning techniques to guide both proprietary and open-source LLMs in adhering to these processes, and we evaluate the agreement between LLM-generated diagnostic outcomes and expert-validated ground truth. For fine-tuning, we utilize the Mentalllama and Llama models, while for prompting, we experiment with proprietary models like GPT-3.5 and GPT-4o, as well as open-source models such as llama-3.1-8b and mixtral-8x7b.
RDR: the Recap, Deliberate, and Respond Method for Enhanced Language Understanding
Dec 15, 2023


Natural language understanding (NLU) using neural network pipelines often requires additional context that is not solely present in the input data. Through Prior research, it has been evident that NLU benchmarks are susceptible to manipulation by neural models, wherein these models exploit statistical artifacts within the encoded external knowledge to artificially inflate performance metrics for downstream tasks. Our proposed approach, known as the Recap, Deliberate, and Respond (RDR) paradigm, addresses this issue by incorporating three distinct objectives within the neural network pipeline. Firstly, the Recap objective involves paraphrasing the input text using a paraphrasing model in order to summarize and encapsulate its essence. Secondly, the Deliberation objective entails encoding external graph information related to entities mentioned in the input text, utilizing a graph embedding model. Finally, the Respond objective employs a classification head model that utilizes representations from the Recap and Deliberation modules to generate the final prediction. By cascading these three models and minimizing a combined loss, we mitigate the potential for gaming the benchmark and establish a robust method for capturing the underlying semantic patterns, thus enabling accurate predictions. To evaluate the effectiveness of the RDR method, we conduct tests on multiple GLUE benchmark tasks. Our results demonstrate improved performance compared to competitive baselines, with an enhancement of up to 2\% on standard metrics. Furthermore, we analyze the observed evidence for semantic understanding exhibited by RDR models, emphasizing their ability to avoid gaming the benchmark and instead accurately capture the true underlying semantic patterns.
IERL: Interpretable Ensemble Representation Learning -- Combining CrowdSourced Knowledge and Distributed Semantic Representations
Jun 24, 2023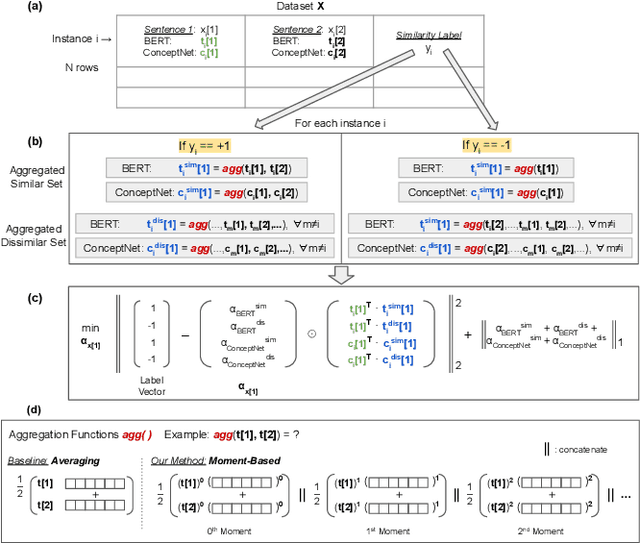
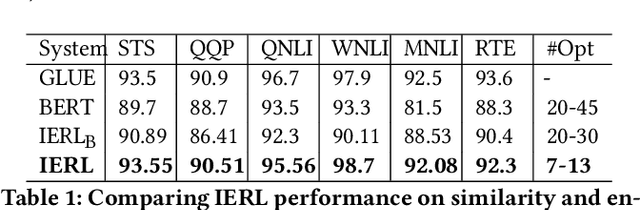
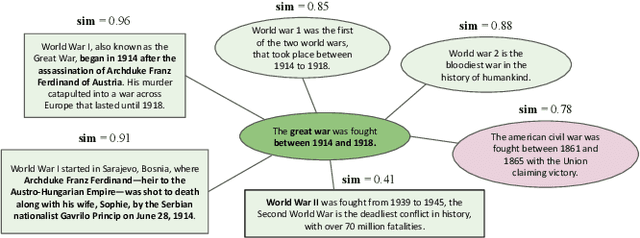
Large Language Models (LLMs) encode meanings of words in the form of distributed semantics. Distributed semantics capture common statistical patterns among language tokens (words, phrases, and sentences) from large amounts of data. LLMs perform exceedingly well across General Language Understanding Evaluation (GLUE) tasks designed to test a model's understanding of the meanings of the input tokens. However, recent studies have shown that LLMs tend to generate unintended, inconsistent, or wrong texts as outputs when processing inputs that were seen rarely during training, or inputs that are associated with diverse contexts (e.g., well-known hallucination phenomenon in language generation tasks). Crowdsourced and expert-curated knowledge graphs such as ConceptNet are designed to capture the meaning of words from a compact set of well-defined contexts. Thus LLMs may benefit from leveraging such knowledge contexts to reduce inconsistencies in outputs. We propose a novel ensemble learning method, Interpretable Ensemble Representation Learning (IERL), that systematically combines LLM and crowdsourced knowledge representations of input tokens. IERL has the distinct advantage of being interpretable by design (when was the LLM context used vs. when was the knowledge context used?) over state-of-the-art (SOTA) methods, allowing scrutiny of the inputs in conjunction with the parameters of the model, facilitating the analysis of models' inconsistent or irrelevant outputs. Although IERL is agnostic to the choice of LLM and crowdsourced knowledge, we demonstrate our approach using BERT and ConceptNet. We report improved or competitive results with IERL across GLUE tasks over current SOTA methods and significantly enhanced model interpretability.
Knowledge-Infused Self Attention Transformers
Jun 23, 2023


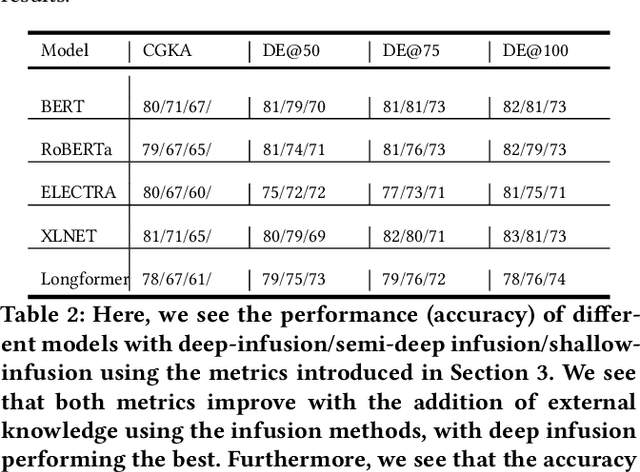
Transformer-based language models have achieved impressive success in various natural language processing tasks due to their ability to capture complex dependencies and contextual information using self-attention mechanisms. However, they are not without limitations. These limitations include hallucinations, where they produce incorrect outputs with high confidence, and alignment issues, where they generate unhelpful and unsafe outputs for human users. These limitations stem from the absence of implicit and missing context in the data alone. To address this, researchers have explored augmenting these models with external knowledge from knowledge graphs to provide the necessary additional context. However, the ad-hoc nature of existing methods makes it difficult to properly analyze the effects of knowledge infusion on the many moving parts or components of a transformer. This paper introduces a systematic method for infusing knowledge into different components of a transformer-based model. A modular framework is proposed to identify specific components within the transformer architecture, such as the self-attention mechanism, encoder layers, or the input embedding layer, where knowledge infusion can be applied. Additionally, extensive experiments are conducted on the General Language Understanding Evaluation (GLUE) benchmark tasks, and the findings are reported. This systematic approach aims to facilitate more principled approaches to incorporating knowledge into language model architectures.
Process Knowledge-infused Learning for Clinician-friendly Explanations
Jun 16, 2023


Language models have the potential to assess mental health using social media data. By analyzing online posts and conversations, these models can detect patterns indicating mental health conditions like depression, anxiety, or suicidal thoughts. They examine keywords, language markers, and sentiment to gain insights into an individual's mental well-being. This information is crucial for early detection, intervention, and support, improving mental health care and prevention strategies. However, using language models for mental health assessments from social media has two limitations: (1) They do not compare posts against clinicians' diagnostic processes, and (2) It's challenging to explain language model outputs using concepts that the clinician can understand, i.e., clinician-friendly explanations. In this study, we introduce Process Knowledge-infused Learning (PK-iL), a new learning paradigm that layers clinical process knowledge structures on language model outputs, enabling clinician-friendly explanations of the underlying language model predictions. We rigorously test our methods on existing benchmark datasets, augmented with such clinical process knowledge, and release a new dataset for assessing suicidality. PK-iL performs competitively, achieving a 70% agreement with users, while other XAI methods only achieve 47% agreement (average inter-rater agreement of 0.72). Our evaluations demonstrate that PK-iL effectively explains model predictions to clinicians.
Cook-Gen: Robust Generative Modeling of Cooking Actions from Recipes
Jun 01, 2023



As people become more aware of their food choices, food computation models have become increasingly popular in assisting people in maintaining healthy eating habits. For example, food recommendation systems analyze recipe instructions to assess nutritional contents and provide recipe recommendations. The recent and remarkable successes of generative AI methods, such as auto-regressive large language models, can lead to robust methods for a more comprehensive understanding of recipes for healthy food recommendations beyond surface-level nutrition content assessments. In this study, we explore the use of generative AI methods to extend current food computation models, primarily involving the analysis of nutrition and ingredients, to also incorporate cooking actions (e.g., add salt, fry the meat, boil the vegetables, etc.). Cooking actions are notoriously hard to model using statistical learning methods due to irregular data patterns - significantly varying natural language descriptions for the same action (e.g., marinate the meat vs. marinate the meat and leave overnight) and infrequently occurring patterns (e.g., add salt occurs far more frequently than marinating the meat). The prototypical approach to handling irregular data patterns is to increase the volume of data that the model ingests by orders of magnitude. Unfortunately, in the cooking domain, these problems are further compounded with larger data volumes presenting a unique challenge that is not easily handled by simply scaling up. In this work, we propose novel aggregation-based generative AI methods, Cook-Gen, that reliably generate cooking actions from recipes, despite difficulties with irregular data patterns, while also outperforming Large Language Models and other strong baselines.
Knowledge Graph Guided Semantic Evaluation of Language Models For User Trust
May 08, 2023A fundamental question in natural language processing is - what kind of language structure and semantics is the language model capturing? Graph formats such as knowledge graphs are easy to evaluate as they explicitly express language semantics and structure. This study evaluates the semantics encoded in the self-attention transformers by leveraging explicit knowledge graph structures. We propose novel metrics to measure the reconstruction error when providing graph path sequences from a knowledge graph and trying to reproduce/reconstruct the same from the outputs of the self-attention transformer models. The opacity of language models has an immense bearing on societal issues of trust and explainable decision outcomes. Our findings suggest that language models are models of stochastic control processes for plausible language pattern generation. However, they do not ascribe object and concept-level meaning and semantics to the learned stochastic patterns such as those described in knowledge graphs. Furthermore, to enable robust evaluation of concept understanding by language models, we construct and make public an augmented language understanding benchmark built on the General Language Understanding Evaluation (GLUE) benchmark. This has significant application-level user trust implications as stochastic patterns without a strong sense of meaning cannot be trusted in high-stakes applications.
KSAT: Knowledge-infused Self Attention Transformer -- Integrating Multiple Domain-Specific Contexts
Oct 09, 2022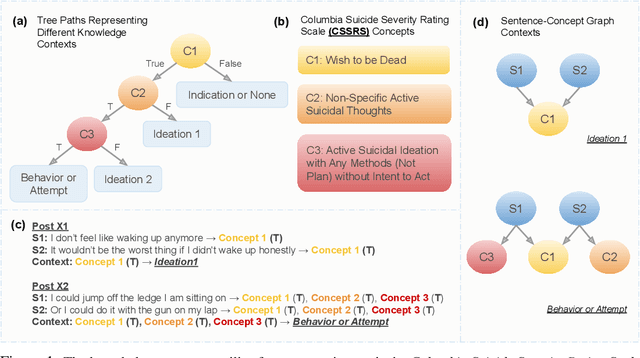

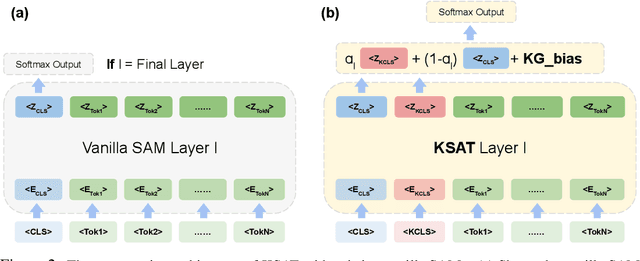
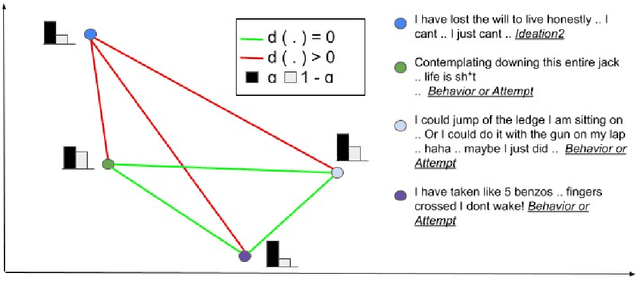
Domain-specific language understanding requires integrating multiple pieces of relevant contextual information. For example, we see both suicide and depression-related behavior (multiple contexts) in the text ``I have a gun and feel pretty bad about my life, and it wouldn't be the worst thing if I didn't wake up tomorrow''. Domain specificity in self-attention architectures is handled by fine-tuning on excerpts from relevant domain specific resources (datasets and external knowledge - medical textbook chapters on mental health diagnosis related to suicide and depression). We propose a modified self-attention architecture Knowledge-infused Self Attention Transformer (KSAT) that achieves the integration of multiple domain-specific contexts through the use of external knowledge sources. KSAT introduces knowledge-guided biases in dedicated self-attention layers for each knowledge source to accomplish this. In addition, KSAT provides mechanics for controlling the trade-off between learning from data and learning from knowledge. Our quantitative and qualitative evaluations show that (1) the KSAT architecture provides novel human-understandable ways to precisely measure and visualize the contributions of the infused domain contexts, and (2) KSAT performs competitively with other knowledge-infused baselines and significantly outperforms baselines that use fine-tuning for domain-specific tasks.