 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadSNN: Backdoor Attacks on Spiking Neural Networks via Adversarial Spiking Neuron
Feb 06, 2026Spiking Neural Networks (SNNs) are energy-efficient counterparts of Deep Neural Networks (DNNs) with high biological plausibility, as information is transmitted through temporal spiking patterns. The core element of an SNN is the spiking neuron, which converts input data into spikes following the Leaky Integrate-and-Fire (LIF) neuron model. This model includes several important hyperparameters, such as the membrane potential threshold and membrane time constant. Both the DNNs and SNNs have proven to be exploitable by backdoor attacks, where an adversary can poison the training dataset with malicious triggers and force the model to behave in an attacker-defined manner. Yet, how an adversary can exploit the unique characteristics of SNNs for backdoor attacks remains underexplored. In this paper, we propose \textit{BadSNN}, a novel backdoor attack on spiking neural networks that exploits hyperparameter variations of spiking neurons to inject backdoor behavior into the model. We further propose a trigger optimization process to achieve better attack performance while making trigger patterns less perceptible. \textit{BadSNN} demonstrates superior attack performance on various datasets and architectures, as well as compared with state-of-the-art data poisoning-based backdoor attacks and robustness against common backdoor mitigation techniques. Codes can be found at https://github.com/SiSL-URI/BadSNN.
Multi-Targeted Graph Backdoor Attack
Jan 21, 2026Graph neural network (GNN) have demonstrated exceptional performance in solving critical problems across diverse domains yet remain susceptible to backdoor attacks. Existing studies on backdoor attack for graph classification are limited to single target attack using subgraph replacement based mechanism where the attacker implants only one trigger into the GNN model. In this paper, we introduce the first multi-targeted backdoor attack for graph classification task, where multiple triggers simultaneously redirect predictions to different target labels. Instead of subgraph replacement, we propose subgraph injection which preserves the structure of the original graphs while poisoning the clean graphs. Extensive experiments demonstrate the efficacy of our approach, where our attack achieves high attack success rates for all target labels with minimal impact on the clean accuracy. Experimental results on five dataset demonstrate the superior performance of our attack framework compared to the conventional subgraph replacement-based attack. Our analysis on four GNN models confirms the generalization capability of our attack which is effective regardless of the GNN model architectures and training parameters settings. We further investigate the impact of the attack design parameters including injection methods, number of connections, trigger sizes, trigger edge density and poisoning ratios. Additionally, our evaluation against state-of-the-art defenses (randomized smoothing and fine-pruning) demonstrates the robustness of our proposed multi-target attacks. This work highlights the GNN vulnerability against multi-targeted backdoor attack in graph classification task. Our source codes will be available at https://github.com/SiSL-URI/Multi-Targeted-Graph-Backdoor-Attack.
Exploiting the Vulnerability of Large Language Models via Defense-Aware Architectural Backdoor
Sep 03, 2024Deep neural networks (DNNs) have long been recognized as vulnerable to backdoor attacks. By providing poisoned training data in the fine-tuning process, the attacker can implant a backdoor into the victim model. This enables input samples meeting specific textual trigger patterns to be classified as target labels of the attacker's choice. While such black-box attacks have been well explored in both computer vision and natural language processing (NLP), backdoor attacks relying on white-box attack philosophy have hardly been thoroughly investigated. In this paper, we take the first step to introduce a new type of backdoor attack that conceals itself within the underlying model architecture. Specifically, we pcricKet1996!ropose to design separate backdoor modules consisting of two functions: trigger detection and noise injection. The add-on modules of model architecture layers can detect the presence of input trigger tokens and modify layer weights using Gaussian noise to disturb the feature distribution of the baseline model. We conduct extensive experiments to evaluate our attack methods using two model architecture settings on five different large language datasets. We demonstrate that the training-free architectural backdoor on a large language model poses a genuine threat. Unlike the-state-of-art work, it can survive the rigorous fine-tuning and retraining process, as well as evade output probability-based defense methods (i.e. BDDR). All the code and data is available https://github.com/SiSL-URI/Arch_Backdoor_LLM.
NoiseAttack: An Evasive Sample-Specific Multi-Targeted Backdoor Attack Through White Gaussian Noise
Sep 03, 2024Backdoor attacks pose a significant threat when using third-party data for deep learning development. In these attacks, data can be manipulated to cause a trained model to behave improperly when a specific trigger pattern is applied, providing the adversary with unauthorized advantages. While most existing works focus on designing trigger patterns in both visible and invisible to poison the victim class, they typically result in a single targeted class upon the success of the backdoor attack, meaning that the victim class can only be converted to another class based on the adversary predefined value. In this paper, we address this issue by introducing a novel sample-specific multi-targeted backdoor attack, namely NoiseAttack. Specifically, we adopt White Gaussian Noise (WGN) with various Power Spectral Densities (PSD) as our underlying triggers, coupled with a unique training strategy to execute the backdoor attack. This work is the first of its kind to launch a vision backdoor attack with the intent to generate multiple targeted classes with minimal input configuration. Furthermore, our extensive experimental results demonstrate that NoiseAttack can achieve a high attack success rate against popular network architectures and datasets, as well as bypass state-of-the-art backdoor detection methods. Our source code and experiments are available at https://github.com/SiSL-URI/NoiseAttack/tree/main.
Entropy-Based Modeling for Estimating Soft Errors Impact on Binarized Neural Network Inference
Apr 21, 2020
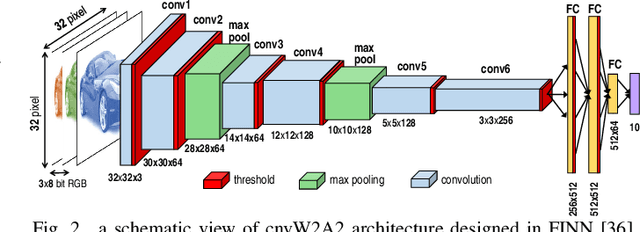
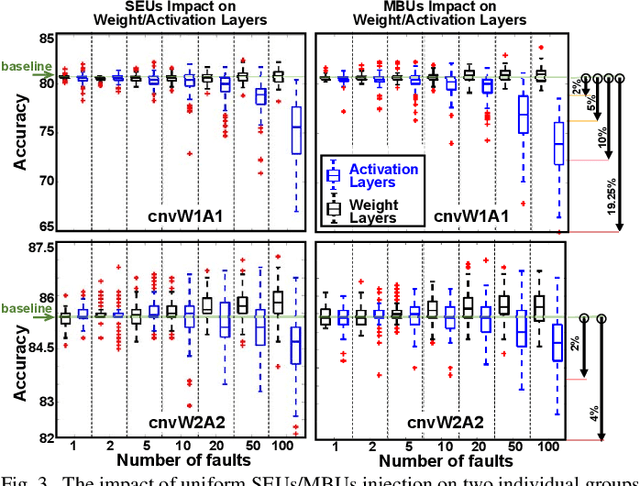
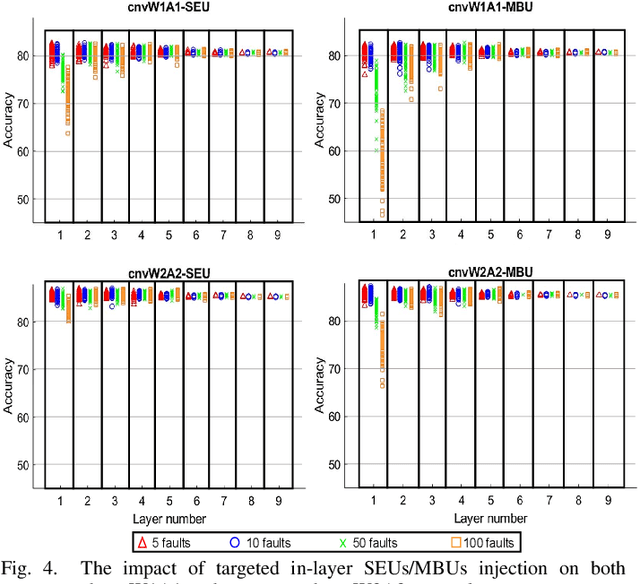
Over past years, the easy accessibility to the large scale datasets has significantly shifted the paradigm for developing highly accurate prediction models that are driven from Neural Network (NN). These models can be potentially impacted by the radiation-induced transient faults that might lead to the gradual downgrade of the long-running expected NN inference accelerator. The crucial observation from our rigorous vulnerability assessment on the NN inference accelerator demonstrates that the weights and activation functions are unevenly susceptible to both single-event upset (SEU) and multi-bit upset (MBU), especially in the first five layers of our selected convolution neural network. In this paper, we present the relatively-accurate statistical models to delineate the impact of both undertaken SEU and MBU across layers and per each layer of the selected NN. These models can be used for evaluating the error-resiliency magnitude of NN topology before adopting them in the safety-critical applications.
A Survey on Impact of Transient Faults on BNN Inference Accelerators
Apr 10, 2020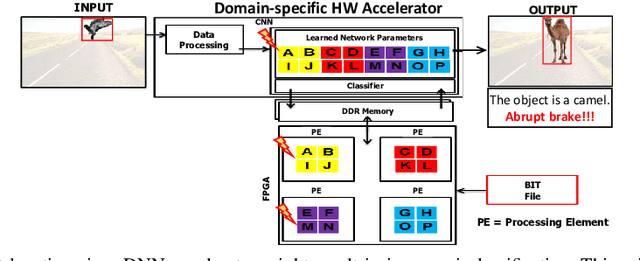
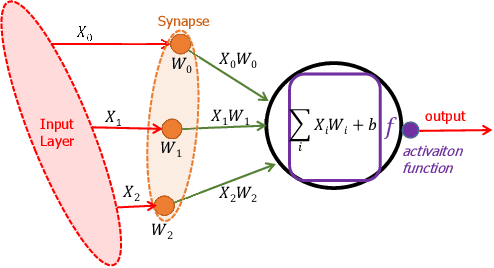
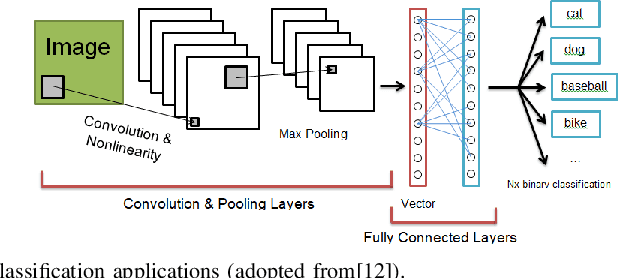

Over past years, the philosophy for designing the artificial intelligence algorithms has significantly shifted towards automatically extracting the composable systems from massive data volumes. This paradigm shift has been expedited by the big data booming which enables us to easily access and analyze the highly large data sets. The most well-known class of big data analysis techniques is called deep learning. These models require significant computation power and extremely high memory accesses which necessitate the design of novel approaches to reduce the memory access and improve power efficiency while taking into account the development of domain-specific hardware accelerators to support the current and future data sizes and model structures.The current trends for designing application-specific integrated circuits barely consider the essential requirement for maintaining the complex neural network computation to be resilient in the presence of soft errors. The soft errors might strike either memory storage or combinational logic in the hardware accelerator that can affect the architectural behavior such that the precision of the results fall behind the minimum allowable correctness. In this study, we demonstrate that the impact of soft errors on a customized deep learning algorithm called Binarized Neural Network might cause drastic image misclassification. Our experimental results show that the accuracy of image classifier can drastically drop by 76.70% and 19.25% in lfcW1A1 and cnvW1A1 networks,respectively across CIFAR-10 and MNIST datasets during the fault injection for the worst-case scenarios