 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPIMA: Optical Processing-In-Memory for Convolutional Neural Network Acceleration
Jul 11, 2024



Recent advances in machine learning (ML) have spotlighted the pressing need for computing architectures that bridge the gap between memory bandwidth and processing power. The advent of deep neural networks has pushed traditional Von Neumann architectures to their limits due to the high latency and energy consumption costs associated with data movement between the processor and memory for these workloads. One of the solutions to overcome this bottleneck is to perform computation within the main memory through processing-in-memory (PIM), thereby limiting data movement and the costs associated with it. However, DRAM-based PIM struggles to achieve high throughput and energy efficiency due to internal data movement bottlenecks and the need for frequent refresh operations. In this work, we introduce OPIMA, a PIM-based ML accelerator, architected within an optical main memory. OPIMA has been designed to leverage the inherent massive parallelism within main memory while performing high-speed, low-energy optical computation to accelerate ML models based on convolutional neural networks. We present a comprehensive analysis of OPIMA to guide design choices and operational mechanisms. Additionally, we evaluate the performance and energy consumption of OPIMA, comparing it with conventional electronic computing systems and emerging photonic PIM architectures. The experimental results show that OPIMA can achieve 2.98x higher throughput and 137x better energy efficiency than the best-known prior work.
Analysis of Optical Loss and Crosstalk Noise in MZI-based Coherent Photonic Neural Networks
Aug 07, 2023



With the continuous increase in the size and complexity of machine learning models, the need for specialized hardware to efficiently run such models is rapidly growing. To address such a need, silicon-photonic-based neural network (SP-NN) accelerators have recently emerged as a promising alternative to electronic accelerators due to their lower latency and higher energy efficiency. Not only can SP-NNs alleviate the fan-in and fan-out problem with linear algebra processors, their operational bandwidth can match that of the photodetection rate (typically 100 GHz), which is at least over an order of magnitude faster than electronic counterparts that are restricted to a clock rate of a few GHz. Unfortunately, the underlying silicon photonic devices in SP-NNs suffer from inherent optical losses and crosstalk noise originating from fabrication imperfections and undesired optical couplings, the impact of which accumulates as the network scales up. Consequently, the inferencing accuracy in an SP-NN can be affected by such inefficiencies -- e.g., can drop to below 10% -- the impact of which is yet to be fully studied. In this paper, we comprehensively model the optical loss and crosstalk noise using a bottom-up approach, from the device to the system level, in coherent SP-NNs built using Mach-Zehnder interferometer (MZI) devices. The proposed models can be applied to any SP-NN architecture with different configurations to analyze the effect of loss and crosstalk. Such an analysis is important where there are inferencing accuracy and scalability requirements to meet when designing an SP-NN. Using the proposed analytical framework, we show a high power penalty and a catastrophic inferencing accuracy drop of up to 84% for SP-NNs of different scales with three known MZI mesh configurations (i.e., Reck, Clements, and Diamond) due to accumulated optical loss and crosstalk noise.
GHOST: A Graph Neural Network Accelerator using Silicon Photonics
Jul 04, 2023



Graph neural networks (GNNs) have emerged as a powerful approach for modelling and learning from graph-structured data. Multiple fields have since benefitted enormously from the capabilities of GNNs, such as recommendation systems, social network analysis, drug discovery, and robotics. However, accelerating and efficiently processing GNNs require a unique approach that goes beyond conventional artificial neural network accelerators, due to the substantial computational and memory requirements of GNNs. The slowdown of scaling in CMOS platforms also motivates a search for alternative implementation substrates. In this paper, we present GHOST, the first silicon-photonic hardware accelerator for GNNs. GHOST efficiently alleviates the costs associated with both vertex-centric and edge-centric operations. It implements separately the three main stages involved in running GNNs in the optical domain, allowing it to be used for the inference of various widely used GNN models and architectures, such as graph convolution networks and graph attention networks. Our simulation studies indicate that GHOST exhibits at least 10.2x better throughput and 3.8x better energy efficiency when compared to GPU, TPU, CPU and multiple state-of-the-art GNN hardware accelerators.
Characterization and Optimization of Integrated Silicon-Photonic Neural Networks under Fabrication-Process Variations
Apr 19, 2022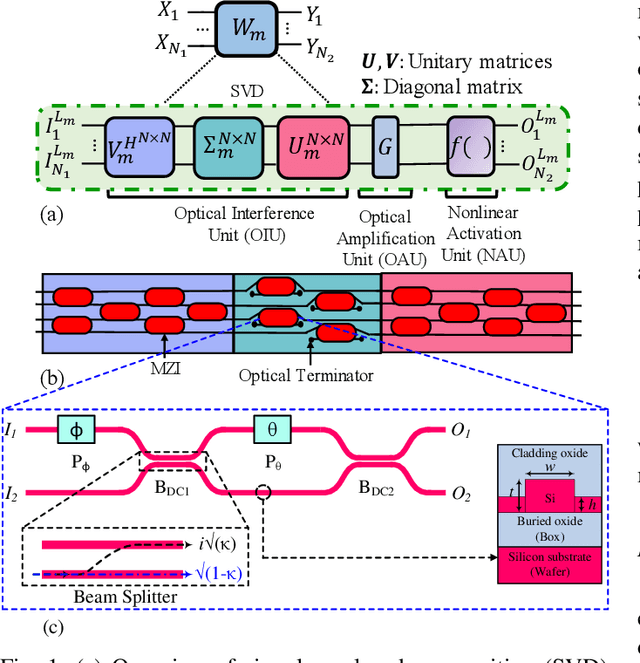

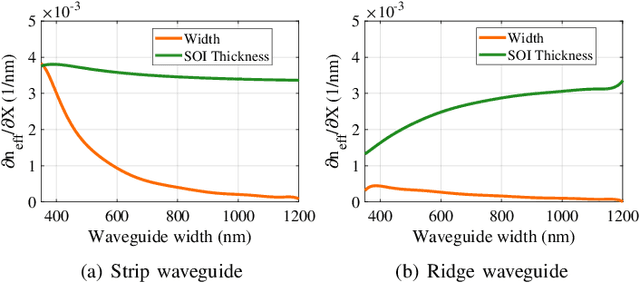

Silicon-photonic neural networks (SPNNs) have emerged as promising successors to electronic artificial intelligence (AI) accelerators by offering orders of magnitude lower latency and higher energy efficiency. Nevertheless, the underlying silicon photonic devices in SPNNs are sensitive to inevitable fabrication-process variations (FPVs) stemming from optical lithography imperfections. Consequently, the inferencing accuracy in an SPNN can be highly impacted by FPVs -- e.g., can drop to below 10% -- the impact of which is yet to be fully studied. In this paper, we, for the first time, model and explore the impact of FPVs in the waveguide width and silicon-on-insulator (SOI) thickness in coherent SPNNs that use Mach-Zehnder Interferometers (MZIs). Leveraging such models, we propose a novel variation-aware, design-time optimization solution to improve MZI tolerance to different FPVs in SPNNs. Simulation results for two example SPNNs of different scales under realistic and correlated FPVs indicate that the optimized MZIs can improve the inferencing accuracy by up to 93.95% for the MNIST handwritten digit dataset -- considered as an example in this paper -- which corresponds to a <0.5% accuracy loss compared to the variation-free case. The proposed one-time optimization method imposes low area overhead, and hence is applicable even to resource-constrained designs
LoCI: An Analysis of the Impact of Optical Loss and Crosstalk Noise in Integrated Silicon-Photonic Neural Networks
Apr 08, 2022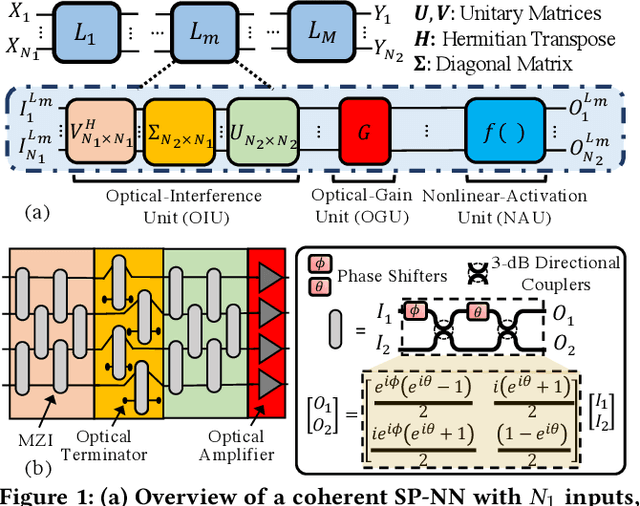
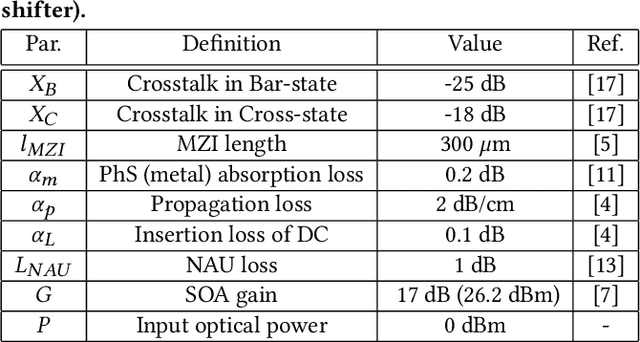
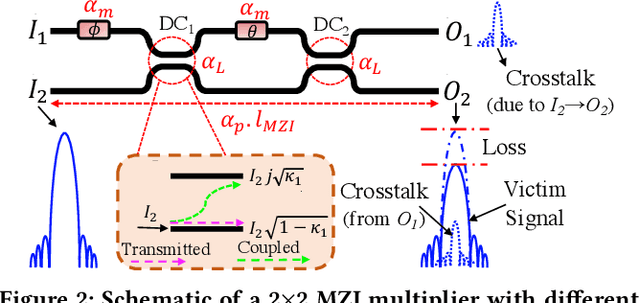
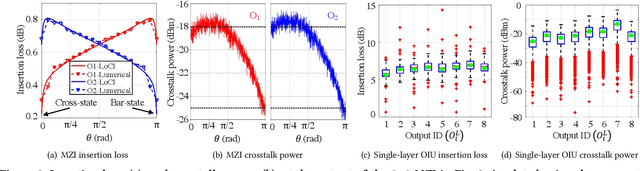
Compared to electronic accelerators, integrated silicon-photonic neural networks (SP-NNs) promise higher speed and energy efficiency for emerging artificial-intelligence applications. However, a hitherto overlooked problem in SP-NNs is that the underlying silicon photonic devices suffer from intrinsic optical loss and crosstalk noise, the impact of which accumulates as the network scales up. Leveraging precise device-level models, this paper presents the first comprehensive and systematic optical loss and crosstalk modeling framework for SP-NNs. For an SP-NN case study with two hidden layers and 1380 tunable parameters, we show a catastrophic 84% drop in inferencing accuracy due to optical loss and crosstalk noise.