 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterization and Optimization of Integrated Silicon-Photonic Neural Networks under Fabrication-Process Variations
Apr 19, 2022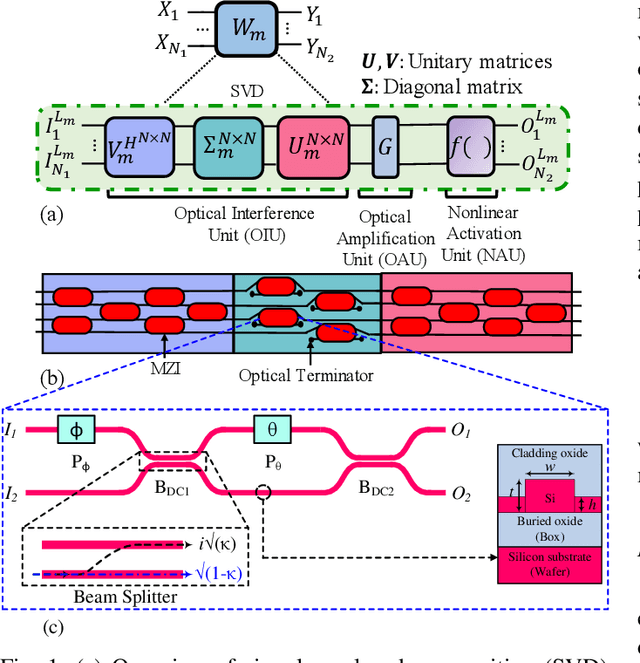

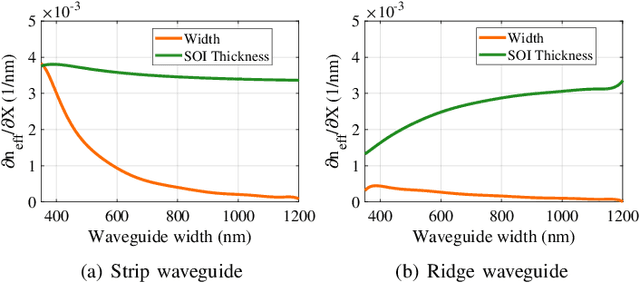

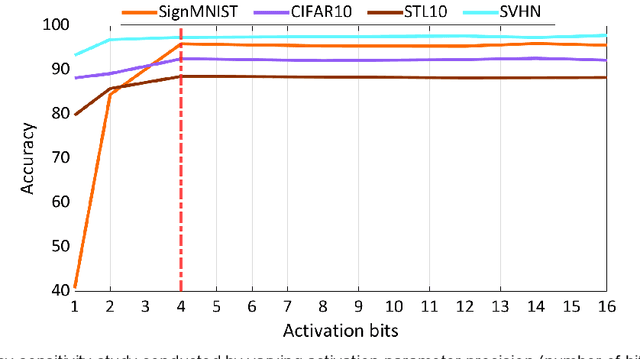
Silicon-photonic neural networks (SPNNs) have emerged as promising successors to electronic artificial intelligence (AI) accelerators by offering orders of magnitude lower latency and higher energy efficiency. Nevertheless, the underlying silicon photonic devices in SPNNs are sensitive to inevitable fabrication-process variations (FPVs) stemming from optical lithography imperfections. Consequently, the inferencing accuracy in an SPNN can be highly impacted by FPVs -- e.g., can drop to below 10% -- the impact of which is yet to be fully studied. In this paper, we, for the first time, model and explore the impact of FPVs in the waveguide width and silicon-on-insulator (SOI) thickness in coherent SPNNs that use Mach-Zehnder Interferometers (MZIs). Leveraging such models, we propose a novel variation-aware, design-time optimization solution to improve MZI tolerance to different FPVs in SPNNs. Simulation results for two example SPNNs of different scales under realistic and correlated FPVs indicate that the optimized MZIs can improve the inferencing accuracy by up to 93.95% for the MNIST handwritten digit dataset -- considered as an example in this paper -- which corresponds to a <0.5% accuracy loss compared to the variation-free case. The proposed one-time optimization method imposes low area overhead, and hence is applicable even to resource-constrained designs
ROBIN: A Robust Optical Binary Neural Network Accelerator
Jul 12, 2021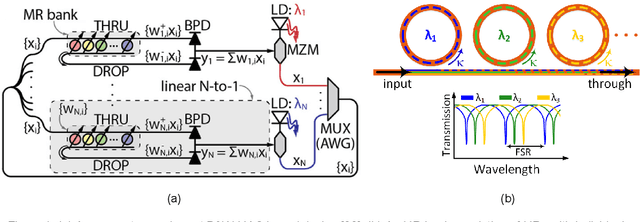

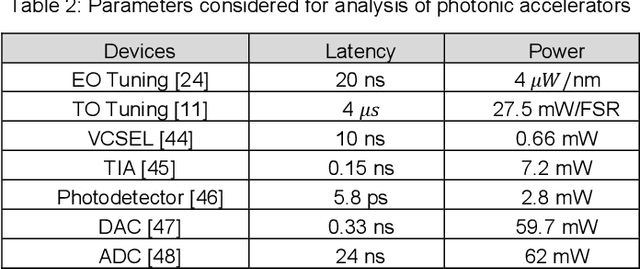
Domain specific neural network accelerators have garnered attention because of their improved energy efficiency and inference performance compared to CPUs and GPUs. Such accelerators are thus well suited for resource-constrained embedded systems. However, mapping sophisticated neural network models on these accelerators still entails significant energy and memory consumption, along with high inference time overhead. Binarized neural networks (BNNs), which utilize single-bit weights, represent an efficient way to implement and deploy neural network models on accelerators. In this paper, we present a novel optical-domain BNN accelerator, named ROBIN, which intelligently integrates heterogeneous microring resonator optical devices with complementary capabilities to efficiently implement the key functionalities in BNNs. We perform detailed fabrication-process variation analyses at the optical device level, explore efficient corrective tuning for these devices, and integrate circuit-level optimization to counter thermal variations. As a result, our proposed ROBIN architecture possesses the desirable traits of being robust, energy-efficient, low latency, and high throughput, when executing BNN models. Our analysis shows that ROBIN can outperform the best-known optical BNN accelerators and also many electronic accelerators. Specifically, our energy-efficient ROBIN design exhibits energy-per-bit values that are ~4x lower than electronic BNN accelerators and ~933x lower than a recently proposed photonic BNN accelerator, while a performance-efficient ROBIN design shows ~3x and ~25x better performance than electronic and photonic BNN accelerators, respectively.
CrossLight: A Cross-Layer Optimized Silicon Photonic Neural Network Accelerator
Feb 13, 2021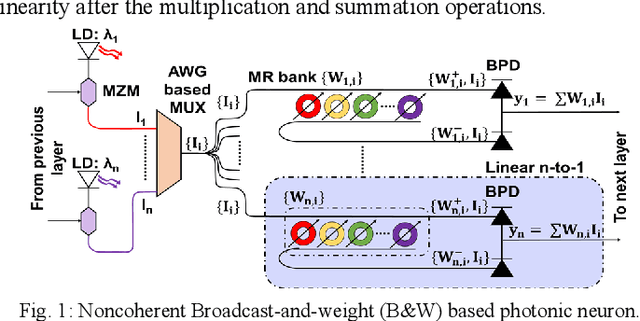
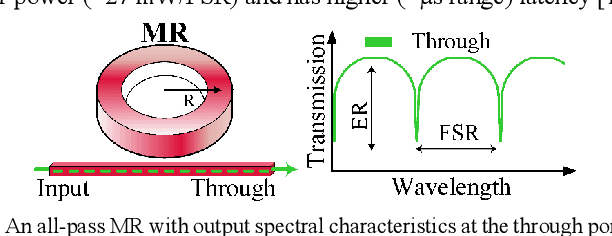
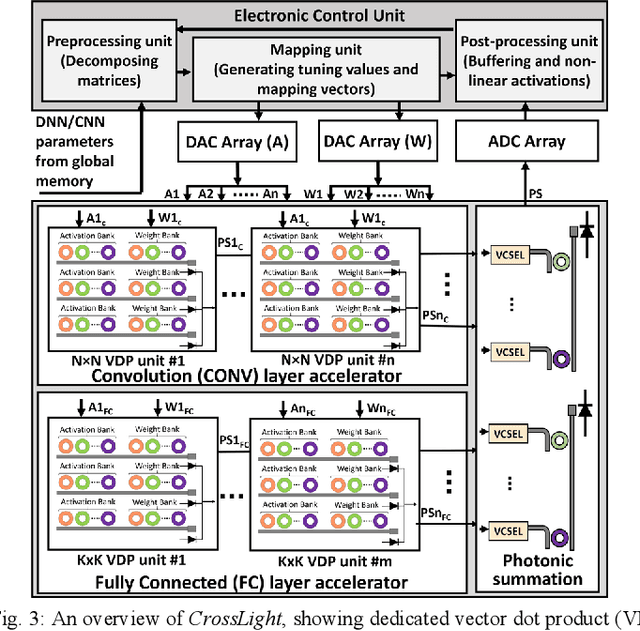
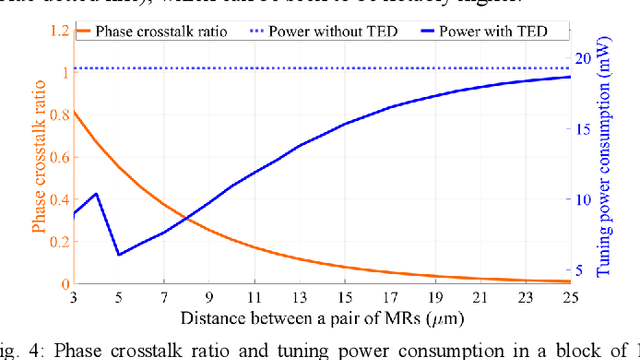
Domain-specific neural network accelerators have seen growing interest in recent years due to their improved energy efficiency and inference performance compared to CPUs and GPUs. In this paper, we propose a novel cross-layer optimized neural network accelerator called CrossLight that leverages silicon photonics. CrossLight includes device-level engineering for resilience to process variations and thermal crosstalk, circuit-level tuning enhancements for inference latency reduction, and architecture-level optimization to enable higher resolution, better energy-efficiency, and improved throughput. On average, CrossLight offers 9.5x lower energy-per-bit and 15.9x higher performance-per-watt at 16-bit resolution than state-of-the-art photonic deep learning accelerators.