 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARMOR: Adaptive Resilience Against Model Poisoning Attacks in Continual Federated Learning for Mobile Indoor Localization
Mar 20, 2026Indoor localization has become increasingly essential for applications ranging from asset tracking to delivering personalized services. Federated learning (FL) offers a privacy-preserving approach by training a centralized global model (GM) using distributed data from mobile devices without sharing raw data. However, real-world deployments require a continual federated learning (CFL) setting, where the GM receives continual updates under device heterogeneity and evolving indoor environments. In such dynamic conditions, erroneous or biased updates can cause the GM to deviate from its expected learning trajectory, gradually degrading internal GM representations and GM localization performance. This vulnerability is further exacerbated by adversarial model poisoning attacks. To address this challenge, we propose ARMOR, a novel CFL-based framework that monitors and safeguards the GM during continual updates. ARMOR introduces a novel state-space model (SSM) that learns the historical evolution of GM weight tensors and predicts the expected next state of weight tensors of the GM. By comparing incoming local updates with this SSM projection, ARMOR detects deviations and selectively mitigates corrupted updates before local updates are aggregated with the GM. This mechanism enables robust adaptation to temporal environmental dynamics and mitigate the effects of model poisoning attacks while preventing GM corruption. Experimental evaluations in real-world conditions indicate that ARMOR achieves notable improvements, with up to 8.0x reduction in mean error and 4.97x reduction in worst-case error compared to state-of-the-art indoor localization frameworks, demonstrating strong resilience against model corruption tested using real-world data and mobile devices.
Accelerating Diffusion Models for Generative AI Applications with Silicon Photonics
Mar 08, 2026Diffusion models have revolutionized generative AI, with their inherent capacity to generate highly realistic state-of-the-art synthetic data. However, these models employ an iterative denoising process over computationally intensive layers such as UNets and attention mechanisms. This results in high inference energy on conventional electronic platforms, and thus, there is an emerging need to accelerate these models in a sustainable manner. To address this challenge, we present a novel silicon photonics-based accelerator for diffusion models. Experimental evaluations demonstrate that our photonic accelerator achieves at least 3x better energy efficiency and 5.5x throughput improvement compared to state-of-the-art diffusion model accelerators.
DAILOC: Domain-Incremental Learning for Indoor Localization using Smartphones
Jun 18, 2025Wi-Fi fingerprinting-based indoor localization faces significant challenges in real-world deployments due to domain shifts arising from device heterogeneity and temporal variations within indoor environments. Existing approaches often address these issues independently, resulting in poor generalization and susceptibility to catastrophic forgetting over time. In this work, we propose DAILOC, a novel domain-incremental learning framework that jointly addresses both temporal and device-induced domain shifts. DAILOC introduces a novel disentanglement strategy that separates domain shifts from location-relevant features using a multi-level variational autoencoder. Additionally, we introduce a novel memory-guided class latent alignment mechanism to address the effects of catastrophic forgetting over time. Experiments across multiple smartphones, buildings, and time instances demonstrate that DAILOC significantly outperforms state-of-the-art methods, achieving up to 2.74x lower average error and 4.6x lower worst-case error.
Towards Explainable Indoor Localization: Interpreting Neural Network Learning on Wi-Fi Fingerprints Using Logic Gates
Jun 18, 2025Indoor localization using deep learning (DL) has demonstrated strong accuracy in mapping Wi-Fi RSS fingerprints to physical locations; however, most existing DL frameworks function as black-box models, offering limited insight into how predictions are made or how models respond to real-world noise over time. This lack of interpretability hampers our ability to understand the impact of temporal variations - caused by environmental dynamics - and to adapt models for long-term reliability. To address this, we introduce LogNet, a novel logic gate-based framework designed to interpret and enhance DL-based indoor localization. LogNet enables transparent reasoning by identifying which access points (APs) are most influential for each reference point (RP) and reveals how environmental noise disrupts DL-driven localization decisions. This interpretability allows us to trace and diagnose model failures and adapt DL systems for more stable long-term deployments. Evaluations across multiple real-world building floorplans and over two years of temporal variation show that LogNet not only interprets the internal behavior of DL models but also improves performance-achieving up to 1.1x to 2.8x lower localization error, 3.4x to 43.3x smaller model size, and 1.5x to 3.6x lower latency compared to prior DL-based models.
Sustainable Carbon-Aware and Water-Efficient LLM Scheduling in Geo-Distributed Cloud Datacenters
May 29, 2025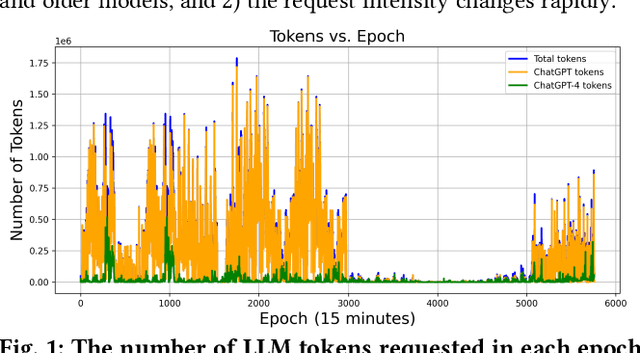
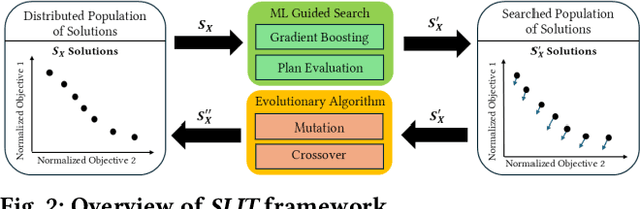
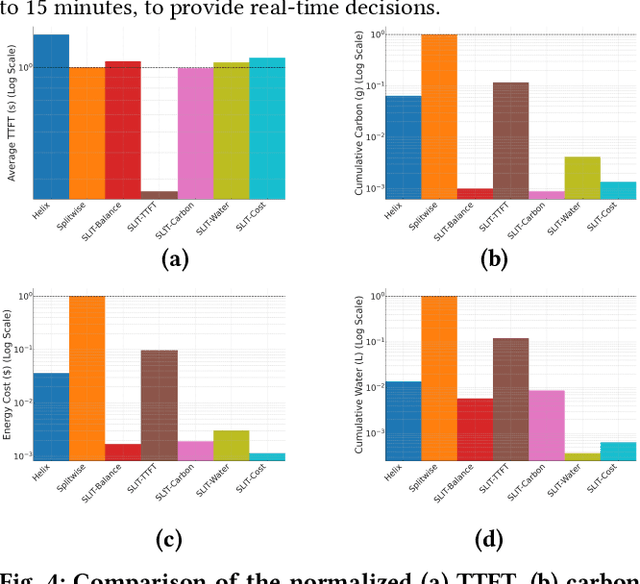
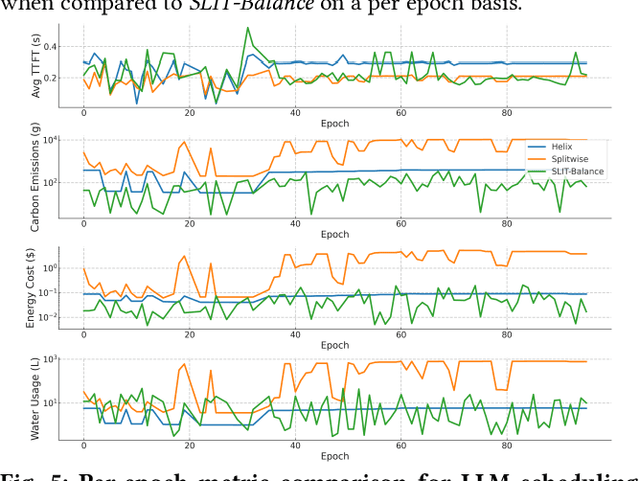
In recent years, Large Language Models (LLM) such as ChatGPT, CoPilot, and Gemini have been widely adopted in different areas. As the use of LLMs continues to grow, many efforts have focused on reducing the massive training overheads of these models. But it is the environmental impact of handling user requests to LLMs that is increasingly becoming a concern. Recent studies estimate that the costs of operating LLMs in their inference phase can exceed training costs by 25x per year. As LLMs are queried incessantly, the cumulative carbon footprint for the operational phase has been shown to far exceed the footprint during the training phase. Further, estimates indicate that 500 ml of fresh water is expended for every 20-50 requests to LLMs during inference. To address these important sustainability issues with LLMs, we propose a novel framework called SLIT to co-optimize LLM quality of service (time-to-first token), carbon emissions, water usage, and energy costs. The framework utilizes a machine learning (ML) based metaheuristic to enhance the sustainability of LLM hosting across geo-distributed cloud datacenters. Such a framework will become increasingly vital as LLMs proliferate.
PhotoGAN: Generative Adversarial Neural Network Acceleration with Silicon Photonics
Jan 23, 2025Generative Adversarial Networks (GANs) are at the forefront of AI innovation, driving advancements in areas such as image synthesis, medical imaging, and data augmentation. However, the unique computational operations within GANs, such as transposed convolutions and instance normalization, introduce significant inefficiencies when executed on traditional electronic accelerators, resulting in high energy consumption and suboptimal performance. To address these challenges, we introduce PhotoGAN, the first silicon-photonic accelerator designed to handle the specialized operations of GAN models. By leveraging the inherent high throughput and energy efficiency of silicon photonics, PhotoGAN offers an innovative, reconfigurable architecture capable of accelerating transposed convolutions and other GAN-specific layers. The accelerator also incorporates a sparse computation optimization technique to reduce redundant operations, improving computational efficiency. Our experimental results demonstrate that PhotoGAN achieves at least 4.4x higher GOPS and 2.18x lower energy-per-bit (EPB) compared to state-of-the-art accelerators, including GPUs and TPUs. These findings showcase PhotoGAN as a promising solution for the next generation of GAN acceleration, providing substantial gains in both performance and energy efficiency.
UPAQ: A Framework for Real-Time and Energy-Efficient 3D Object Detection in Autonomous Vehicles
Jan 08, 2025To enhance perception in autonomous vehicles (AVs), recent efforts are concentrating on 3D object detectors, which deliver more comprehensive predictions than traditional 2D object detectors, at the cost of increased memory footprint and computational resource usage. We present a novel framework called UPAQ, which leverages semi-structured pattern pruning and quantization to improve the efficiency of LiDAR point-cloud and camera-based 3D object detectors on resource-constrained embedded AV platforms. Experimental results on the Jetson Orin Nano embedded platform indicate that UPAQ achieves up to 5.62x and 5.13x model compression rates, up to 1.97x and 1.86x boost in inference speed, and up to 2.07x and 1.87x reduction in energy consumption compared to state-of-the-art model compression frameworks, on the Pointpillar and SMOKE models respectively.
SafeLight: Enhancing Security in Optical Convolutional Neural Network Accelerators
Nov 22, 2024



The rapid proliferation of deep learning has revolutionized computing hardware, driving innovations to improve computationally expensive multiply-and-accumulate operations in deep neural networks. Among these innovations are integrated silicon-photonic systems that have emerged as energy-efficient platforms capable of achieving light speed computation and communication, positioning optical neural network (ONN) platforms as a transformative technology for accelerating deep learning models such as convolutional neural networks (CNNs). However, the increasing complexity of optical hardware introduces new vulnerabilities, notably the risk of hardware trojan (HT) attacks. Despite the growing interest in ONN platforms, little attention has been given to how HT-induced threats can compromise performance and security. This paper presents an in-depth analysis of the impact of such attacks on the performance of CNN models accelerated by ONN accelerators. Specifically, we show how HTs can compromise microring resonators (MRs) in a state-of-the-art non-coherent ONN accelerator and reduce classification accuracy across CNN models by up to 7.49% to 80.46% by just targeting 10% of MRs. We then propose techniques to enhance ONN accelerator robustness against these attacks and show how the best techniques can effectively recover the accuracy drops.
SAFELOC: Overcoming Data Poisoning Attacks in Heterogeneous Federated Machine Learning for Indoor Localization
Nov 13, 2024
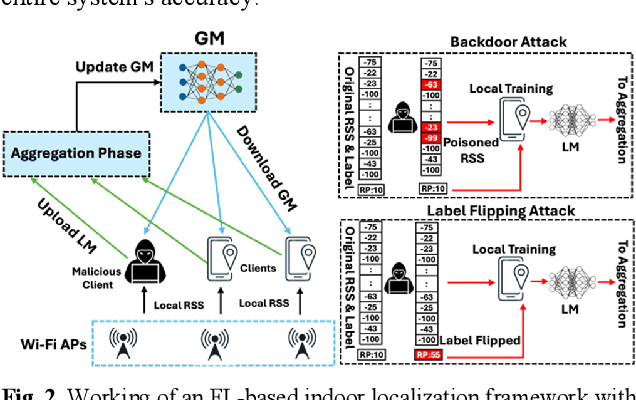
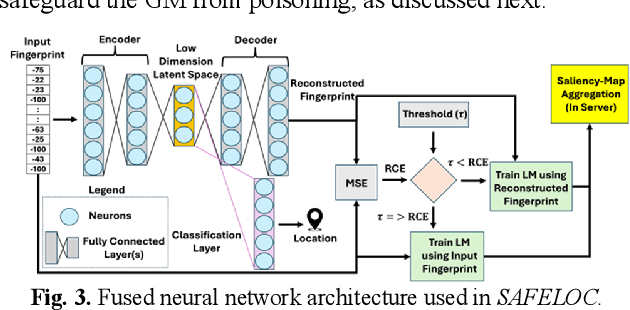
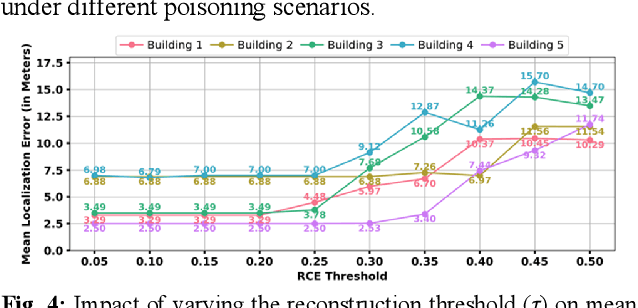
Machine learning (ML) based indoor localization solutions are critical for many emerging applications, yet their efficacy is often compromised by hardware/software variations across mobile devices (i.e., device heterogeneity) and the threat of ML data poisoning attacks. Conventional methods aimed at countering these challenges show limited resilience to the uncertainties created by these phenomena. In response, in this paper, we introduce SAFELOC, a novel framework that not only minimizes localization errors under these challenging conditions but also ensures model compactness for efficient mobile device deployment. Our framework targets a distributed and co-operative learning environment that uses federated learning (FL) to preserve user data privacy and assumes heterogeneous mobile devices carried by users (just like in most real-world scenarios). Within this heterogeneous FL context, SAFELOC introduces a novel fused neural network architecture that performs data poisoning detection and localization, with a low model footprint. Additionally, a dynamic saliency map-based aggregation strategy is designed to adapt based on the severity of the detected data poisoning scenario. Experimental evaluations demonstrate that SAFELOC achieves improvements of up to 5.9x in mean localization error, 7.8x in worst-case localization error, and a 2.1x reduction in model inference latency compared to state-of-the-art indoor localization frameworks, across diverse building floorplans, mobile devices, and ML data poisoning attack scenarios.
A Framework for SLO, Carbon, and Wastewater-Aware Sustainable FaaS Cloud Platform Management
Oct 09, 2024


Function-as-a-Service (FaaS) is a growing cloud computing paradigm that is expected to reduce the user cost of service over traditional serverful approaches. However, the environmental impact of FaaS has not received much attention. We investigate FaaS scheduling and scaling from a sustainability perspective in this work. We find that the service-level objectives (SLOs) of FaaS and carbon emissions conflict with each other. We also find that SLO-focused FaaS scheduling can exacerbate water use in a datacenter. We propose a novel sustainability-focused FaaS scheduling and scaling framework to co-optimize SLO performance, carbon emissions, and wastewater generation.