 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-dimension Transformer with Attention-based Filtering for Medical Image Segmentation
May 20, 2024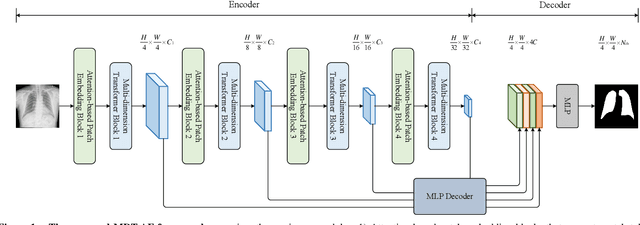
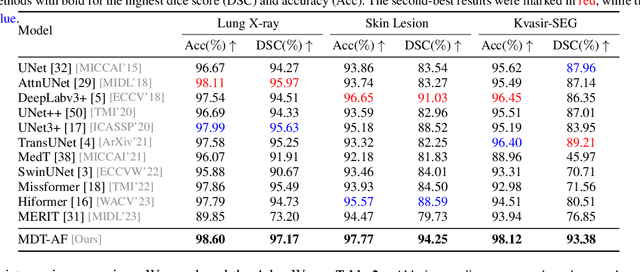
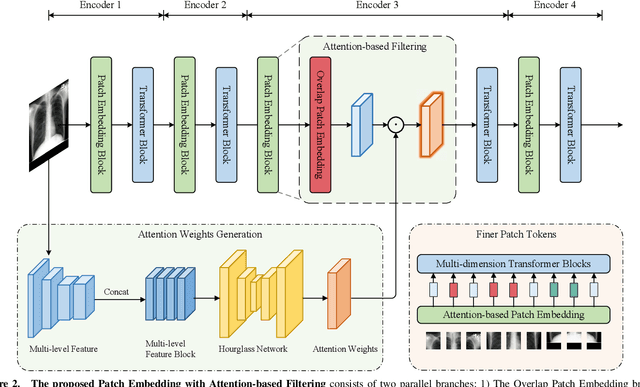
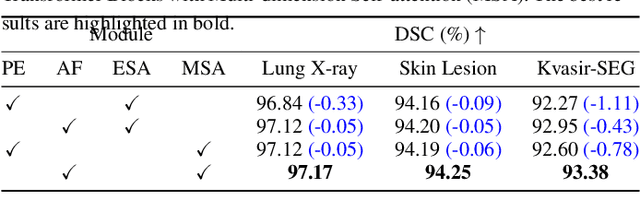
The accurate segmentation of medical images is crucial for diagnosing and treating diseases. Recent studies demonstrate that vision transformer-based methods have significantly improved performance in medical image segmentation, primarily due to their superior ability to establish global relationships among features and adaptability to various inputs. However, these methods struggle with the low signal-to-noise ratio inherent to medical images. Additionally, the effective utilization of channel and spatial information, which are essential for medical image segmentation, is limited by the representation capacity of self-attention. To address these challenges, we propose a multi-dimension transformer with attention-based filtering (MDT-AF), which redesigns the patch embedding and self-attention mechanism for medical image segmentation. MDT-AF incorporates an attention-based feature filtering mechanism into the patch embedding blocks and employs a coarse-to-fine process to mitigate the impact of low signal-to-noise ratio. To better capture complex structures in medical images, MDT-AF extends the self-attention mechanism to incorporate spatial and channel dimensions, enriching feature representation. Moreover, we introduce an interaction mechanism to improve the feature aggregation between spatial and channel dimensions. Experimental results on three public medical image segmentation benchmarks show that MDT-AF achieves state-of-the-art (SOTA) performance.
DeepArt: A Benchmark to Advance Fidelity Research in AI-Generated Content
Dec 24, 2023This paper explores the image synthesis capabilities of GPT-4, a leading multi-modal large language model. We establish a benchmark for evaluating the fidelity of texture features in images generated by GPT-4, comprising manually painted pictures and their AI-generated counterparts. The contributions of this study are threefold: First, we provide an in-depth analysis of the fidelity of image synthesis features based on GPT-4, marking the first such study on this state-of-the-art model. Second, the quantitative and qualitative experiments fully reveals the limitations of the GPT-4 model in image synthesis. Third, we have compiled a unique benchmark of manual drawings and corresponding GPT-4-generated images, introducing a new task to advance fidelity research in AI-generated content (AIGC). The dataset is available at: \url{https://github.com/rickwang28574/DeepArt}.